
2024年AI终端白皮书:AI与人协作、服务于人
近年来,“生成式AI” 这一技术取得了引人注目的进展,如流行的ChatGPT、Gemini、Claude、盘古、文心一言、通义干问、讯飞星火、ChatGLM等。这些模型基于大型复杂的深度神经网络结构,采用互联网.上海量的数据训练,并辅以大量的人工反馈对模型进行优化和改进,最终训练出具有数十亿甚至数万亿个参数的模型。受益于海量数据、海量参数、海量算力的“规模定律( scaling law)”,生成式AI具有更好的表达能力和更泛化的任务能力。
生成式AI重塑了生产力,将在内容创作、软件开发、教育办公等多个领域大大提升人们的工作效率。同时,生成式Al还将赋予普通人“超能力”,戴.上具备AI能力的可穿戴设备,每个人都可以拥有远超人类物理感官精度、记忆效率、跨语言翻译等能力。
此外,由于生成式AI强大的“生成”能力,能够自动生成各种内容,如文字、图像、音乐和视频,大大地降低了各种任务的创作门槛,每个人都可以进行艺术设计、开发程序,甚至独立制作电影和小游戏。展望未来,我们正在进入AI塑造新的生产方式、生活模式以及思维方式的世界,数字化、智能化社会正在加速到来,站在这一变革的前沿,我们将以行践言,让每个人掌握Al的力量,体验技术变革带来的生产力和生活质量的飞跃。

AI产业趋势
生成式AI对各行各业的产业提升效应是巨大的,行业研究数据表明,随着企业改变经营方式并对产品和服务进行强化,到2032年,生成式Al有望在硬件、软件、服务、广告、游戏等众多.领域创造1.3万亿美元收入,占科技领域总支出从目前的不足1%扩大到10%-12%,复合年增长率达到约42%"。而在生成式AI对消费者的影响方面,一项针对全球 37个国家和地区的公众调查显示,2023年,认为人工智能将在未来三到五年内极大影响他们生活的人比例从60%上升到66%。此外,52%的人表示对人工智能的产品和服务感到紧张,比2022年.上升了13% , 36%的人认为在未来5年内,AI将取代自己的工作。人们对Al充满了既爱又怕的矛盾,既认同Al能够改变世界,又担心Al取代人,人类变成了机器的仆人。
AI与人协作、服务于人,是华为终端一贯坚持的技术理念。正如计算机帮助人类提升生产效率、手机帮助人类让沟通无处不在一样, AI 可以帮助人类突破自身身体局限,让自己看得更清、听得更清、记得更牢、理解得更透彻。同时,Al还能帮助人类增强、扩展信息的处理能力,面对海量信息,能够化繁为简,面对碎片信息,能够见微知著,面对无序信息,能够归纳推理。通过无处不在的全场景智能,华为终端致力于让Al帮助提升人的工作效率和生活品质,并赋予人们实现梦想和创造未来的能力。
当前,生成式AI技术与消费终端的融合正在加速,不断推动行业创新和社会变革。华为终端与多家顶尖智库、研究机构及学术高校合作,通过深入调研和分析,总结出了四大终端Al产业发展趋势。

