
大模型场景下智算平台的设计与优化实践
智算平台面临着前所未有的挑战和机遇。通过技术创新和持续优化,可以有效提升智算平台在大模型场景下的性能和稳定性,推动AI技术的快速发展。
-
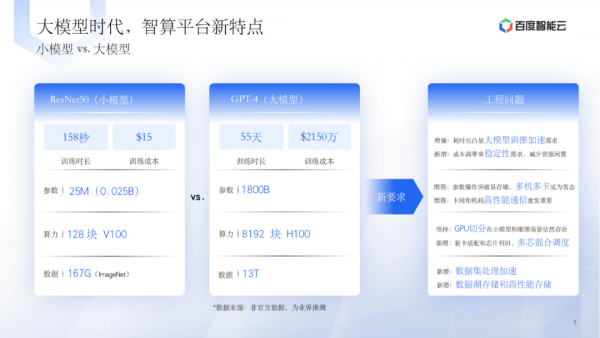
小模型与大模型的区别主要体现在训练时长、成本和工程问题上。 -
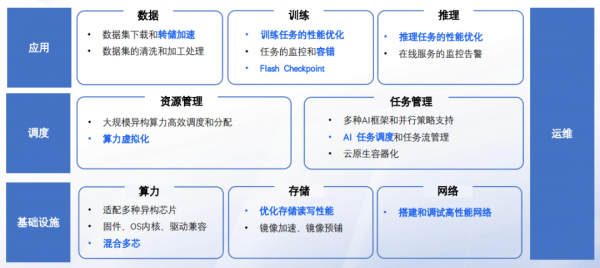
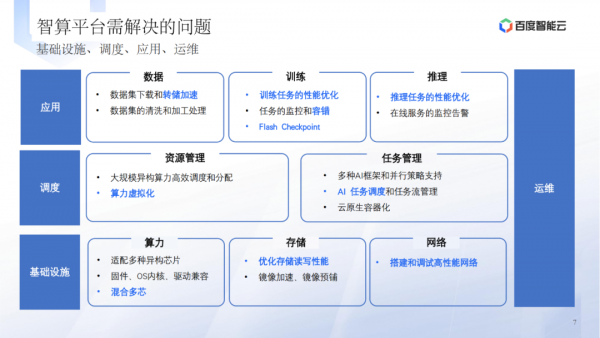
大模型时代的智算平台需要解决基础设施、调度、应用和运维等方面的问题。 -
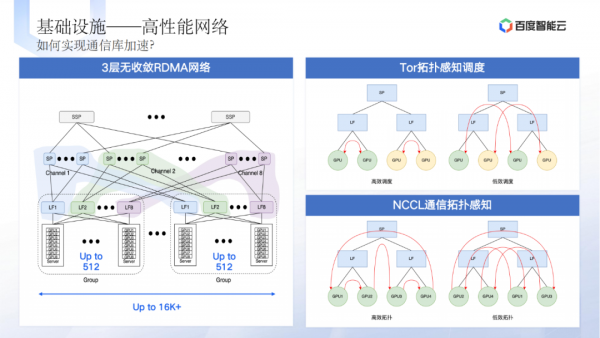
新的要求包括适配多种异构芯片、优化存储读写性能、高性能网络搭建等。
-
基础设施层面的问题包括适配多种异构芯片、固件和驱动兼容性等。 -
调度层的挑战涉及大规模异构算力的高效调度和分配。 -
应用层的需求包括训练和推理加速、训练容错等。 -
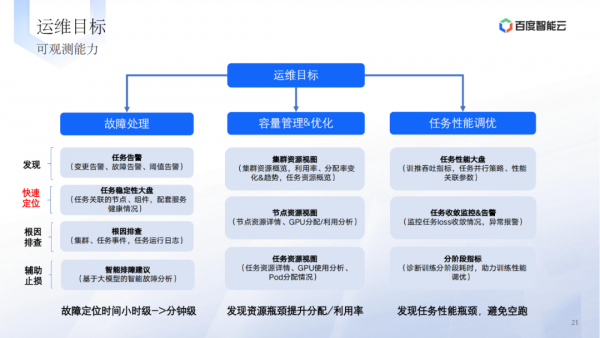
运维方面的目标是提高故障处理能力和容量管理效率。
-
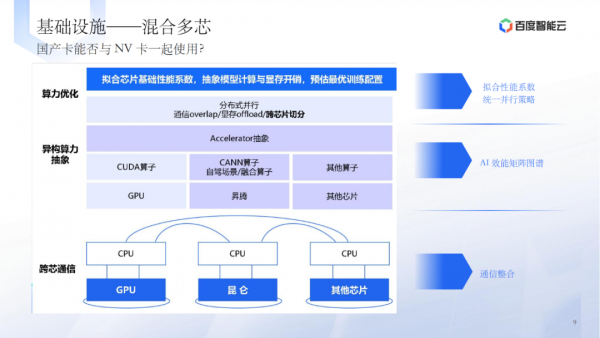
