
Meta首席AI科学家扬·勒昆:人类水平的智能是一个逐步进化的过程,不会是一夜之间的突破
Meta首席人工智能科学家扬·勒昆 (Yann LeCun) 近期参加了由IBM等主办的哈德逊论坛(Hudson Forum 2024) ,并发表了他对人工智能未来展望的主题演讲。

勒昆在演讲中提出了实现人类水平AI的重要性。他预见了一个未来,人们将通过智能眼镜与AI系统进行交互,这些系统将像智能虚拟助手一样为我们工作,增强人类的智力,提高创造力和生产力。为了实现这一愿景,我们需要构建能够理解世界、记忆事物、拥有直觉、常识、推理和规划能力的机器,这些能力是当前AI系统所不具备的。
勒昆强调,有些AI系统在特定领域表现出色,但它们仍然无法达到人类或动物对世界的理解水平。因此,我们需要开发新的AI架构,使机器能够模拟人类如何通过优化过程来理解和互动世界。勒昆提出了一个名为“目标驱动AI”的架构,这种架构通过优化过程来模拟人类理解和与世界互动的方式,从而克服现有AI系统的局限性。这一架构的核心理念是将目标和优化结合起来,让AI系统能够主动寻找最佳的动作序列以实现特定目标,从而模拟人类的认知过程,尤其是在规划和推理方面的能力。
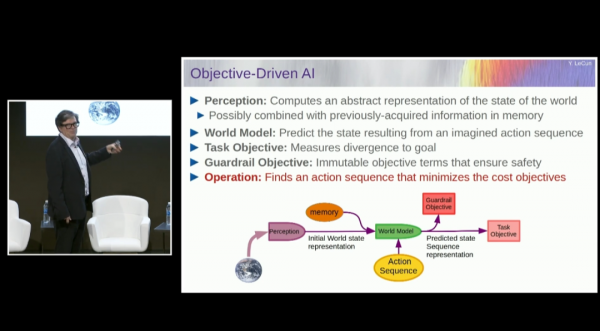
在“目标驱动AI”架构中,AI系统被设计为具备推理和规划的能力,使其能够评估不同的行动方案,并选择那些最有可能实现目标的方案。这种能力对于处理复杂任务和环境至关重要。勒昆还强调了自监督学习在这一架构中的重要性,它使AI系统能够学习输入数据的内在表示,这些表示可以用于后续的决策和行动。
此外,“目标驱动AI”架构特别适合处理需要实时决策的复杂任务。通过优化过程,系统能够快速适应环境变化,并做出相应的调整。这种架构不仅能够提高AI系统处理任务的效率,还能够使其在各种应用场景中发挥更大的作用,推动人工智能的进一步发展。勒昆认为,这种架构将为未来的AI系统设计提供新的方向,使其能够更好地理解和预测世界的状态变化,从而实现更高级的智能功能。他还提到,Facebook AI Research(FAIR)实验室不仅在理论研究上探索这一架构,还成立了Gen AI产品部门,专注于将这些理论转化为实际的AI产品。
勒昆在演讲中提出了对自回归模型,尤其是Transformer模型的批评,指出这些模型在处理复杂任务时存在局限性。他强调,尽管这些模型在预测序列中的下一个项目方面表现出色,例如在文本中预测下一个单词,但它们在进行复杂推理方面的能力有限。此外,这些模型通常只能处理离散对象的数据,如单词、符号或标记,而在处理连续的或非结构化的数据,比如视频或真实世界的物理交互时,会遇到挑战。
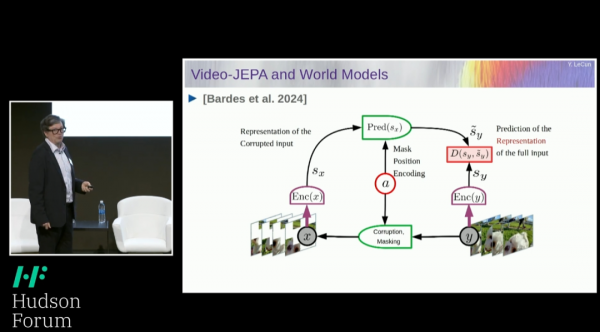
为了克服这些挑战,勒昆提出了一种新的训练方法,即通过观看视频或生活在真实世界中来训练AI系统,使它们能够学习常识和物理直觉。这种方法的目标是让AI系统能够更好地理解和预测世界的状态变化,例如预测物体在被推下桌子时的运动,或者车辆在交通中的响应行为。他强调,尽管自回归模型在处理文本等结构化数据方面取得了成功,但在处理视频等非结构化数据时面临更大的挑战,因为这些数据包含了丰富的空间和时间信息,这些信息很难被传统的自回归模型捕捉和理解。勒昆提倡寻找更好的数据表示方法,以帮助AI系统捕捉到更复杂和连续的数据特征,从而在没有额外学习的情况下完成新任务,通过规划和推理来实现目标。
在演讲中,勒昆提到了他与马克·扎克伯格的对话,扎克伯格一直在询问实现人类水平人工智能所需的时间。勒昆的回答反映了他对这一过程的长期性和复杂性的认识。他表示,要使AI系统能够推理、规划和理解世界,需要经历一个长期的研发过程,即使不是十年,也需要几年的时间。他强调,这样的系统需要具备处理复杂任务的能力,如理解物理直觉、常识和进行抽象思考,这些是目前AI系统所缺乏的。勒昆解释说,达到人类水平的智能不会是一夜之间的突破,而是一个逐步进化的过程,AI系统将逐渐获得更高级的能力,而不是突然出现完全的人类水平智能。
好文章,需要你的鼓励


“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

清华&OPPO联合打造的“智能侦探“:当AI学会主动追查证据,视觉问答准确率飙升27%
ProMSA是由清华大学与OPPO联合提出的视觉问答智能体,通过自适应切换图像和文字检索工具、多轮渐进式搜索,在E-VQA和InfoSeek上超越现有方法。


蚂蚁集团打造的AI“安全警卫“:当智能助手学会看图识险,多模态内容审核迎来新突破
蚂蚁集团AI安全实验室开发的SingGuard是一套多模态内容安全审核系统,能同时理解图片与文字的组合意图,并支持运行时动态传入自定义规则,实现策略自适应的安全判断。
2024
10/17
15:04
分享
点赞

