难得一见,OpenAI开源大模型调测工具Transformer Debugger:可以在训练大模型之前理解模型的运行情况并干预
自从OpenAI转向盈利化运营之后,很少再开源自己的技术。但就在刚才,OpenAI开源了一个全新的大模型调测工具:Transformer Debugger。这个工具可以帮助开发者调测大模型的推理情况,帮助我们理解模型的输出并提供一定的解释支持。
为什么大语言模型难以调测和解释
Transformer Debugger工具简介
Transformer Debugger基本能力
神经元可视化(Neuron Viewer)
Transformer Debugger开源地址和其它资源
为什么大语言模型难以调测和解释
大语言模型需要大量的计算资源来训练,包含了数以千亿的参数。因为其复杂性和“黑盒”性质,使得模型内的决策过程变得难以理解。尽管近年来出现了一些解释AI模型的方法和工具,但对于非常大和复杂的模型,这些方法往往效果有限或者难以应用。
特别的,对于指定的prompt,为什么大语言模型会输出特定的内容这个问题,在当前是非常难以理解但却非常有价值。如果能理解大模型的输出是什么样的机制或者由哪些网络决定的,可以帮助我们进一步优化大模型的训练质量。
目前,业界非常缺少这样一个工具。而OpenAI刚刚开源的这个Transformer Debugger则以可视化的形式帮助我们理解语言模型的推理过程。
Transformer Debugger工具简介
Transformer Debugger(TDB)是OpenAI的超级对齐团队开源的一个可视化web工具,可以支持我们对“小的”语言模型的特定行为进行观察和干预。
OpenAI对TDB的解释如下:
TDB允许在编码之前快速地探索模型的工作原理,它能够介入模型的前向传播过程,让我们可以直观地看到某个特定操作如何影响模型的行为。例如,我们可以利用它来探讨“为什么面对同一个输入提示,模型会选择输出Token A而不是Token B?”或是“为什么在某个特定的输入下,某个注意力机制(Attention Head)会偏好于Token T?”TDB通过识别对模型行为有显著影响的特定组成部分(如神经元、注意力机制头部、自编码器的潜在表示等),并自动提供这些组成部分被激活的原因解释,以及它们之间的联系,来帮助我们发现和理解复杂的模型内部工作机制。
具体来说,Transformer Debugger提供如下能力。
Transformer Debugger基本能力
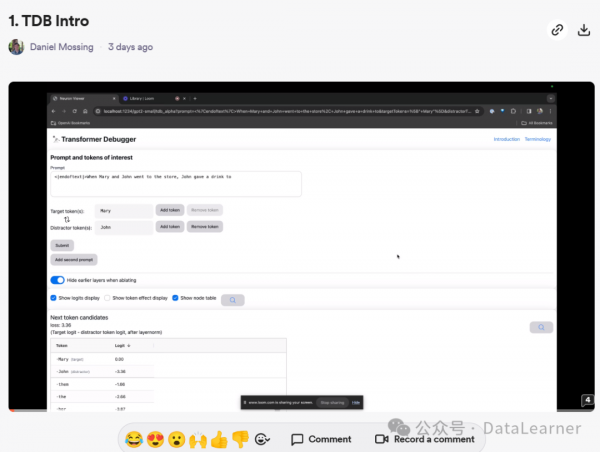
下图展示了Transformer Debugger对某个特定的prompt是如何展示结果的。
简单来说,当你输入某个prompt之后,模型会给出推理过程某个attention的结果,例如里面的attn_L9_9表示第9层的第9个attention的激活函数是0.67,以及它对后续输出的影响。如果你想看到具体的这个attention的作用,那么可以继续用下面的工具。
神经元可视化(Neuron Viewer)
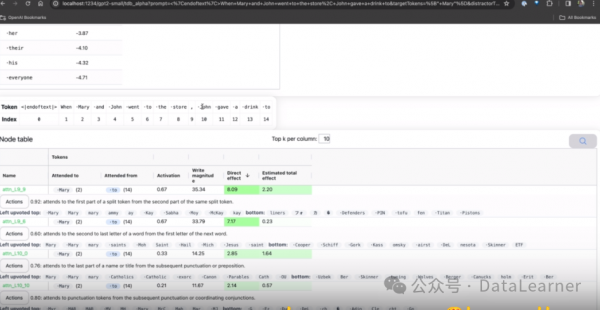
这个功能是一个React APP,可以展示单个模型组件信息,包括模型的神经元、attention heads和autoencoder latents。这个组件可以帮助我们看到某个具体的模型模块的结果。例如点击上面的attn_L9_9就能得到下面的界面。
如下图所示:
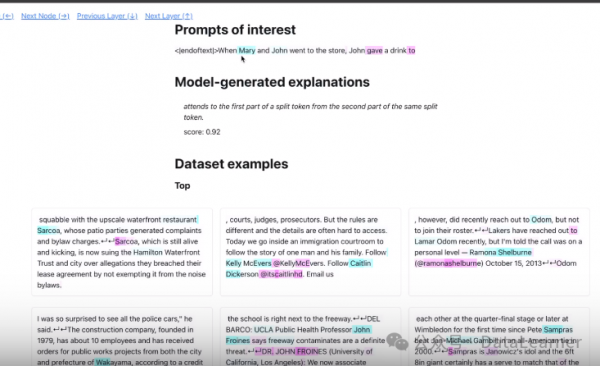
在这里,最上面的Prompt of interest是指输入的prompt,中间的Model-generated explantions是对当前选中单词的解释。这里的使用青色和品红色来表示不同的Token间的注意力关系和激活程度。亮青色代表一个Token接受了大量来自后续Token的注意力,而亮品红色代表后续Token接受了来自当前Token的重要信息。
总结一下,OpenAI Transformer Debugger的功能如下:
神经元观察器(Neuron viewer):这是一个基于React的应用程序,提供了关于各种语言模型组件的详细信息,包括多层感知器(MLP)神经元、注意力机制单元以及自编码器的隐藏特征向量。
激活服务器(Activation server):这是一个负责后台计算的服务器,它通过对特定的模型进行数据分析(推理),为TDB提供支持。此外,它还能从Azure的公共云存储服务中读取并提供数据。
模型库(Model):这是一个针对GPT-2模型及其自编码器的简化推理工具库,它包括了一些功能,可以捕捉到模型激活时的关键信息。
汇总激活数据集(Collated activation datasets):这部分数据集包含了触发MLP神经元、注意力机制单元和自编码器隐藏特征向量最强反应的数据示例,为模型分析提供重要参考。
Transformer Debugger开源地址和其它资源
Transformer Debugger的开源地址:https://github.com/openai/transformer-debugger
此外,Transformer Debugger工具使用了此前OpenAI做的大模型解释服务,这部分参考:OpenAI官方最新研究成果:如何用GPT-4这样的语言模型来解释语言模型中的神经元(neurons)
以及Anthropic的工作(如何通过稀疏自编码器(sparse autoencoder)从神经网络中提取出可解释的特征(features)):https://transformer-circuits.pub/2023/monosemantic-features
来源:DataLearner
好文章,需要你的鼓励


