
麻省理工报告:企业对生成式AI的使用,几乎增长了一倍
麻省理工学院旗下的著名学术期刊SMR发布了,最新关于生成式AI(AIGC)的应用报告。
本次对欧洲、北美、亚太地区超过1000家大中型企业(员工人数在100—10000名以上),来自金融服务、制造业、零售、建筑、医疗保健等不同行业的领导者、总监、部门主管等进行了调查,查看他们的使用情况。
结果显示,2024上半年,企业对生成式AI的应用几乎增长了一倍,越来越多的企业开始通过这项技术来改变工作方式和决策模式。
同时也吸引了资本市场的目光,2024年上半年,为生成式AI初创企业和相关企业提供资金的风险投资和私募股权投资增长明显。


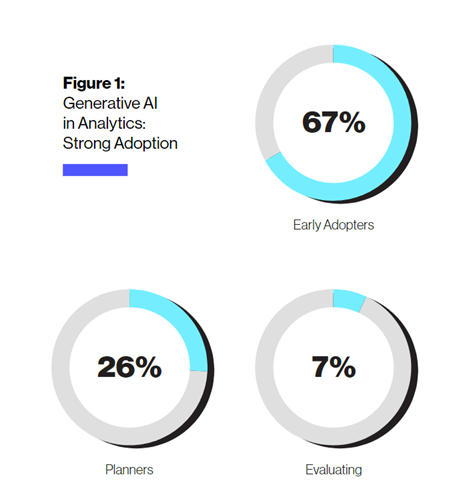
在本次接受调查的企业用户中,67%的早期用户已经使用生成式AI;26%正计划使用;只有7%的用户还处于评估观望状态。这也就是说93%的企业,已经开始重视到生成式AI带来的诸多好处。
已经使用生成式AI的早期用户表示,他们热衷于通过生成式 AI 来改善数据驱动的分析,来解决销售、客户体验等实际业务。他们认为,生成式 AI能够加速数据驱动的决策制定、简化复杂数据的呈现、改善业务分析以及提高产品和服务质量。
例如,全球最大水、卫生和能源服务公司之一Ecolab 便通过使用生成式 AI 进行分析的试点项目,通过预测分析为管理人员和销售人员找出了商机并提升了客户体验,提高整个财务业绩。
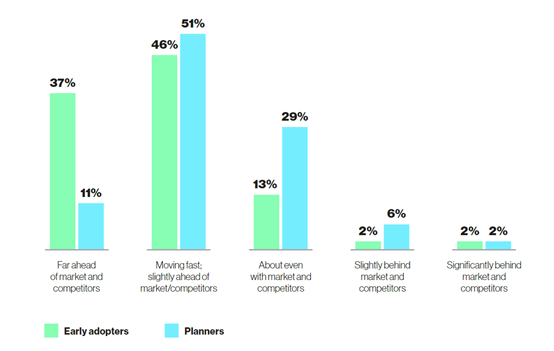
在行业竞争优势方面, 37% 的早期生成式AI使用者认为,自己在市场和竞争对手中遥遥领先,而计划者中这一比例仅为 11%。这表明早期使用者通过积极应用生成式 AI,已经取得了一定的竞争优势,并且相信这种优势将继续扩大。
相反,只有 4% 的早期使用者认为自己落后,而计划使用者的比例为 8%。这说明早期使用者对自身在市场中的地位更有信心,而计划者可能感受到了更大的竞争压力。
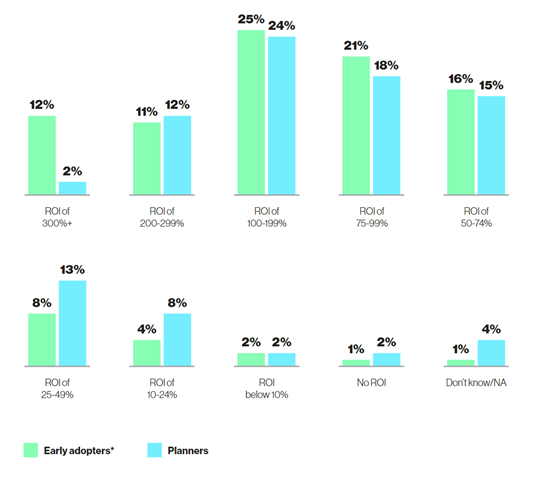
投资回报率是企业应用创新技术的重要指标之一。48%的早期生成式AI使用者期望在三年内获得 100% 或更高的投资回报率,而计划者中这一比例为 38%。这表明早期使用者对生成式 AI 的投资回报充满信心,他们看到了这一技术在提升企业效率、降低成本、增加收入等方面的巨大潜力。
值得关注的是,12% 的早期使用者期望获得 300% 或更高的投资回报率,而计划者的比例仅为 2%。这进一步凸显了早期使用者的乐观预期,他们愿意在生成式 AI 上加大投入,以获取更高的回报。
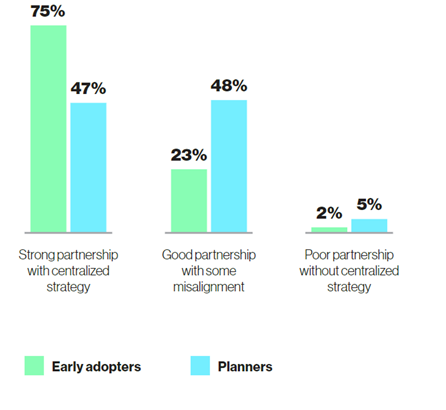
在业务与数据团队合作方面,早期使用者也表现出了明显的优势。75% 的早期使用者表示其业务和数据团队有强大的合作伙伴关系和集中化战略,而计划者中这一比例仅为 47%。
这说明早期使用者更加注重团队之间的协作和沟通,能够有效地将业务需求与数据技术相结合,充分发挥生成式 AI 的潜力。
调查中还发现,不同类型的企业对生成式AI的需求也不同。大中型企业早期应用者的前三大优先事项是改善业务分析(59%)、改善产品和服务(54%)以及提高客户满意度(48%);
而小型公司早期应用者则对提高决策速度(36%)和提高生产力(34%)更为关注。这反映出不同规模企业在应用生成式 AI 时,根据自身的业务特点和需求有着不同的侧重点。
不同的地区企业在应用生成式AI方面也有不同的差异,亚太地区的早期应用者尤其是总部位于澳大利亚、新西兰、印度或日本的企业,将改善客户服务和满意度视为首要任务,欧洲和英国的早期应用者中有 43% 也是这么认为。

