
极智AI | 多模态大模型中的动态高分辨率
动态分辨率技术允许模型根据输入图像的复杂度和处理需求,实时调整其处理的分辨率。在处理简单或者信息量较少的图像时,模型可能会采用较低的分辨率以减少计算量;在处理复杂或者细节丰富的图像时,模型则会采用更高的分辨率以捕获更多细节。
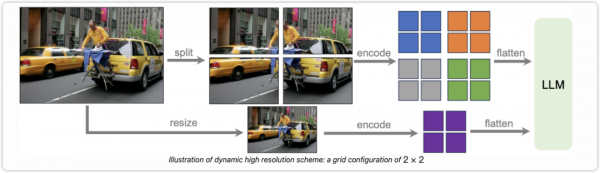
下面是 LLava-Next 中动态高分辨率的实现示意图,其实就是两个分支,一个是 split 切图,一个是 resize 直接对大图进行缩放,这是为了保留全局的语义信息。对于视觉编码模型的输入来说,动态高分辨率的切图比如切 4 张图,完了还要再加上 resize 的那张图,这样其实是 5 张图的输入。
从代码实现来说,下面的动态高分辨率的代码实现来自 InternVL2 的图片预处理,主要就是对动态高分辨率的处理,
# 忽略导入IMAGENET_MEAN = (0.485, 0.456, 0.406)IMAGENET_STD = (0.229, 0.224, 0.225)def build_transform(input_size):MEAN, STD = IMAGENET_MEAN, IMAGENET_STDtransform = T.Compose([T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),T.ToTensor(),T.Normalize(mean=MEAN, std=STD)])return transformdef find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):best_ratio_diff = float('inf')best_ratio = (1, 1)area = width * heightfor ratio in target_ratios:target_aspect_ratio = ratio[0] / ratio[1]ratio_diff = abs(aspect_ratio - target_aspect_ratio)if ratio_diff < best_ratio_diff:best_ratio_diff = ratio_diffbest_ratio = ratioelif ratio_diff == best_ratio_diff:if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:best_ratio = ratioreturn best_ratiodef dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):orig_width, orig_height = image.sizeaspect_ratio = orig_width / orig_height# calculate the existing image aspect ratiotarget_ratios = set((i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) ifi * j <= max_num and i * j >= min_num)target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])# find the closest aspect ratio to the targettarget_aspect_ratio = find_closest_aspect_ratio(aspect_ratio, target_ratios, orig_width, orig_height, image_size)# calculate the target width and heighttarget_width = image_size * target_aspect_ratio[0]target_height = image_size * target_aspect_ratio[1]blocks = target_aspect_ratio[0] * target_aspect_ratio[1]# resize the imageresized_img = image.resize((target_width, target_height))processed_images = []for i in range(blocks):box = ((i % (target_width // image_size)) * image_size,(i // (target_width // image_size)) * image_size,((i % (target_width // image_size)) + 1) * image_size,((i // (target_width // image_size)) + 1) * image_size)# split the imagesplit_img = resized_img.crop(box)processed_images.append(split_img)assert len(processed_images) == blocksif use_thumbnail and len(processed_images) != 1:thumbnail_img = image.resize((image_size, image_size))processed_images.append(thumbnail_img)return processed_imagesdef load_image(image_file, input_size=448, max_num=12):image = Image.open(image_file).convert('RGB')transform = build_transform(input_size=input_size)images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)pixel_values = [transform(image) for image in images]pixel_values = torch.stack(pixel_values)return pixel_values
这段代码其实就是主要就是两个过程,首先是寻找最接近的宽高比,也就是 find_closest_aspect_ratio 函数在做的事情,然后就是动态预处理,包括了切割和缩放,最后进行拼接,结束,等待送入视觉编码模型。
好了,以上分享了 多模态大模型中的动态高分辨率,希望我的分享能对你的学习有一点帮助。
好文章,需要你的鼓励



Allen AI团队推出SAGE:首个能像人类一样“想看多长就看多长“的智能视频分析系统
Allen AI研究所联合多家顶尖机构推出SAGE智能视频分析系统,首次实现类人化的"任意时长推理"能力。该系统能根据问题复杂程度灵活调整分析策略,配备六种智能工具进行协同分析,在处理10分钟以上视频时准确率提升8.2%。研究团队创建了包含1744个真实娱乐视频问题的SAGE-Bench评估平台,并采用创新的AI生成训练数据方法,为视频AI技术的实际应用开辟了新路径。

联想推出DE6600系列:更智能的存储解决方案
联想推出新一代NVMe存储解决方案DE6600系列,包含全闪存DE6600F和混合存储DE6600H两款型号。该系列产品延迟低于100微秒,支持多种连接协议,2U机架可容纳24块NVMe驱动器。容量可从367TB扩展至1.798PiB全闪存或7.741PiB混合配置,适用于AI、高性能计算、实时分析等场景,并配备双活控制器和XClarity统一管理平台。

AI视觉模型真的能看懂长篇文档吗?中科院团队首次揭开视觉文本压缩的真相
中科院团队首次系统评估了AI视觉模型在文本压缩环境下的理解能力,发现虽然AI能准确识别压缩图像中的文字,但在理解深层含义、建立关联推理方面表现不佳。研究通过VTCBench测试系统揭示了AI存在"位置偏差"等问题,为视觉文本压缩技术的改进指明方向。
2024
11/01
11:04
分享
点赞