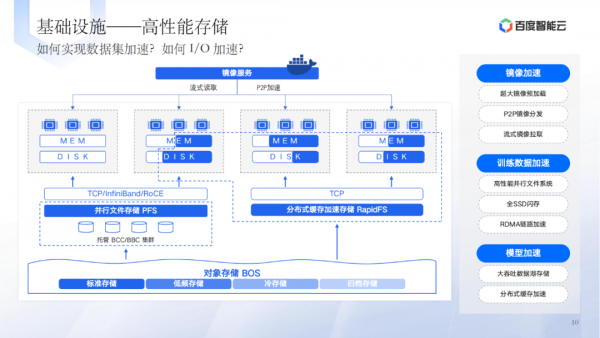
在基础设施层,讨论了国产卡与NV卡的兼容性、混合多芯的使用、高性能存储方案等。 -
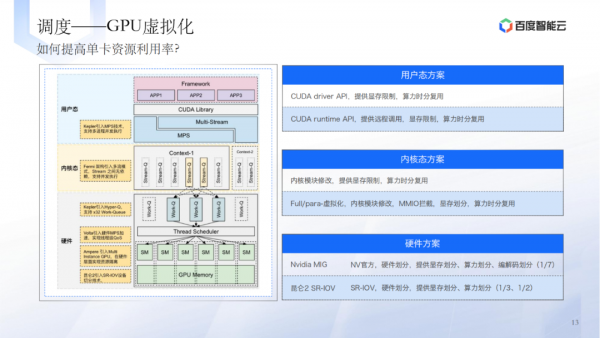
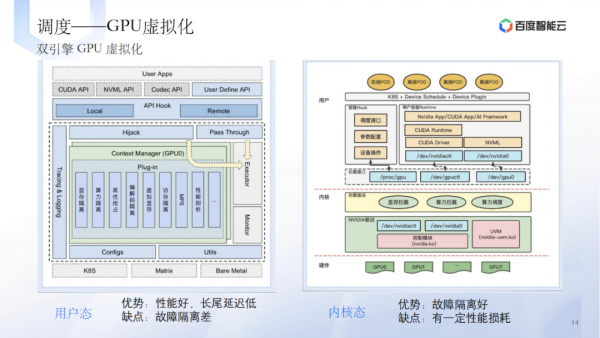
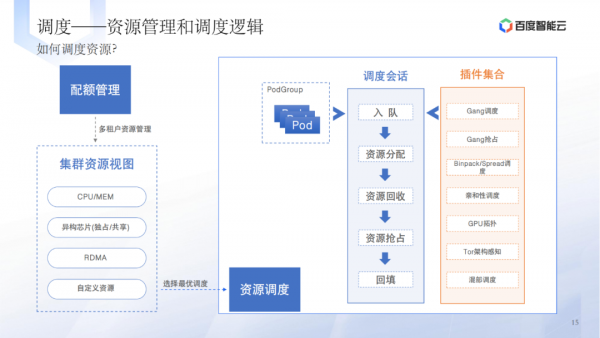
调度层的技术实践包括提高单卡资源利用率、GPU虚拟化、资源管理和调度逻辑等。 -
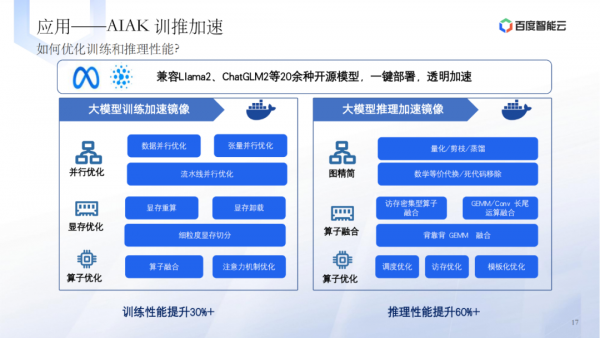
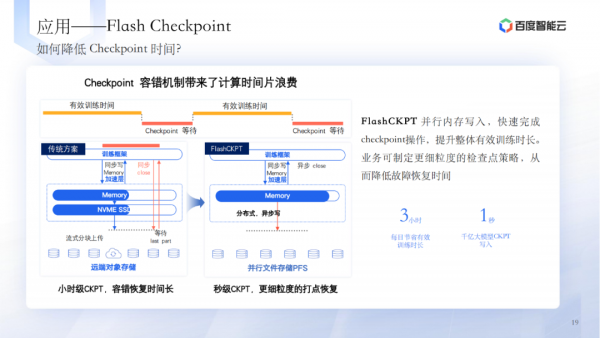
应用层的技术实践涉及AIAK训推加速、训练容错、Flash Checkpoint等。 -
运维方面的实践包括故障处理、容量管理、任务性能调优等。
-
智算平台的发展应致力于简化下层复杂性,使GPU的使用更加便捷。 -
应定位于连接异构资源和承载AI平台的关键角色。 -
发展趋势显示预训练难度增加,领域微调多样化,模型推理可能迎来新的增长。














