
极智AI | 解读大模型性能测试指标及测试方法
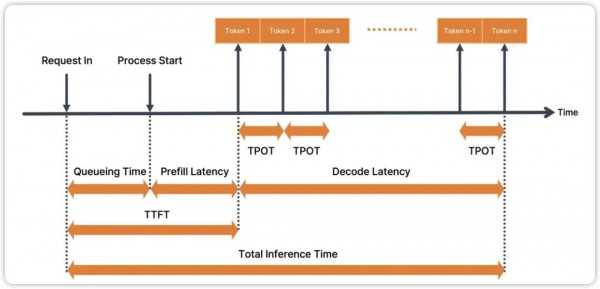
这里这张图非常的清晰,借鉴至这篇文章(https://medium.com/squeezebits-team-blog/vllm-vs-tensorrt-llm-1-an-overall-evaluation-88f281bf01c7),主要就是涉及 TTFT、TPOT、Total Inference Time (Latency) 以及图中没有提及的 TPS,这几个大模型的性能指标不只是适用于纯语言大模型 LLM,也适用于多模态大模型 MLLM,所以还是比较通用。
1. TTFT (Time to First Token) ==> 首Token时间
定义:从向模型输入 prompt 开始到模型生成第一个输出 token 所花费的时间。
作用:从业务角度来说是反映模型的初始响应速度,对于实时交互式应用非常重要,较低的TTFT可以提高用户体验,使用户感觉模型响应迅速;从算法推理角度来说,其实主要是在掐大模型推理的 Prefill 时间,更加准确一些的是上图中的 Queueing Time + Prefill Latency 时间和。
2. Latency (Total Inference Time) ==> 延时
定义:从输入 prompt 到模型生成完整输出所消耗的总时间。
作用:总体的响应时间,包含 TTFT 和生成所有 tokens 的时间,当然对于需要快速响应的应用,延时越低越好。
3. TPOT (Tokens Per Output Time) ==> 平均Token时间
定义:模型在输出阶段 (Decode 阶段) 每个输出 token 的延时。
计算方式:

作用:衡量模型生成阶段自回归蹦出来输出的效率。
4. TPS(Tokens Per Second) ==> 平均每秒Token数
定义:模型每秒生成的tokens数量。
计算方式:

作用:直接衡量模型的生成速度 (还是指 decode 阶段)。TPS 越高,表示模型生成文本的速度越快。
下面实操在 transformers 中测量 TTFT、TPOT、Latency 和 TPS 数据的代码。
def measure_performance(model, tokenizer, prompt, max_new_tokens=50):inputs = tokenizer(prompt, return_tensors="pt")input_ids = inputs.input_ids.to(model.device)# 测量TTFTstart_time = time.time()with torch.no_grad():outputs = model.generate(input_ids, max_new_tokens=1)ttft = time.time() - start_time# 测量TPOT和Latencystart_time = time.time()with torch.no_grad():outputs = model.generate(input_ids, max_new_tokens=max_new_tokens)total_time = time.time() - start_timetpot = (total_time - ttft) / max_new_tokenslatency = total_time# 计算TPStps = max_new_tokens / latencyreturn ttft, tpot, latency, tpsprompt = "Once upon a time"ttft, tpot, latency, tps = measure_performance(model, tokenizer, prompt)print(f"TTFT: seconds")print(f"TPOT: seconds")print(f"Latency: seconds")print(f"TPS: tokens/second")
如果你稍微心细一些可能会发现上述的代码是在掐 max_new_tokens 的时间,而实际的输出 token 数一定会是 <= max_new_tokens,这应该很好理解。所以更加准确一些的测试方法是掐实际输出 tokens,实际输出 tokens 可以使用类似 len(tokenizer.encode(response)) 的代码进行计算。
所以可以看到大模型这种生成的模式测性能,指标和以前的 CV 小模型测性能差别非常之大。
好文章,需要你的鼓励


亚马逊Mechanical Turk停止接受新用户,众包平台走向终结
亚马逊旗下运营近20年的众包平台Mechanical Turk已停止接受新用户注册,并将于2026年7月30日正式关闭。该平台于2005年上线,早于AWS公有云业务,曾是全球知名的众包任务市场,涵盖验证码识别、情感标注等人工任务,后转型为AI训练数据标注工具。随着亚马逊推出SageMaker Ground Truth等替代方案,Mechanical Turk的历史使命已宣告终结。

当AI助手“看“电脑屏幕,就像让一个视力正常的人蒙眼操作——德克萨斯大学达拉斯分校的解法
LUMOS是一个让AI通过操作系统无障碍接口直接读取界面语义信息来操控电脑的中间层,避免依赖截图识别,降低AI电脑操作的资源消耗和出错率。

微软推出Memora,致力于解决AI智能体的记忆难题
微软研究院发布Memora记忆系统,旨在解决AI智能体在长期部署中记忆碎片化、检索效率低的问题。Memora通过将存储内容与检索方式解耦,引入"主抽象"与"线索锚点"双组件架构,在LoCoMo和LongMemEval两项基准测试中表现优异,上下文token用量最高可降低98%。但专家提醒,实际企业成本还需考虑索引、存储及合规审计,且该项目目前仍处于研究阶段,尚未达到生产就绪水平。

腾讯混元携手多所高校,让3D网格生成快如闪电——PolyFlow如何破解困扰业界多年的“拓扑难题“
腾讯混元联合多所高校提出PolyFlow,用流匹配模型并行生成艺术家风格3D网格,速度比自回归方法快百倍,几何精度达到新高。

