
浪潮信息发布 “源2.0-M32” 开源大模型,大幅提升模算效率
5月28日,浪潮信息发布“源2.0-M32”开源大模型。“源2.0-M32”在基于“源2.0”系列大模型已有工作基础上,创新性地提出和采用了“基于注意力机制的门控网络”技术,构建包含32个专家(Expert)的混合专家模型(MoE),并大幅提升了模型算力效率,模型运行时激活参数为37亿,在业界主流基准评测中性能全面对标700亿参数的LLaMA3开源大模型。

在算法层面,源2.0-M32提出并采用了一种新型的算法结构:基于注意力机制的门控网络(Attention Router),针对MoE模型核心的专家调度策略,这种新的算法结构关注专家模型之间的协同性度量,有效解决传统门控网络下,选择两个或多个专家参与计算时关联性缺失的问题,使得专家之间协同处理数据的水平大为提升。源2.0-M32采用源2.0-2B为基础模型设计,沿用并融合局部过滤增强的注意力机制(LFA, Localized Filtering-based Attention),通过先学习相邻词之间的关联性,然后再计算全局关联性的方法,能够更好地学习到自然语言的局部和全局的语言特征,对于自然语言的关联语义理解更准确,进而提升了模型精度。
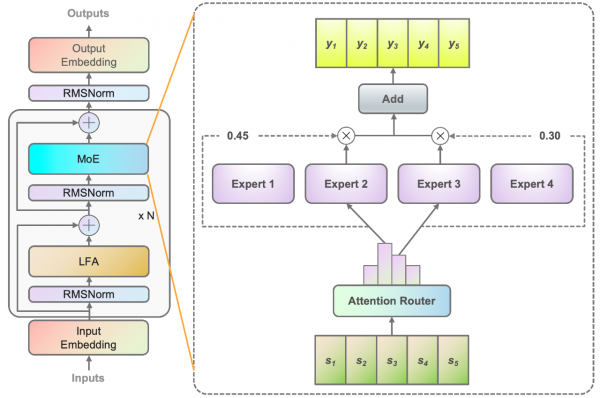
Figure1- 基于注意力机制的门控网络(Attention Router)
在数据层面,源2.0-M32基于超过2万亿的token进行训练、覆盖万亿量级的代码、中英文书籍、百科、论文及合成数据。大幅扩展代码数据占比至47.5%,从6类最流行的代码扩充至619类,并通过对代码中英文注释的翻译,将中文代码数据量增大至1800亿token。结合高效的数据清洗流程,满足大模型训练“丰富性、全面性、高质量”的数据集需求。基于这些数据的整合和扩展,源2.0-M32在代码生成、代码理解、代码推理、数学求解等方面有着出色的表现。
在算力层面,源2.0-M32采用了流水并行的方法,综合运用流水线并行+数据并行的策略,显著降低了大模型对芯片间P2P带宽的需求,为硬件差异较大训练环境提供了一种高性能的训练方法。针对MOE模型的稀疏专家计算,采用合并矩阵乘法的方法,模算效率得到大幅提升。
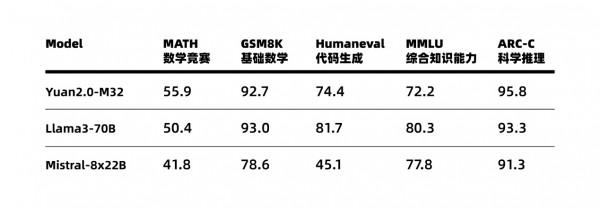
基于在算法、数据和算力方面全面创新,源2.0-M32的性能得以大幅提升,在多个业界主流的评测任务中,展示出了较为先进的能力表现,在MATH(数学竞赛)、ARC-C(科学推理)榜单上超越了拥有700亿参数的LLaMA3大模型。
Figure2 源2.0-M32业界主流评测任务表现
源2.0-M32大幅提升了模型算力效率,在实现与业界领先开源大模型性能相当的同时,显著降低了在模型训练、微调和推理所需的算力开销。在模型推理运行阶段,M32处理每token所需算力为7.4GFLOPs,而LLaMA3-70B所需算力为140GFLOPs。在模型微调训练阶段,对1万条平均长度为1024 token的样本进行全量微调,M32消耗算力约0.0026PD(PetaFLOPs/s-day),而LLaMA3消耗算力约为0.05PD。M32凭借特别优化设计的模型架构,在仅激活37亿参数的情况下,取得了和700亿参数LLaMA3相当的性能水平,而所消耗算力仅相为LLaMA3的1/19,从而实现了更高的模算效率。
浪潮信息人工智能首席科学家吴韶华表示:当前业界大模型在性能不断提升的同时,也面临着所消耗算力大幅攀升的问题,对企业落地应用大模型带来了极大的困难和挑战。源2.0-M32是浪潮信息在大模型领域持续耕耘的最新探索成果,通过在算法、数据、算力等方面的全面创新,M32不仅可以提供与业界领先开源大模型相当的性能,更可以大幅降低大模型所需算力消耗。大幅提升的模算效率将为企业开发应用生成式AI提供模型高性能、算力低门槛的高效路径。M32开源大模型配合企业大模型开发平台EPAI(Enterprise Platform of AI),将助力企业实现更快的技术迭代与高效的应用落地,为人工智能产业的发展提供坚实的底座和成长的土壤,加速产业智能化进程。
源2.0-M32将持续采用全面开源策略,全系列模型参数和代码均可免费下载使用。
- 代码开源链接:https://github.com/IEIT-Yuan/Yuan2.0-M32
- 模型下载链接:
- Huggingface:
https://huggingface.co/IEITYuan/Yuan2-M32-hf
- ModelScope:
https://modelscope.cn/models/YuanLLM/Yuan2-M32-hf/summary
来源:业界供稿
好文章,需要你的鼓励