好文章,需要你的鼓励


2026-07-06
我如何整理散落在网络各处的数千张照片和视频
作者历经多年积累了大量照片和视频,分散存储在Google、Apple、Flickr、Dropbox、OneDrive五个云端及多个本地存储设备中。他通过"收集、整理、整合"三步法完成了清理:首先汇总所有存储位置的文件,然后删除模糊、重复及无意义的内容,最后统一迁移至Google Photos。借助去重工具大幅削减冗余文件,并遵循3-2-1备份原则,年订阅费用从近300美元降至60美元以下。

摩德纳大学团队揭秘:AI的“眼睛“和“大脑“为什么总是鸡同鸭讲,他们是怎么修好的?
这项研究提出HeRA方法,通过精准识别语言大模型中对齐最弱的注意力头并施加拓扑对比学习损失,有效提升多模态AI的视觉理解能力,同时抑制视觉幻觉,且不损害语言推理能力。

极端高温考验电网,电动校车“反向充电“成救星
上周北美热浪肆虐之际,电动汽车并未如批评者所担忧的那样加剧电网负担,反而通过V2G(车辆到电网)技术向电网反向输电。目前约230辆电动校车已可向电网提供8兆瓦时电力,足够约1600户家庭使用4小时。加州奥克兰统一学区的74辆电动校车每年可回馈约2.1吉瓦时清洁能源。随着规模扩大,V2G技术还有望降低用电峰值成本,并在自然灾害中为社区提供应急供电保障。

一个模型,随心切换延迟——英伟达与中研院联手打造的万能语音净化引擎
英伟达与台湾中研院提出一种实时通用语音增强框架,单模型支持30种延迟配置,通过并行卷积层和早退机制分别控制算法与计算延迟,性能接近专用模型。
2024
07/30
14:04
分享
点赞