多模态大模型带来更自然、更全面的人机交互体验
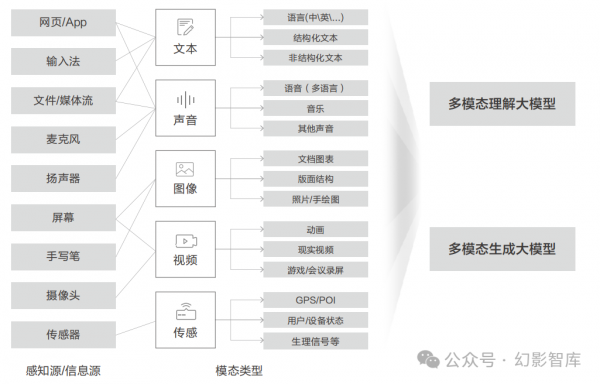
模态是指承载信息的模式或方式,不同类别的信息来源或形式都可以称为一种模态。模态基于人的感官可分为听觉、视觉、嗅觉、味觉、触觉,基于信息传递的媒介可分为图像、语音、视频、文本等,除此之外还有传感器的模态数据,如雷达、红外、GPS、加速度计等各种模态数据。人类生活在一个由多种模态信息构成的世界,会同时收到多个互补的、融合的、不同模态的感官输入,多模态更符合人类感知周边、探索世界的方式。
生成式Al为终端设备带来更自然、更全面、更多维的人机交互方式,打破了传统单一独立I/O通道输入方式的限制,极大地丰富了人机交互的维度。多模态理解大模型可以让用户使用文本、图像、声音、视频、传感等多种数据类型与终端进行交流,大大拓展了用户同终端的交互形式。多.模态生成大模型能够生成各种跨媒体内容,为用户提供更为直观的信息表达,从而实现更加高效丰.富的沟通体验。这也为更多样性的终端硬件形态如穿戴设备、机器人等提供了更有力的支撑。
AI终端智能化分级标准
Al为未来场景提供了可实现的技术手段,推动着创新快速发展和产品应用落地。近年来,随着生成式AI这一技术取得的显著进展,也引发了生成式AI同终端产品深度结合的创新浪潮:,从应用的角度看,各终端厂家和应用厂家密集推出基于大模型的AIGC应用产品,涵盖对话、写作、学习、媒体创作、办公商务等领域。
从硬件设备的角度看,各终端厂家的Al能力也在不断推陈出新,产业界也纷纷提出
Al终端、Al PC不同维度的概念定义。
为了让消费者对AI终端的能力有更清晰、更直观的认知,同时也为了让产业界对Al终.端的能力演进达成统-的共识,协同产业有序发展,参考汽车驾驶自动化分级,以及清华大学PERSONAL LLM AGENTS (个人大语言模型智能体) [10]中的智能体能力分级,我们提出Al终端智能化L1~L5分级标准,并期待产业界同仁一起来完善、优化该分级标准。

关键技术特征
针对Al终端分级标准,进一步高阶抽象出支撑该分级标准的Al终端六大关键技术特征。

报告原文内容节选如下:










好文章,需要你的鼓励


Glean年收入突破3亿美元,削减AI成本成核心卖点
企业AI搜索公司Glean宣布年度经常性收入(ARR)达3亿美元,较15个月前的1亿美元增长三倍。尽管谷歌、微软、OpenAI等科技巨头纷纷入局企业AI搜索市场,Glean凭借"上下文图谱"技术深度理解企业业务需求,并帮助客户显著降低AI计算成本。该公司提供按用量计费和混合定价两种模式,客户涵盖Databricks、Reddit、Pinterest及三星等企业。Glean上轮融资后估值达72亿美元。

香港中文大学与MiniMax联手破解AI图像描述的“说多错多、说少漏多“困局
香港中文大学与MiniMax提出ClaimDiff-RL框架,将图像描述的AI训练从整体打分升级为逐条核查,有效解决了传统方式导致AI"少说保平安"的问题,同时在多项基准测试上超越Gemini-3-Pro-Preview。

蓝色起源“新格伦“火箭在佛罗里达测试中发生爆炸
杰夫·贝索斯旗下的蓝色起源公司在佛罗里达卡纳维拉尔角进行静态点火测试时,新格伦重型火箭发生爆炸。这是美国历史上最大规模的火箭爆炸之一,也是蓝色起源公司遭遇的最严重失败。所有人员安全,但该事故可能导致新格伦火箭项目长期暂停。此前该火箭已成功完成三次发射,并实现了助推器回收和重复使用。

NTU、HKU等多所顶校联手,让AI同时“多角度看片“——视频理解的并行探针革命
ParaVT是一个由南洋理工等多校联合提出的并行视频工具调用框架,通过让AI同时分析多段视频并引入PARA-GRPO算法解决训练中的格式崩溃与工具跳过问题,在六项长视频理解测试中平均提升约7.9%。

