
国内AI算力:昇腾一马当先,各家竞相发展

昇腾已经在华为云和28 个城市的智能算力中心大规模部署,根据财联社报道,2022 年昇腾占据国内智算中心约 79%的市场份额。
本文来自“国产AI算力行业报告:浪潮汹涌,势不可挡(2024)”,相比于 GPT-3.5 是一个千亿参数模型,GPT-4 是拥有万亿规模参数,国内大模型厂商如果想追赶,需要各个维度要求都上一个台阶。
1. 昇腾计算产业链
华为主打 AI 芯片产品有 310 和 910B。310 偏推理,当前主打产品为 910B,拥有FP32 和 FP16 两种精度算力,可以满足大模型训练需求。910B 单卡和单台服务器性能对标 A800/A100。
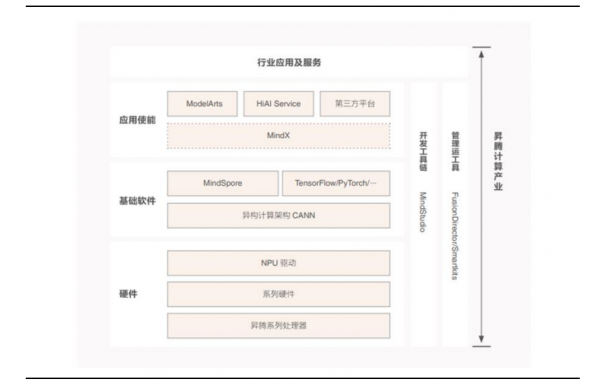
昇腾计算产业是基于昇腾 AI 芯片和基础软件构建的全栈 AI 计算基础设施、行业应用及服务,能为客户提供 AI 全家桶服务。主要包括昇腾 AI 芯片、系列硬件、CANN、AI 计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链。
硬件系统:基于华为达芬奇内核的昇腾系列 AI 芯片; 基于昇腾 AI 芯片的系列硬件产品,比如嵌入式模组、板卡、小站、服务器、集群等。
软件系统:异构计算架构 CANN 以及对应的调试调优工具、开发工具链 MindStudio 和各种运维管理工具等。Al 计算框架包括开源的 MindSpore,以及各种业界流行的框架。昇思 MindSpore AI 计算架构位居 AI 框架第一梯队。昇腾应用使能 MindX,可以支持上层的 ModelArts 和 HiAl 等应用使能服务。
行业应用是面向千行百业的场景应用软件和服务,如互联网推荐、自然语言处理、语音识别、机器人等各种场景
华为云盘古大模型 3.0 基于鲲鹏和昇腾为基础的 AI 算力云平台,以及异构计算架构 CANN、全场景 AI 框架昇思 MindSpore,AI 开发生产线 ModelArts 等,为客户提供100 亿参数、380 亿参数、710 亿参数和 1000 亿参数的系列化基础大模型。
盘古大模型致力于深耕行业,打造金融、政务、制造、矿山、气象、铁路等领域行业大模型和能力集,将行业知识 know-how 与大模型能力相结合,重塑千行百业,成为各组织、企业、个人的专家助手。
1.1. 昇腾服务器
华为昇腾整机合作伙伴与鲲鹏整机合作伙伴几乎一致,产线共用,从华为直接获取AI 服务器或者芯片板卡制造成服务器。
1.2. 昇腾一体机
AI 训推一体机是指将大模型等软件和普通 AI 服务器整合在一起对外销售的整机。主要为 AI 能力自建能力较弱,想要借助 AI 软硬件一体化解决方案构建AI 能力的客户。主要为 ISV,从华为整机厂拿到昇腾整机,然后装上 AI 模型和相关软件直接销售给终端使用客户。
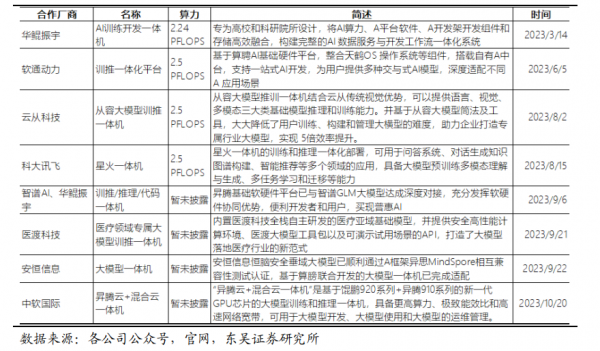
2. 海光信息
DCU 已经实现批量出货,迎来第二增长曲线。海光 DCU 以 GPGPU 架构为基础,兼容通用的“类 CUDA”环境,主要应用于计算密集型和人工智能领域。深算二号已经于 Q3 发布,实现了在大数据、人工智能、商业计算等领域的商用,深算二号具有全精度浮点数据和各种常见整型数据计算能力,性能相对于深算一号性能提升 100%。
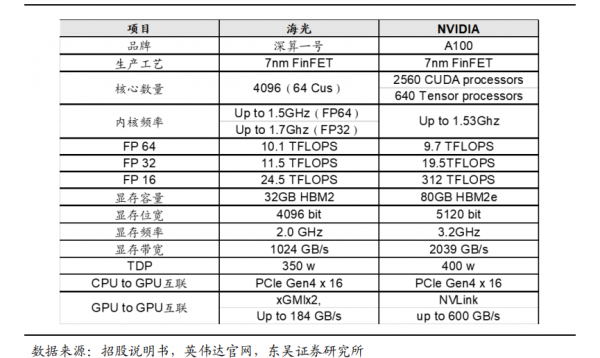
海光 DCU 产品性能可达到国际上同类型主流高端处理器的水平。深算一号采用先进的 7nm FinFET 工艺,能够充分挖掘应用的并发性,发挥其大规模并行计算的能力,快速开发高能效的应用程序。选取公司深算一号和国际领先 GPU 生产商 NVIDIA 公司高端 GPU 产品(型号为 A100)及 AMD 公司高端 GPU 产品(型号为 MI100)进行对比,可以发现典型应用场景下深算一号的性能指标可达到国际同类型高端产品的同期水平。
生态兼容性好。海光 DCU 协处理器全面兼容 AMD 的 ROCm GPU 计算生态,由于 ROCm 和 CUDA 在生态、编程环境等方面具有高度的相似性,CUDA 用户可以以较低代价快速迁移至 ROCm 平台,因此 ROCm 也被称为“类 CUDA”。因此,海光DCU 协处理器能够较好地适配、适应国际主流商业计算软件和人工智能软件。
海光 DCU 相比海外性价比较高,总体在国内领先。从性能、生态综合来看,海光DCU 处于国内领先水平,是国产 AI 加速处理器中少数大量销售,且支持全部精度的产品。
3. 寒武纪
寒武纪成立于 2016 年,专注于人工智能芯片产品的研发与技术创新,致力于打造人工智能领域的核心处理器芯片。寒武纪主要产品线包括云端产品线、边缘产品线、IP授权及软件。

