
极智芯 | 解读近存计算AI芯势力Groq LPU
当然,标题用了 "一语双关" 的手法,hhhh,Groq 的 LPU 是芯势力也是新势力。为啥这么说呢,说几个关键词可能会让大家更加感兴趣 ==> "推理效率较英伟达 GPU 提高 10 倍"、"近存计算"、"SRAM"。这里的整个 LPU 会 "充斥着" 近存计算、存算一体的面纱。
可能目前大家还对 Groq、对 Groq 的 LPU 不太了解,没事,我先来介绍一下 Groq。想火,"蹭热度" 可能是那个不太被推崇但又很常见的方式了,Groq 也喜欢蹭热度。在 Groq 的官网上就展示着喊话 OpenAI 奥特曼、Meta 扎克伯格、世界首富马斯克的帖子,希望这些巨头们不要只看英伟达,可以多关注一下 Groq 的 LPU。公然在自家官网上这么喊话,应该比较少见吧,感兴趣的朋友可以去看看。


Groq 当然是做 AI 芯片的公司,直接对标的就是 NVIDIA,这种定位基本就跟咱们一众国产 AI 芯片厂商类似了,对于国产 AI 芯感兴趣的朋友可以翻看一下我之前分享的解读内容《极智芯中国芯 | 全网最全解读国产AI算力产品矩阵系列》。Groq 就是致力于加速生成式 AI 的推理加速,是专门面向生成式 AI 的算法部署以达到实时推理的目标,下面是 Groq 愿景的原话:
Groq is on a mission to set the standard for GenAI inference speed, helping real-time AI applications come to life today.
Groq,你要说它新吧,它其实还真不新,Groq 成立于 2016 年,其创始团队主要来自 Google 的 TPU,所以在 Grop 的 LPU 上肯定是会有一些 TPU 的影子。其实 Google 的 TPU 也是一种近存计算 AI 芯片,而这里的 LPU 当然也会是近存计算芯片,因为 Grop 本身就是一家近存计算芯片公司,区别只是 LPU 按目前大模型的计算特点反馈到硬件上,将硬件做成了更加适配现在大模型计算特性的样子,所以 LPU 是会比 TPU 更加特定域的 AI 芯片,所以也就有了 Groq 愿景中的 "for GenAI inference speed",这里可以解读为 "Only for GenAI inference speed"。当然这可不是像某些 AI 芯片厂商那样在 "强蹭" 大模型的热度,而是 Groq LPU 确实太 "特定域" 了,只是对于生成式 AI、对于大模型的推理加速做的特别好。而要是你再说得大一点,比如说 LPU 对于 AI 推理加速性能好,那可真的未必,毕竟近存计算其实对于 AI 的另一个大头 - 卷积神经网络的密集型计算并不友好,它的优势主要就是在内存带宽上。这样讲下来应该会形成一个概念:"LPU 的好并不是全部的好",下面展示了 LPUs 对比 GPUs 的一些特点、优劣和适用场景。
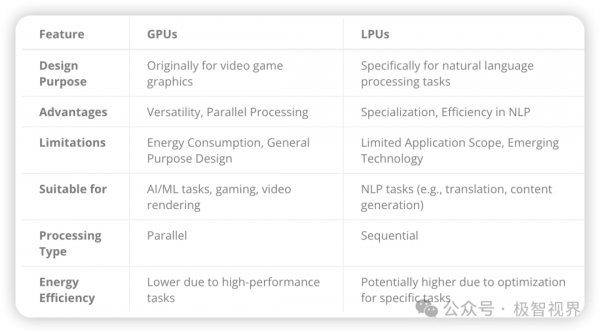
所以 LPU 相对于 GPU 来说,其实目标十分明确,主要想抓的就是 LLM 的契机,GPU 得益于其强大且数量庞大的计算核心 CUDA Core + Tensor Core 而在并行计算的各种任务中表现出色,而 LPU 得益于其遥遥领先的内存带宽水平而在 NLP + LLM 推理中表现突出。具体来说,Groq 的 LPU 能够以每秒超过 100 tokens 的推理速度来处理像 Llama-2 70B 这样的大语言模型,另外 LPU 对于现在很火的 Mixtral、Gemini 等大语言模型,也都有着超高的吞吐。而这些在 GPU 上就很难做到了,特别是考虑同样计算密集和价格的情况下,LPU 的表现尤为突出。

