
AI终端智能:人工智能AI的新革命
基于成本、能耗、可靠性和时延、隐私、个性化服务等考虑,端云混合的 AI 才是 AI 的未来,高通认为终端 AI 能力是赋能混合 AI 并让生成式 AI 实现全 球规模化扩展的关键。
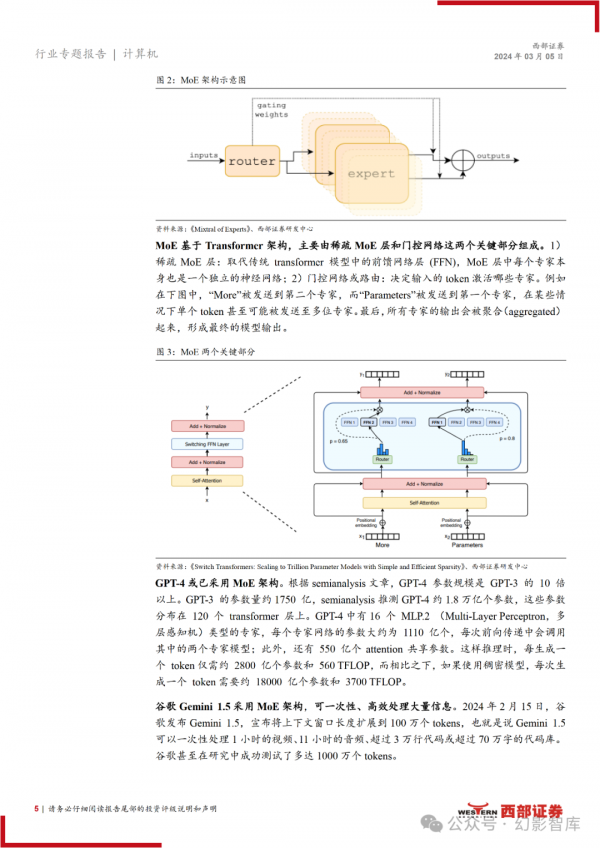
百亿参数开源 MoE 大模型 Mixtral 8x7B 再掀热潮,性能超 LLaMA2-70B,对 标 GPT-3.5。MoE(混合专家模型)通过将任务分配给对应的一组专家模型来 提高模型的性能和效率。Mixtral 8x7B 的专家数量为 8 个,总参数量为 470 亿, 但在推理过程中仅调用两个专家即只调用 130 亿参数。
我们认为 MoE 或为现阶段大模型平衡成本、延迟以及性能的最优选择,叠加 开源模型本身高灵活性、安全性和高性价比特点,Mistral AI 的开源 MoE 轻量 化模型可能是未来最适合部署于终端的模型。
目前,高通、联发科、英特尔、 AMD 等龙头芯片厂商都推出了终端 AI 芯片,能跑十亿甚至百亿量级大模型。后 续类 Mixtral 8x7B 的 SMoE 模型在高性能基础上继续压缩的话,很大几率可以 装进终端设备实现本地运行。

SMoE 轻量模型大幅降低了训练的门槛和成本, 且由于在推理时只激活少部分参数,保持较高性能的同时能适应不同的计算环 境,包括计算能力有限的终端,降低推理成本且将催生更多大模型相关应用。
2024 年有望成为终端智能元年,看好拥有终端资源、深耕场景、掌握行业 knowhow、积累了海量数据的 B 端和 C 端公司。
1)未来每台终端都将是 AI 终端,包括 AI PC、AI 手机、AI MR 等,这将带来全新的用户体验。
2)AI PC 有望成为“AI+”终端中最先爆发的。英特尔预计全球今年将交付 4000 万台 AI PC,明年将交付 6000 万台,预估 2025 年底 AI PC 在全球 PC 市场中占比将超 过 20%;微软 AI PC 预计于今年亮相。
3)随着大模型逐步发展,尤其是多模态 能力增强,更广泛的 AIoT 设备也迎来了更新换代的重要机遇。
4)B 端私有化 部署也是 AI 应用的重要方向,关注边缘侧 AI。
5)鸿蒙:提供顶级流畅连接体 验,大模型有望赋能奔赴万物智联下一站。
人形机器人是大模型应用的重要硬件载体,也是终端智能发展的核心方向。
1) 人形机器人是目前具身智能最好的形态,因为它们有着与人相似的外观设计, 能更好地适应周围的环境和基础设施。2)端云混合的“大脑”让机器人既能处理 复杂和高强度的计算任务,又能实时进行信息处理和分析。










好文章,需要你的鼓励


OpenAI与微软签署初步协议修订合作条款
OpenAI和微软宣布签署一项非约束性谅解备忘录,修订双方合作关系。随着两家公司在AI市场竞争客户并寻求新的基础设施合作伙伴,其关系日趋复杂。该协议涉及OpenAI从非营利组织向营利实体的重组计划,需要微软这一最大投资者的批准。双方表示将积极制定最终合同条款,共同致力于为所有人提供最佳AI工具。

让AI推理像人一样思考,但又要快得多:中山大学团队的“智能剪刀“如何给O1模型瘦身
中山大学团队针对OpenAI O1等长思考推理模型存在的"长度不和谐"问题,提出了O1-Pruner优化方法。该方法通过长度-和谐奖励机制和强化学习训练,成功将模型推理长度缩短30-40%,同时保持甚至提升准确率,显著降低了推理时间和计算成本,为高效AI推理提供了新的解决方案。

国产R1人形机器人亮相,挑战特斯拉Optimus霸主地位
中国科技企业发布了名为R1的人形机器人,直接对标特斯拉的Optimus机器人产品。这款新型机器人代表了中国在人工智能和机器人技术领域的最新突破,展现出与国际巨头竞争的实力。R1机器人的推出标志着全球人形机器人市场竞争进一步加剧。

视觉语言模型在自动驾驶中的可靠性大考验:上海AI实验室深度揭秘AI司机的真实水平
上海AI实验室研究团队深入调查了12种先进视觉语言模型在自动驾驶场景中的真实表现,发现这些AI系统经常在缺乏真实视觉理解的情况下生成看似合理的驾驶解释。通过DriveBench测试平台的全面评估,研究揭示了现有评估方法的重大缺陷,并为开发更可靠的AI驾驶系统提供了重要指导。