而美国和加拿大的早期应用者中有 48% 将提高数据分析师效率视为应用该技术的最重要原因,提高客户服务和满意度则排名第二仅为35%。
此外在生成式AI产品选择方面,超过50%的早期应用者热衷于使用第三方工具,例如,使用OpenAI的ChatGPT等产品;计划者的比例为32%。
这说明早期应用者更倾向于借助外部专业技术来快速获取生成式 AI 的能力,这样比自己训练、微调更加高效省时省力。
好文章,需要你的鼓励


西班牙病毒如何将谷歌带到马拉加
33年后,贝尔纳多·金特罗决定寻找改变他人生的那个人——创造马拉加病毒的匿名程序员。这个相对无害的病毒激发了金特罗对网络安全的热情,促使他创立了VirusTotal公司,该公司于2012年被谷歌收购。这次收购将谷歌的欧洲网络安全中心带到了马拉加,使这座西班牙城市转变为科技中心。通过深入研究病毒代码和媒体寻人,金特罗最终发现病毒创造者是已故的安东尼奥·恩里克·阿斯托尔加。

多伦多大学发现:聊天机器人的“嘴巴“影响它们的智商
这项由多伦多大学领导的研究首次系统性地揭示了分词器选择对语言模型性能的重大影响。通过训练14个仅在分词器上有差异的相同模型,并使用包含5000个现实场景测试样本的基准测试,研究发现分词器的算法设计比词汇表大小更重要,字符级处理虽然效率较低但稳定性更强,而Unicode格式化是所有分词器的普遍弱点。这一发现将推动AI系统基础组件的优化发展。

LangChain核心库曝出严重漏洞,AI智能体机密信息面临泄露风险
人工智能安全公司Cyata发现LangChain核心库存在严重漏洞"LangGrinch",CVE编号为2025-68664,CVSS评分达9.3分。该漏洞可导致攻击者窃取敏感机密信息,甚至可能升级为远程代码执行。LangChain核心库下载量约8.47亿次,是AI智能体生态系统的基础组件。漏洞源于序列化和反序列化注入问题,可通过提示注入触发。目前补丁已发布,建议立即更新至1.2.5或0.3.81版本。

北大研究团队颠覆视频AI训练新方法:让机器像人类一样“预测下一帧“学习世界
北京大学研究团队提出NExT-Vid方法,首次将自回归下一帧预测引入视频AI预训练。通过创新的上下文隔离设计和流匹配解码器,让机器像人类一样预测视频下一帧来学习理解视频内容。该方法在四个标准数据集上全面超越现有生成式预训练方法,为视频推荐、智能监控、医疗诊断等应用提供了新的技术基础。
2024
09/23
11:04
分享
点赞