腾讯混元视觉团队打造“图像翻译官“:让AI用离散数字读懂每一张照片
腾讯等机构提出ViQ框架,通过两阶段渐进量化训练,让离散视觉编码在多模态理解和图像重建上同时追平连续特征编码器,训练速度最高提升70%。

Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
作者对Chrome、Edge和Firefox三款主流浏览器的内置AI功能进行了实测对比。Chrome依托Gemini提供搜索摘要与提示词保存功能;Edge集成Copilot,可针对网页、PDF及多标签页进行问答;Firefox则支持多款AI聊天机器人,并提供更强的隐私保护。综合体验后,作者最终选择Edge作为AI辅助浏览的首选,但仍以Firefox作为默认浏览器。

香港科技大学联手华为研究院:AI绘图训练速度提升2.78倍,秘诀藏在“概率分工“里
香港科技大学与华为联合提出LISA训练方法,通过让副网络对齐"似然分数",将ControlNet等图像生成模型的训练收敛速度提升逾2.78倍,同时改善图像质量与条件控制精度。
2024
05/28
20:14
分享
点赞

Chrome、Edge、Firefox 浏览器 AI 功能横评,我最终选了这款
Firefly宇航公司首次在月球轨道运行NVIDIA Jetson平台
超越数据驱动美学:计算与审美的跨世纪探索
韩国携手三星和SK海力士启动5840亿美元芯片制造计划
Gemini 个性化 AI 图像生成功能现向美国用户免费开放
HP与OpenAI达成合作,共同部署企业级AI智能体平台
Windows 10 用户最长可免费获得安全更新至 2027 年
Raise Us:AI巨头联合出资5亿美元帮助劳动者应对AI时代冲击
MIT首届音乐科技研究展:AI与音乐共创的跨学科探索
特斯拉"完全自动驾驶"集体诉讼引用Electrek报道作为证据
福特3万美元电动皮卡再度现身测试路段
美国最大变压器工厂扩建,剑指AI数据中心用电需求
国内首款42kW智算风冷算力仓!能投天府云与浪潮信息联合发布
服务器定制备料分分钟完成!浪潮信息超大智能立体仓库投入运营
浪潮信息与龙蜥社区联合发布!服务器操作系统KOS V5.8,并推出“停更无忧”计划
浪潮信息与五家算力运营公司在南京签署战略合作 加速华东智算基础设施布局
分布式数据库时代,需要什么样的产品?浪潮信息携手腾讯云给出答案!
CCF信息存储技术专委会走进浪潮信息 共话大模型时代的存储创新之道
独辟蹊径 浪潮信息 “源2.0-M32”多维度提升模型算力效率
浪潮信息发布 “源2.0-M32” 开源大模型,大幅提升模算效率
为大模型专门优化!浪潮信息发布分布式全闪存储AS13000G7-N系列
浪潮信息彭震:激发创新活力,加速AI落地
