
谷歌“Ironwood” TPU Pod与其他AI超级计算机的对比
作为上周Google Cloud Next 2025大会前的预简报以及主旨演讲期间,谷歌高层不断将一组“Ironwood” TPU v7p系统的Pod与劳伦斯利弗莫尔国家实验室的“El Capitan”超级计算机进行对比。他们反复这么做,而且方式错误,这让我们感到非常恼火。
在大规模AI系统方面,进行这样的比较是完全合理的,即便在一种情况下(El Capitan)该机器的主要用途是运行传统的高性能计算(HPC)仿真和建模工作负载,而在另一种情况下(Ironwood Pod)该机器根本无法进行高精度浮点计算,实际上只是为了进行AI训练和推理。可以说,采用CPU和GPU混合架构进行计算的机器,由于其在数值类型和精度上的广泛适用性以及能够处理多种工作负载,更像是通用机器,而这种多用途的机器架构确实具有一定价值。
然而,事实证明,劳伦斯利弗莫尔的El Capitan以及阿贡国家实验室的“Aurora”等超大规模机器,完全可以与使用定制XPU加速器构建的机器相抗衡,归功于美国能源部与超级计算机制造商之间达成的优惠协议,这些系统在性价比方面明显优于谷歌自己使用设备的支付成本,并远远低于谷歌向客户出租TPU进行AI工作负载时收取的费用。
下面是我们看到的一张问题图表:

在这组数据中,谷歌将El Capitan的持续性能与采用44,544个AMD “Antares-A” Instinct MI300A混合CPU-GPU计算引擎的系统在64位浮点精度下运行High Performance LINPACK(HPL)基准测试的成绩相比,后者是以理论峰值性能与配有9,216个TPU v7p计算引擎的Ironwood pod进行比较。
这是一个完全荒谬的比较,谷歌的高层本应该知道这一点,而且他们确实知道。但或许更重要的是,性能只是故事的一半。你还必须考虑计算成本。高性能必须以尽可能低的成本实现,而没有人比美国能源部在获取HPC设备方面获得更好的优惠了。
在缺少大量数据的情况下,我们对现代AI/HPC系统进行了价格/性能分析,其中许多系统是基于CPU与GPU的组合构建的,其中GPU来自AMD或Nvidia,而CPU在原始计算能力方面并非特别关键。请看下图:
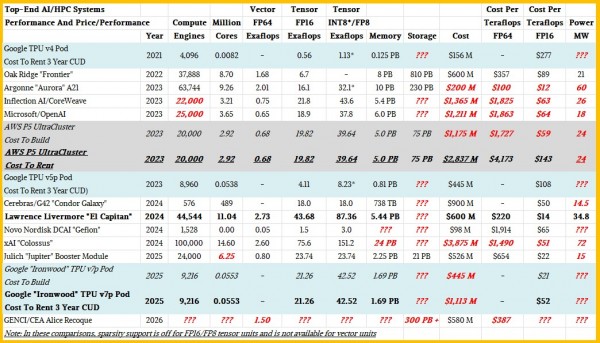
我们意识到这个比较并不完美。谷歌和Amazon Web Services的定价包括租用系统三年的成本,当然这还包含了电力、冷却、设施和管理费用。而对于图中许多超级计算机,预算则涵盖了三至四年期间的设施、电力和冷却费用,我们尽力不将将机器投入使用及调试过程中所涉及到的一次性工程成本(NRE)计算在内。对于各个AI机器,我们在没有相关信息时对机器规模和成本做出了估计。
所有估计部分均以粗斜红体标示,对于暂时无法做出估算的数据我们都以问号标明。
我们只显示了通过3D环面互连连接在一起形成相当大规模Pod的TPU系统。因此,上一代仅能在2D环面拓扑下扩展到256个计算引擎的“Trillium” TPU v6e系统未被纳入对比。
正如你所预期的那样,在过去的四年中,无论是FP64高精度处理,还是FP16和FP8低精度处理的成本都有所下降,而机器性能则持续提高。这本身是件好事。但机器的成本却增长迅速,以至于我们如今所称的“能力级”AI超级计算机价格已经高达数十亿美元。(例如上图中展示的xAI“Colossus”机器,于去年安装。)
在上表中,我们计算了在长期承诺折扣(CUDs,与Amazon Web Services中的预留实例定价类似,可为长期租用提供折扣)下谷歌TPU pod的租用成本。传统的HPC超级计算机通常在投入使用时可维持三年,有时甚至四年,因此这是一个很好的比较点。对于Ironwood TPU pod的估算价格,我们假设谷歌在从TPU v4 pod跳跃到TPU v5p pod时采取了较为激进的定价策略。
现在,为了解除混淆。一个Ironwood TPU v7p pod在FP16精度下的额定性能为21.26 exaflops,而在FP8精度下则翻倍达到42.52 exaflops。该Pod具有1.69 PB的HBM内存,我们估计其构建成本约为4.45亿美元,三年租用成本超过11亿美元。换算下来,谷歌使用由9,216个Ironwood TPU互联组成的Ironwood pod,每Teraflops的成本大约为21美元,而租用成本大约为每Teraflops 52美元。
由惠普企业构建的El Capitan机器花费劳伦斯利弗莫尔600万美元美金(600百万美元),这相当于在FP16精度下的峰值性能成本为每Teraflops 14美元。由于Intel在阿贡的“Aurora”机器上核销了3亿美元,导致该DOE实验室仅花费2亿美元购置这套AI/HPC系统,这台系统在FP16精度下的16.1 exaflops性能使得每Teraflops的成本仅为12美元。值得一提的是,Aurora机器所使用的“Ponte Vecchio” GPU与El Capitan的MI300A CPU-GPU混合系统以及Ironwood pod的TPU v7p引擎不同,它们不支持FP8处理,但支持INT8处理,就像之前两代在3D环面架构下使用的谷歌TPU一样。
FP8和INT8格式在任何具备该功能且其工作负载能利用该功能的机器上,都能使价格/性能比翻倍;而FP4(Nvidia的“Blackwell” GPU上提供,并将在未来的XPU AI计算引擎中添加)则再次将其翻倍。
我们基于HPC使用FP64性能、AI使用FP16性能进行归一化处理以便简单比较,但也增加了一栏用于FP8或INT8处理。各公司目前都会尽可能在训练和推理过程中使用统一的浮点格式,最终INT16、INT8和INT4格式也将逐步被淘汰。
AWS P5 UltraCluster是由Nvidia “Hopper” H100 GPU构建的集群的典型代表,这些GPU在2022年末、2023年以及2024年初都在使用。我们计算了租用一台拥有20,000个GPU的集群的成本,并依据当时普遍的H100及其他系统成本反推了预估的购置成本。Microsoft Azure和Google Cloud建造类似设备以及向最终用户出租其运算能力所需花费的大致相同。实际上,AWS和Microsoft已经锁定了GPU实例的价格,而这种做法是否合法尚存争议。
如果我们的估计正确,Ironwood pod的构建成本和客户租用成本,大约只有这些具备类似性能的H100集群成本的三分之一,而且其使用的计算引擎数量还不到后者的一半(至少从插槽数量上来看是如此)。
但最后,我们必须明确一点。在峰值理论性能上,El Capitan在FP16和FP8精度下的性能要比Ironwood pod高2.05倍。Ironwood pod并不具备El Capitan 24倍的性能。的确,El Capitan在FP64精度下具有2.73 exaflops的峰值性能,而Ironwood则完全没有,且El Capitan在HPL测试中以FP64模式获得了1.74 exaflops的成绩。
我们目前还没有El Capitan的HPL-MxP测试结果,但预计将在2025年6月于汉堡举行的ISC大会上公布。HPL-MxP使用大量混合精度计算以达到与全FP64计算在HPL测试中相同的结果,如今这种方法能提供大约一个数量级的有效性能提升。这种混合精度的使用预示了未来真正的HPC应用可通过调整和提升低精度计算来或者在相同硬件上完成更多工作,或者用更少的硬件完成相同工作量的方向。
好文章,需要你的鼓励