三祥科技拟1100万美元购入美国代顿厂房,汽车流体管路向液冷与悬架延伸
今天讲的出海案例是三祥科技,这家汽车流体管路厂商拟由北美子公司出资1100万美元,购买美国俄亥俄州代顿工业厂房。

NVIDIA联合多所顶尖高校打造的“全能机器人大脑“,凭一个模型干翻所有专家?
NVIDIA联合多所高校推出的Vesta,是一个把导航、定位、空间推理和长期规划全部统一进单一模型的通用机器人规划器,在多项基准上超越各领域专家模型,真实机器人任务成功率提升38.3%。

AI时代Chiplet设计中不可或缺的可观测性层
在基于Chiplet的架构中,可观测性正成为系统设计的关键缺失环节。多位半导体行业专家指出,AI可从硅层遥测数据中挖掘价值,但前提是架构须提供一致的检测手段、近传感器数据压缩及可编程采集能力。专家们强调,多供应商Chiplet生态系统需要标准化、安全的遥测模式,以实现跨芯片、封装和互联域的故障定位,同时保护敏感运营数据。目前,AI在遥测分析阶段已展现出显著价值,但可观测性的扩展本质上仍是架构问题。

斯坦福大学研究团队如何让AI“聪明地遗忘“,让超长文本处理效率提升3倍以上?
斯坦福大学提出SSA方法,通过插入"要点标记"让AI先做笔记再精读,在不改变模型架构的前提下将长文本推理效率提升3倍以上,同时在多项任务中超越传统压缩方法。
2024
03/12
19:04
分享
点赞