
一次AI开发1200万美元?华为盘古大模型说NO 原创
理论到实际应用是需要过程的。
比如5G从理论论文到应用有十年之长。任正非多次谈到,华为5G技术来自十多年前的土耳其教授的一篇论文。2008年,土耳其Erdal Arikan教授提出极化码(Polar code)理论之后,一个月后,华为从期刊上了解并评估了阿勒坎的论文,意识到这篇论文的重要性,之后十年,基于该理论,华为5G编码技术实现突破并开始全球应用。
同样目前火热的AI大模型也不是横空出世,在ChatGPT 火热之后,我们看到的ChatGPT 是2018基于OpenAI实验室研发的GPT模型(Generative Pre-trained Transformer)开发的。但其原理也是Google公司在2017年开源的Transformer神经网络架构而来的。
ChatGPT的火热,也让国内AI企业积极推出自己的AI大模型,有代表性的是百度、阿里各自推出自己的对话大模型,一个是一言,一个是千问,还有一个受到大家关注的是华为盘古大模型。
前两天,我们看到在中国人工智能学会主办的人工智能大模型技术高峰论坛上,华为云AI领域首席科学家、国际欧亚科学院院士田奇出席现场,对华为盘古系列大模型的研发与应用落地情况进行了分享。
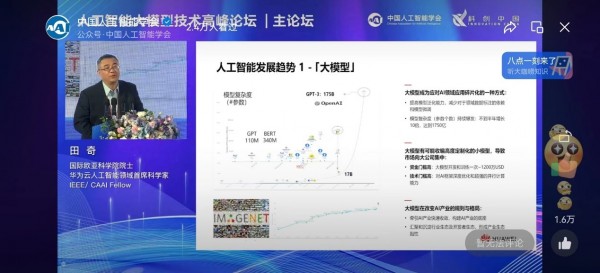
我们从田奇的分享可以看到,华为盘古大模型的当下的服务方式还是更实际一些,AI好不好用,包括算力、算法和数据三部分。这三个部分面临的挑战,田琦奇给点了出来,那就是AI大模型有两个高门槛:
一个是资金门槛高,开发和训练一次花费约1200万美元,一个是技术门槛高,需要对AI框架深度优化和超强的并行计算能力。
那么这两个门槛就让绝大部分的企业和用户挡在在AI大模型研发之外,华为的思路是就是解决传统AI开发面临作坊式开发、样本标注代价大、模型维护困难、模型泛化不足、行业人短缺等难题。这也是盘古大模型的价值和意义。
比如华为开放了盘古大模型开发的全流程大模型使能套件,包括TransFormers大模型套件MindSpore TransFormers、以文生图大模型套件MindSpore Diffusion、人类反馈强化学习套件MindSpore RLHF、大模型低参微调套件MindSpore PET,支撑大模型从预训练、微调、压缩、推理及服务化部署。
当然在“大模型时代”,到底如何实现价值,我们看到华为盘古大模型的思路是首先在强化大模型能力,实现在各垂直领域落地,通过参数微调,适配多个场景。所以华为盘古大模型所提供的服务更广,不仅提供像chatGPT一样的NLP大模型底座,还可以提供CV大模型、科学计算大模型等基础大模型。
同时华为盘古大模型还有一个特点是更灵活,据田奇介绍,在CV大模型和科学计算大模型的多个应用场景。矿山大模型、铁路巡检方案等,面向科学领域的盘古气象大模型、药物分子大模型、海浪预测大模型等。

当然个人建议,包括chatGPT在内的预训练大数据模型的原理是通过预测说话过程中的每个词和每个词的结合概率来生成语句。比如“我喜欢喝啤”,那下一个字的概率是什么,相信大家都知道。当然实际上现在模型已经实现了更复杂的的语音预测。包括词和词的概率,每一个句子的意思和下一个句子的意思,段落和段落的逻辑等。这么看来,有一些场景,预训练模型并不合适,包括气象、股市、经济等混沌事件就不适合预训练模型,因为这些场景,数据越多,越不确定,预测难度就越大。形成了一个死循环。
总之,当前大模型效果如何,还是让子弹飞一会,时间会检验的。同时我期待各个大模型企业可以形成直接的技术壁垒,技术护城河,但是不用形成技术傲慢,也就是你提供的AI产品应该是越来越简单,而不是越来越复杂,让人们望而生畏,那就不是AI护城河了,那就是AI霸权了。
好文章,需要你的鼓励


HPE发布Nvidia Blackwell驱动的AI服务器,抢占AI市场需求
惠普企业(HPE)发布搭载英伟达Blackwell架构GPU的新服务器,抢占AI技术需求激增市场。IDC预测,搭载GPU的服务器年增长率将达46.7%,占总市场价值近50%。2025年服务器市场预计增长39.9%至2839亿美元。英伟达向微软等大型云服务商大量供应Blackwell GPU,每周部署约7.2万块,可能影响HPE服务器交付时间。HPE在全球服务器市场占13%份额。受美国出口限制影响,国际客户可能面临额外限制。新服务器将于2025年9月2日开始全球发货。

阿里巴巴突破AI说话人视频生成技术壁垒:首次实现动作自然度、唇同步准确性和视觉质量的完美平衡
阿里巴巴团队提出FantasyTalking2,通过创新的多专家协作框架TLPO解决音频驱动人像动画中动作自然度、唇同步和视觉质量的优化冲突问题。该方法构建智能评委Talking-Critic和41万样本数据集,训练三个专业模块分别优化不同维度,再通过时间步-层级自适应融合实现协调。实验显示全面超越现有技术,用户评价提升超12%。

ISACA推出AI安全管理高级认证项目
安全专业协会ISACA面向全球近20万名认证安全专业人员推出AI安全管理高级认证(AAISM)。研究显示61%的安全专业人员担心生成式AI被威胁行为者利用。该认证涵盖AI治理与项目管理、风险管理、技术与控制三个领域,帮助网络安全专业人员掌握AI安全实施、政策制定和风险管控。申请者需持有CISM或CISSP认证。

UC Berkeley团队突破AI内存瓶颈:让大模型推理快7倍的神奇方法
UC Berkeley团队提出XQUANT技术,通过存储输入激活X而非传统KV缓存来突破AI推理的内存瓶颈。该方法能将内存使用量减少至1/7.7,升级版XQUANT-CL更可实现12.5倍节省,同时几乎不影响模型性能。研究针对现代AI模型特点进行优化,为在有限硬件资源下运行更强大AI模型提供了新思路。
2023
04/10
11:19
分享
点赞

Meta发布AI翻译功能,支持脸书和Instagram内容实时转换
HPE发布Nvidia Blackwell驱动的AI服务器,抢占AI市场需求
ISACA推出AI安全管理高级认证项目
谷歌推出智能体SOC系统提升安全事件响应速度
Lumen升级400GB数据中心连接基础设施助力AI发展
AI和流媒体推动,2030年面临"网络危机"
Pine64停产Pro手机转向RISC-V业务
日立Vantara将VSP One块存储扩展至Azure云平台
Finchetto光学数据包交换机:光无法存储的技术挑战与突破
Python开发者调查显示增长强劲,但基金会资金面临困境
多站点IT基础设施升级指南:告别VMware的替代方案
戴尔集成Elasticsearch与英伟达Blackwell GPU升级AI数据平台