Allen AI团队推出SAGE:首个能像人类一样“想看多长就看多长“的智能视频分析系统
Allen AI研究所联合多家顶尖机构推出SAGE智能视频分析系统,首次实现类人化的"任意时长推理"能力。该系统能根据问题复杂程度灵活调整分析策略,配备六种智能工具进行协同分析,在处理10分钟以上视频时准确率提升8.2%。研究团队创建了包含1744个真实娱乐视频问题的SAGE-Bench评估平台,并采用创新的AI生成训练数据方法,为视频AI技术的实际应用开辟了新路径。

联想推出DE6600系列:更智能的存储解决方案
联想推出新一代NVMe存储解决方案DE6600系列,包含全闪存DE6600F和混合存储DE6600H两款型号。该系列产品延迟低于100微秒,支持多种连接协议,2U机架可容纳24块NVMe驱动器。容量可从367TB扩展至1.798PiB全闪存或7.741PiB混合配置,适用于AI、高性能计算、实时分析等场景,并配备双活控制器和XClarity统一管理平台。

AI视觉模型真的能看懂长篇文档吗?中科院团队首次揭开视觉文本压缩的真相
中科院团队首次系统评估了AI视觉模型在文本压缩环境下的理解能力,发现虽然AI能准确识别压缩图像中的文字,但在理解深层含义、建立关联推理方面表现不佳。研究通过VTCBench测试系统揭示了AI存在"位置偏差"等问题,为视觉文本压缩技术的改进指明方向。
2025
04/20
20:05
分享
点赞

数智时代,openGauss Summit 2025即将发布哪些技术创新破局
“算力+储能”深度融合:超智算发布分布式算力超级节点储能解决方案
联想推出DE6600系列:更智能的存储解决方案
创业公司如何在严格监管行业中实现生死攸关的创新
OpenAI发布GPT-5.2-Codex模型,软件工程自动化能力大幅提升
Waterfox浏览器宣布拒绝AI功能,瞄准Firefox忠实用户
TikTok美国业务出售交易将于下月完成
破局AI数据中心安全瓶颈:Fortinet联合NVIDIA引领隔离式加速新航向
智算中心进化论,科华数据如何做到“更懂”
更高负载、更快建设:2026年数据中心六大趋势
Snowflake数据库更新引发全球大规模服务中断
AI编程初创公司Lovable融资3.3亿美元,英伟达等科技巨头支持
OpenAI 最新 AI 模型引入新的安全保障措施以防范生物风险
Kraft Group 与 NWN 携手升级 New England Patriots 网络体系
万物皆可AI!“2025年度最值得关注AIGC企业/产品”揭晓
《2025中国AIGC应用全景图谱报告》重磅发布:全面勾勒中国AI创新发展新蓝图
Google 的 Veo 2 视频生成模型加入 Gemini
如果竞争对手推出“高风险” AI,OpenAI可能调整其安全措施
Nvidia 将在美国量产 AI 超级计算机
OpenAI 转变重点:GPT-4.1 优先关注编程与成本效率
Google 推出 Firebase Studio,可在浏览器中几分钟内构建自定义应用的全栈平台
安全堆栈需要像攻击者一样思考,实时评估每个用户