寒武纪思元(MLU)系列云端智能加速卡与百川智能旗下的大模型 Baichuan2-53B、Baichuan2-13B、Baichuan2-7B 等已完成全面适配,寒武纪思元(MLU)系列产品性能均达到国际主流产品的水平。
2024 年 1 月 22 日,寒武纪与智象未来 (HiDream.ai) 在北京签订战略合作协议。寒武纪思元(MLU)系列云端智能加速卡与智象未来自研的“智象多模态大模型”已完成适配,在产品性能和图像质量方面均达到了国际主流产品的水平。
4. 景嘉微
2024 年 3 月 12 日,公司面向 AI 训练、AI 推理、科学计算等应用领域的景宏系列高性能智算模块及整机产品“景宏系列”研发成功,并将尽快面向市场推广。
好文章,需要你的鼓励


开创电气越南基地形成80万台手持式电动工具年产能力
今天讲的出海案例是开创电气,一家金华手持式电动工具制造商,在越南基地完成首款产品验收并形成80万台年产能力。

清华、浙大等高校联手破解AI智能体“只知结果不懂过程“的训练难题
清华、浙大等高校提出OPID框架,从AI自身完成的任务轨迹中提炼层级化经验技能,转化为密集训练信号,解决强化学习中稀疏奖励难以精细指导决策的问题。

一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

数AI也能画画?Surrey大学与Simon Fraser大学打造的“算盘“模型,让机器真正学会了“数数“
萨里大学与西蒙菲莎大学联合提出ABACUS模型,首次将物体计数、人群计数、指代计数与精准图像生成统一在单个30亿参数模型中,七项基准全面超越现有专业模型。
2024
04/09
15:04
分享
点赞

