Mistral AI开源120亿参数的Mistral NeMo,Mistral 7B模型的继任者!免费开源!中文能力大幅增强!
本文原文来自DataLearnerAI官方网站:
https://www.datalearner.com/blog/1051721328234545
在人工智能领域,Mistral与NVIDIA的合作带来了一个引人注目的新型大模型——Mistral NeMo。这个拥有120亿参数的模型不仅性能卓越,还为AI的普及和应用创新铺平了道路。MistralAI官方博客介绍说该模型是此前开源的Mistral 7B模型的继承者,因此未来可能7B不会再继续演进了!

Mistral NeMo另一个最大的特点是大幅提高了多语言能力,特别是中文的支持大幅提高。虽然此前Mistral AI开源了很多模型,但是中文表现都很一般。而Mistral NeMo则在中文水平大幅提升。
-
Mistral NeMo简介
-
Mistral NeMo的评测结果
-
Mistral NeMo多语言支持包含中文!
-
Mistral NeMo技术简介
-
Mistral NeMo兼容此前的Mistral 7B模型
-
Mistral NeMo是完全开源的模型
Mistral NeMo简介
Mistral NeMo最令人瞩目的特点之一是其超长的上下文窗口,能够处理高达128k tokens的输入文本,这使得模型在理解复杂场景和长文本处理上具有显著优势,为多轮对话提供了更广阔的应用空间。
在同等规模的模型中,Mistral NeMo在推理能力、世界知识的掌握以及编程准确性方面都达到了顶尖水平,这使其在解决复杂问题和生成高质量代码等多种应用场景中表现出色。
Mistral NeMo的评测结果
下图是Mistral NeMo与其它模型评测结果的对比:
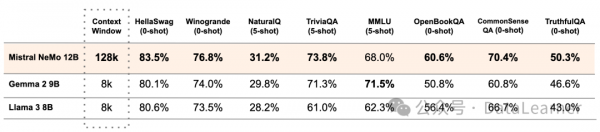
从上面可以看到,尽管综合理解能力(MMLU)上Mistral NeMo模型表现一般,但是在数学推理任务上表现很亮眼!
根据DataLearnerAI收集的大模型评测结果,新开源的Mistral NeMo模型在130亿参数规模的模型上评测非常优秀,MMLU评测得分第一。
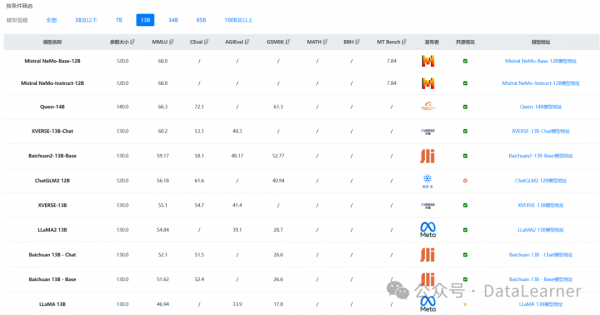
鉴于此前MistralAI开源的模型的良好口碑,这样的成绩下Mistral NeMo的能力非常值得期待。
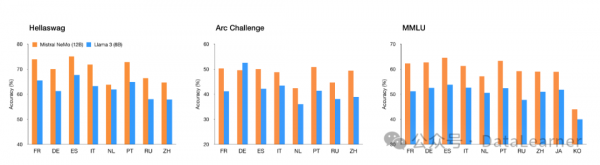
Mistral NeMo多语言支持包含中文!
此前MistralAI开源的Mixtral MoE以及Mixtral 7B都是不支持中文,或者中文非常弱。此次官方宣称对中文的支持说明这方面能力已经达到一定水平了。下图是Mistral NeMo在多语言上的评测结果,显著超过了Llama3-8B。
Mistral NeMo技术简介
尽管没有很详细的描述,但是官方还是透露了一些技术细节,Mistral NeMo采用了基于Tiktoken开发的新分词器Tekken,在多种自然语言和源代码的处理上表现卓越,其文本压缩效率比传统分词器高出约30%,显著提升了模型的效率和性能。
Mistral NeMo在遵循精确指令、推理、处理多轮对话和生成代码等方面都表现出显著进步,不仅能理解用户需求,还能更准确地完成各种复杂任务。
Mistral NeMo兼容此前的Mistral 7B模型
为了降低企业和开发者的门槛,Mistral采用了标准架构,可以轻松替代任何使用Mistral 7B的系统。模型权重已在HuggingFace上公开,并配有推理和微调工具,而NVIDIA则将其作为NIM推理微服务容器提供,进一步简化了部署和使用过程。
Mistral NeMo是完全开源的模型
Mistral选择开源友好策略,通过Apache 2.0许可证发布模型的预训练和指令微调检查点,极大推动了学术界和产业界对该模型的采用与创新。
Mistral NeMo模型的开源地址参考DataLearnerAI的模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/Mistral-NeMo-Base-12B
来源:DataLearner
好文章,需要你的鼓励


我如何整理散落在网络各处的数千张照片和视频
作者历经多年积累了大量照片和视频,分散存储在Google、Apple、Flickr、Dropbox、OneDrive五个云端及多个本地存储设备中。他通过"收集、整理、整合"三步法完成了清理:首先汇总所有存储位置的文件,然后删除模糊、重复及无意义的内容,最后统一迁移至Google Photos。借助去重工具大幅削减冗余文件,并遵循3-2-1备份原则,年订阅费用从近300美元降至60美元以下。

摩德纳大学团队揭秘:AI的“眼睛“和“大脑“为什么总是鸡同鸭讲,他们是怎么修好的?
这项研究提出HeRA方法,通过精准识别语言大模型中对齐最弱的注意力头并施加拓扑对比学习损失,有效提升多模态AI的视觉理解能力,同时抑制视觉幻觉,且不损害语言推理能力。

极端高温考验电网,电动校车“反向充电“成救星
上周北美热浪肆虐之际,电动汽车并未如批评者所担忧的那样加剧电网负担,反而通过V2G(车辆到电网)技术向电网反向输电。目前约230辆电动校车已可向电网提供8兆瓦时电力,足够约1600户家庭使用4小时。加州奥克兰统一学区的74辆电动校车每年可回馈约2.1吉瓦时清洁能源。随着规模扩大,V2G技术还有望降低用电峰值成本,并在自然灾害中为社区提供应急供电保障。

一个模型,随心切换延迟——英伟达与中研院联手打造的万能语音净化引擎
英伟达与台湾中研院提出一种实时通用语音增强框架,单模型支持30种延迟配置,通过并行卷积层和早退机制分别控制算法与计算延迟,性能接近专用模型。
2024
07/23
19:04
分享
点赞