下面展示了 LPU 本身的 "Quality vs. Throughput, Price" 、"Throughput vs. Price" 以及 "Latency vs. Throughput",其实都是为了展示 LPU 在 LLM 上的卓越性能。
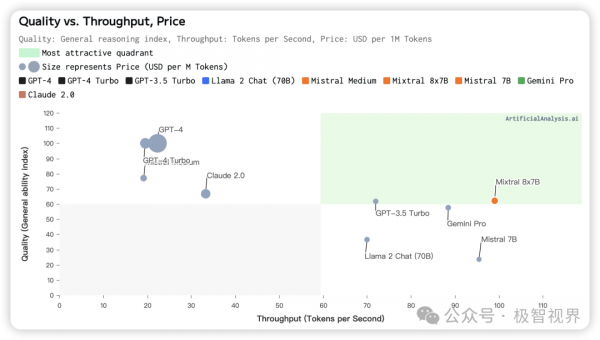
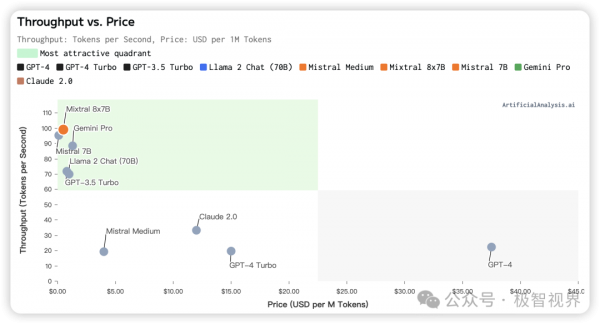
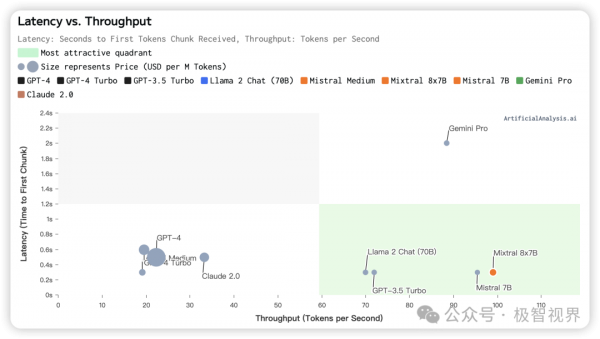
了解了 LPU 在 LLM 中的强悍性能之后,往底层来看一下 LPU 的架构,下面展示了 LPU 一个简单的架构图。

前面说到正是由于 Groq 的创始团队来自于 Google TPU,所以 LPU 的架构设计肯定离不开 TPU 的脉动阵列架构,实际也确实如此。介绍一下脉动阵列是怎么处理矩阵计算的,为了执行矩阵操作,将参数从 HBM 内存加载到矩阵乘法单元中,在每次执行乘法运算时,所得结果都会直接传递给下一个乘法累加器,输出是数据和参数之间所有乘法结果的总和,而在在矩阵乘法过程中,不需要再次访问内存了。下面展示了脉动阵列的计算 Pipeline 动画演示。

关于 LPU 架构设计更加具体的介绍,可以去翻翻 Groq 在 2020 年和 2021 年的下面两篇论文。

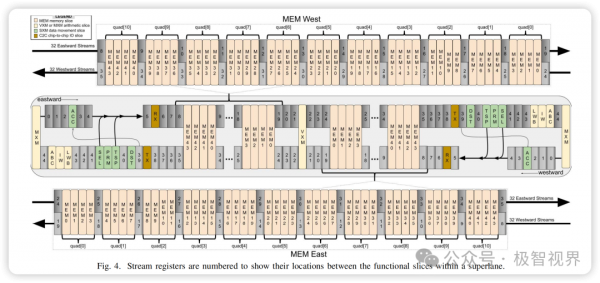

在了解了 LPU 的性能和架构之后,接着上升到产品级别,来看一下 LPU 这块卡的 "庐山真面目"。

下面整理了这张卡的主要特性参数,

整个性能参数表达的强烈信息就是:算力数据不错 (只能说不错,不能说很顶,参考 NVIDIA H100 稀疏算力 INT8@2000TOS),卡内内存带宽超高 (得益于近存计算,这个 80 TB/s 的带宽数据是好几倍于 H100 一倍的存在,但是需要注意的是卡内,LPU 卡间互联还是采用 x16 PCIE4.0,这肯定比不上 NVIDIA 的 NvLink)。
熟悉 AI 芯片产品矩阵的朋友应该会了解,在板卡之上,还会有服务器、云之类的算力产品形式,Grop 也类似,特别是云,基本是大模型时代算力很巴适的提供方式了。

好了,以上分享了 解读近存计算AI芯势力Groq LPU,希望我的分享能对你的学习有一点帮助。
好文章,需要你的鼓励

英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。

