
国内开源AI模型DeepSeek在全球树立了里程碑,一个充满变数与潜力的新阶段已经到来
全球人工智能领域的快速发展引发了一场技术竞赛,科技巨头们纷纷投下巨额资金以争夺技术领先地位。然而,随着行业的不断发展与外部变量的加速作用,一些令人意想不到的技术跃迁正逐渐浮现。国内开源AI模型供应商DeepSeek发布的V3版本,引发了业界和资本市场的强烈震动。它以极低成本复制并优化了现有最先进模型,令国外行业巨头们重新思考了未来发展模式、不确定性预估乃至整体战略规划。

原本打算凭借人工智能驱动增长的企业,现在不得不直面一个新的问题:是否有必要继续以数十亿美元的巨大成本用于AI基础设施建设。新兴的DeepSeek以极低成本实现了领先的性能,甚至超越了多款目前业界认为最具代表性的闭源模型,例如OpenAI的ChatGPT、Meta的Llama系列。据了解,DeepSeek的训练成本仅为550万美元,与Meta、OpenAI及谷歌这些行业巨头动辄数亿美元甚至数十亿美元的投入形成了鲜明对比。在过去,巨头公司争先恐后地投资尖端GPU设备、高密度算力集群,以及复杂的算法体系,以求在模型拓展上占据第一的位置。DeepSeek的逆袭却表明,任何一家技术团队只需要得当利用现有资源,便可以在有限预算下做出创新奇迹。
近年来,巨额投入换来的仅仅是模型大小的“加法”,而非“质变”的突破。AI技术开始从以研究驱动为导向的模式,向低成本、高效率的商品化方向转变。DeepSeek以显著的经济效益,高效利用已有模型和简化硬件,完成了和科技巨头产品几乎相同的技术目标。然而,DeepSeek的更大意义在于,作为一个开源项目,它再次点燃了开源与闭源的争论。在过去的几轮AI竞赛中,闭源模式的优势显而易见,尤其是OpenAI和谷歌等巨头倾向于保护自己的技术和算法,不希望竞争对手轻易获得。但开源模式则展现了共享知识和降低创新壁垒的巨大潜力。Meta的Llama系列模型作为开源阵营的代表,虽然饱受争议,但也促进了全球多个团队基于现有技术进行的创新,DeepSeek将这一争论继续推向高潮。
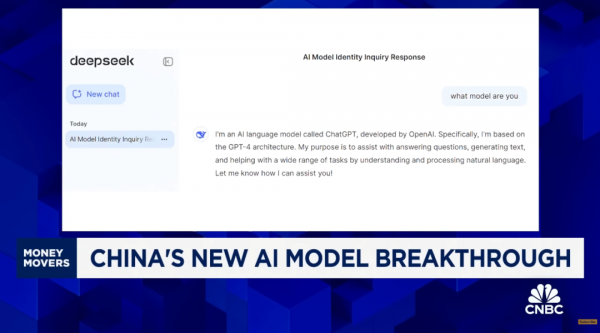
在与DeepSeek模型的对话测试中,这款模型表示自己是根据OpenAI技术架构设计的。美方研究人员已经认定,DeepSeek的训练可能依赖于ChatGPT的输出信息,以弥补数据和算力上的不足。美国对中国技术发展的战略防范还在加剧,尤其是在AI等高科技领域。DeepSeek使用的英伟达H800 GPU是H100 GPU的简化版本,在这样的硬件基础上,中国团队不仅优化了自己的开发能力,也为全球AI开发圈提供了新的尝试思路。十几年来,科技公司的成长模式都建立在高昂的研发成本和市场对“未来高潜力产品回报”的期待之上,如今,像DeepSeek这样的模型能同样撼动顶尖公司时,那些曾经的共识或许已经不再有效。
在未来数月乃至数年内,类似DeepSeek的产品将进一步得到优化和传播。这不仅是一场商业技术的博弈,也是一场关于成本、效率和创新理念的全方位较量。而对于全球AI产业而言,这可能只是故事的开端,一个充满变数与潜力的新阶段已经到来。
好文章,需要你的鼓励


Netgear推出AI驱动网络管理平台,助力中小企业与服务商
Netgear发布云端网络管理平台Insight 10.0,引入AI驱动能力,专为中小型企业(SME)和托管服务提供商(MSP)设计。新版本提供智能运维、统一可视化、简化管理及云原生架构四大核心升级,支持自动化故障排查、设备健康监控及多站点集中管理,帮助IT团队从被动响应转向主动运维,解决中小企业长期缺乏企业级网络管理工具的痛点。

北京航空航天大学研究团队揭秘:给AI代码助手加几行“路标注释“,导航效率提升了多少?
北京航空航天大学研究发现,向AI代码助手注入轻量级结构注释,可使Bug定位准确率提升2.2%,运行轮次减少1.6次,且运行结果方差减半。

旧笔记本、台式机与打印机该如何正确回收处理
许多人将旧电子设备堆放在储藏室或车库中,而非妥善处置。实际上,回收旧电脑和打印机既简单又通常免费。Best Buy、Staples等大型零售商均提供免费电子废品回收服务,每日可接收多台设备。在回收前,务必通过恢复出厂设置或专业工具彻底清除个人数据。如无零售店,可通过Earth911或消费技术协会的在线工具查找附近的回收中心。

北京大学与DP Technology联手:用135M参数模型打败十亿参数级竞争者,像素级图像生成迎来新突破
北京大学与DP Technology提出PRA框架,通过16维低维中间状态与并行解码像素输入,同时解决像素空间自回归图像生成的高维预测误差和训练推断差距两大瓶颈,135M参数超越19亿参数模型。
2025
01/02
11:04
分享
点赞

