
极智AI | 解读强化学习中的Q-learning
马尔可夫决策过程 (MDP)

Q函数
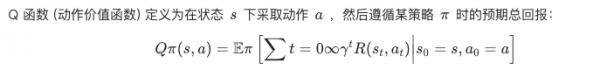
贝尔曼最优方程
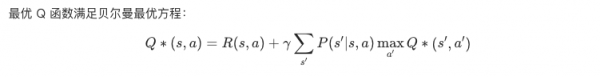
Q-learning更新规则

Q-learning算法步骤

下面以经典的 FrozenLake 环境(一个 4x4 的网格世界)为例,使用 Python 和 OpenAI Gym 库来实现 Q-learning 算法。
import numpy as npimport gym# 创建FrozenLake环境env = gym.make('FrozenLake-v1', is_slippery=False)# 初始化参数num_states = env.observation_space.nnum_actions = env.action_space.nQ = np.zeros((num_states, num_actions))num_episodes = 1000max_steps = 100alpha = 0.1 # 学习率gamma = 0.99 # 折扣因子epsilon = 0.1 # 探索率for episode in range(num_episodes):state = env.reset()for step in range(max_steps):# 选择动作(ε-贪心策略)if np.random.uniform(0, 1) < epsilon:action = env.action_space.sample()else:action = np.argmax(Q[state, :])# 执行动作,获得下一个状态和奖励next_state, reward, done, info = env.step(action)# 更新Q函数best_next_action = np.argmax(Q[next_state, :])td_target = reward + gamma * Q[next_state, best_next_action]td_error = td_target - Q[state, action]Q[state, action] += alpha * td_error# 状态更新state = next_state# 回合结束if done:breakprint("训练完成后的Q表:")print(Q)
其中:
- 环境初始化:使用
gym.make('FrozenLake-v1')创建环境; - Q表初始化:Q 是一个二维数组,维度为
[num_states, num_actions],用于存储每个状态-动作对的价值; - 主循环:循环进行多个回合,每个回合代表一次完整的游戏;
- 动作选择:使用 ε-贪心策略,以概率 ε 随机选择动作,或以概率 1-ε 选择当前 Q 值最大的动作;
- Q值更新:根据之前提到的 Q-learning 更新公式更新 Q 表;
- 回合终止条件:如果到达终止状态(成功或者掉入陷阱),则结束当前回合;
为了平衡探索和利用,ε-贪心策略以 ε 的概率进行探索 (随机选择动作),以 1-ε 的概率进行利用(选择当前最优动作)。学习率决定了新获取的信息在多大程度上覆盖旧的信息,较高的学习率意味着对新信息的依赖性更强。折扣因子用于权衡即时奖励和未来奖励的重要性。接近1的折扣因子表示更加看重未来的奖励。在满足一定条件下,如所有状态-动作对被无限次访问、学习率满足罗宾条件等,Q-learning 算法能够保证收敛到最优 Q 函数。Q-learning 是强化学习中最经典和基础的算法之一,它通过学习状态-动作值函数来指导智能体的决策。通过不断地与环境交互和更新 Q 值,智能体最终能够学到一个最优策略,即在每个状态下选择使得长期累积奖励最大的动作。
好文章,需要你的鼓励


Ring推出Fire Watch功能,利用家庭摄像头追踪野火威胁
洛杉矶大火一年后,亚马逊Ring安全服务推出Fire Watch功能以降低野火风险。该功能集成在Ring应用的邻里版块中,计划今春全美推广。系统依托非营利组织Watch Duty的野火预警,当检测到野火时会通知附近用户,符合条件的户外摄像头将启用AI图像识别监测火情。Ring还推出AI异常事件预警和主动警告功能。但隐私问题仍存争议,多个州因隐私法限制相关AI功能使用。

剑桥大学突破性研究:如何让AI在对话中学会真正的自信判断
剑桥大学研究团队首次系统探索AI在多轮对话中的信心判断问题。研究发现当前AI系统在评估自己答案可靠性方面存在严重缺陷,容易被对话长度而非信息质量误导。团队提出P(SUFFICIENT)等新方法,但整体问题仍待解决。该研究为AI在医疗、法律等关键领域的安全应用提供重要指导,强调了开发更可信AI系统的紧迫性。

Snowflake与Google Gemini深度整合,全云环境支持数据分析
数据平台Snowflake将谷歌Gemini模型集成到其Cortex AI中,让客户在数据环境边界内访问基础模型。Cortex AI支持跨云推理,无论客户环境运行在AWS、Azure还是谷歌云上。该平台已支持OpenAI、Anthropic等多家模型提供商,采用按需付费模式。客户可通过SQL或API直接访问模型,分析多模态数据并构建AI应用场景。

威斯康星大学研究团队破解洪水监测难题:AI模型终于学会了“眼观六路“
威斯康星大学研究团队开发出Prithvi-CAFE洪水监测系统,通过"双视觉协作"机制解决了AI地理基础模型在洪水识别上的局限性。该系统巧妙融合全局理解和局部细节能力,在国际标准数据集上创造最佳成绩,参数效率提升93%,为全球洪水预警和防灾减灾提供了更准确可靠的技术方案。

