
Llama-3公布基础训练设施,使用49,000个H100
3月13日,社交、科技巨头Meta在官网公布了两个全新的24K H100 GPU集群(49,152个),专门用于训练大模型Llama-3。
此外,Llama-3使用了RoCEv2网络,基于Tectonic/Hammerspace的NFS/FUSE网络存储,继续使用了PyTorch机器学习库。
从训练进度来看,估计Llama-3最快将于4月末或5月中旬上线。受Sora影响,很可能是一个多模态模型,并且会继续开源。
Meta表示,预计到2024年底,将拥有600,000个H100的算力。

Meta首席科学家确认
Meta庞大的AI算力集群
Meta作为全球市值最高的科技公司之一,对AI的投入一直非常大,致力于构建造福全人类的AGI(通用人工智能)。
早在2022年1月24日,Meta首次公布了AI 研究超级集群(RSC)的详细信息,拥有16,000个英伟达A100 GPU。
该集群在开发全球最受欢迎的类ChatGPT模型Llama和Llama 2,以及计算机视觉、NLP 和语音识别、图像生成等发挥了重要作用。

本次新增的GPU集群建立在RSC成功经验之上,每个集群包含24,576 个H100 GPU,能够支持比以往更复杂、参数更高的大模型训练。
集群网络
Meta每天要处理数百万亿次AI模型的请求,所以,使用一个高效、灵活的网络才能保证数据中心安全、稳定的运行。
一个集群是基于Arista7800、Wedge400和Minipack2 OCP 机架交换机,构建了一个具有融合以太网远程直接内存访问(RoCE) 网络结构的解决方案;
另外一个使用了NVIDIA Quantum2 InfiniBand结构,这两种方案都能互连 400 Gbps端点。

在两个不同集群帮助下,Meta可以评估不同类型的互联对大规模训练的适用性和可扩展性,为以后设计和构建更大、更大规模的集群提供更多经验。
此外,Meta已经成功地将 RoCE 和InfiniBand 集群用于大型生成式AI工作负载(包括正在RoCE 集群上对 Llama 3 进行的训练),并且没有出现任何网络瓶颈。
硬件平台
新增的两个集群全部使用Grand Teton,这是Meta内部设计的开放性 GPU 硬件平台,于2022年10月18日首次发布。

Grand Teton 建立在多代人工智能系统的基础上,将电源、控制、计算和结构接口集成到一个机箱中,以获得更好的整体性能、信号完整性和散热性能。具有简化的设计、灵活性,可快速部署到数据中心机群中,并易于维护和扩展等优点。
数据存储
随着大模型的功能趋于多模特,需要消耗大量的图像、视频、音频和文本数据,所以,对数据存储的需求迅速增长。
Meta新集群的存储部署通过自创的用户空间 Linux 文件系统API来满足人工智能集群的数据和检查点需求,该应用程序接口由 Meta 针对闪存媒体进行了优化的 Tectonic 分布式存储解决方案版本提供支持。
该解决方案使数千个 GPU 能够以同步方式保存和加载检查点(这对任何存储解决方案来说都是一个挑战),同时还提供了数据加载所需的灵活、高吞吐量的外字节级存储。
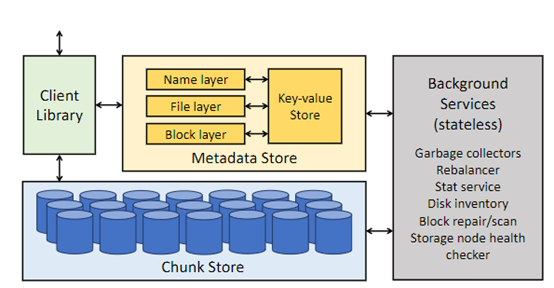
Meta还与 Hammerspace 合作,共同开发、部署并行网络文件系统 (NFS),以满足开发人员对超级AI集群的存储要求。
此外,Hammerspace 还能让工程师使用数千个 GPU 对作业进行交互式调试,因为环境中的所有节点都能立即访问代码更改。
将Meta的 Tectonic 分布式存储解决方案和 Hammerspace 结合在一起,可以在不影响规模的情况下实现快速功能迭代。
好文章,需要你的鼓励



Queen‘s大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官
Queen's大学研究团队提出结构化智能体软件工程框架SASE,重新定义人机协作模式。该框架将程序员角色从代码编写者转变为AI团队指挥者,建立双向咨询机制和标准化文档系统,解决AI编程中的质量控制难题,为软件工程向智能化协作时代转型提供系统性解决方案。

苹果发布 iOS 26.0.1 系统更新,修复多项关键问题
苹果在iOS 26公开发布两周后推出首个修复更新iOS 26.0.1,建议所有用户安装。由于重大版本发布通常伴随漏洞,许多用户此前选择安装iOS 18.7。尽管iOS 26经过数月测试,但更大用户基数能发现更多问题。新版本与iPhone 17等新机型同期发布,测试范围此前受限。预计苹果将继续发布后续修复版本。

医疗AI的“显微镜革命“:西北工业大学团队发布首个超声影像专用智能助手EchoVLM
西北工业大学与中山大学合作开发了首个超声专用AI视觉语言模型EchoVLM,通过收集15家医院20万病例和147万超声图像,采用专家混合架构,实现了比通用AI模型准确率提升10分以上的突破。该系统能自动生成超声报告、进行诊断分析和回答专业问题,为医生提供智能辅助,推动医疗AI向专业化发展。
2024
03/13
16:04
分享
点赞

