
阿里Qwen-2成全球开源大模型排行榜第一,中国处于领导地位。
6月27日凌晨,全球著名开源平台huggingface(笑脸)的联合创始人兼首席执行官Clem在社交平台宣布,阿里最新开源的Qwen2-72B指令微调版本,成为开源模型排行榜第一名。
他表示,为了提供全新的开源大模型排行榜,使用了300块H100对目前全球100多个主流开源大模型,例如,Qwen2、Llama-3、mixtral、Phi-3等,在BBH、MUSR、MMLU-PRO、GPQA等基准测试集上进行了全新评估。
重新评估的原因是,目前开发者太注重排行榜的名次,在训练过程中使用了很多评估集的数据,并且之前的评估流程对于那些模型来说太简单了,所以,本次给这些模型加大了难度,想看看它们的真正实力。
结果显示,阿里开源的Qwen-2 72B力压科技、社交巨头Meta的Llama-3、法国著名大模型平台Mistralai的Mixtral成为新的王者,中国在全球开源大模型领域处于领导地位。
Qwen-2开源地址:https://huggingface.co/Qwen/Qwen2-72B-Instruct
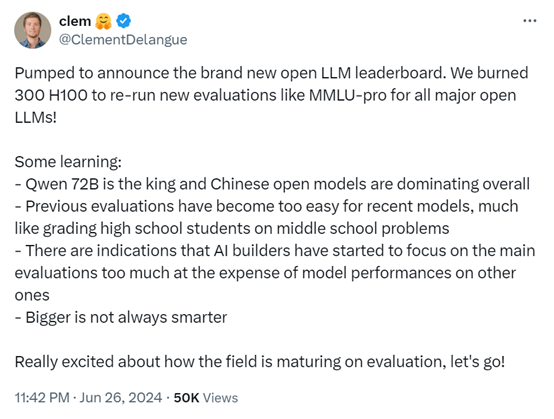
根据排行榜的数据显示,Meta开源的Llama-3-70B指令微调版本位列第2;阿里的Qwen2-72B基础版本排名第3;Mistralai的Mixtral-8x22B指令微调版本排名第4;
微软最新开源的小参数模型Phi-3-Medium-4K 14B排名第五,这说明小参数模型经过高质量数据集的预训练,同样能实现媲美大参数模型的能力。
中国零一万物最新开源的Yi-1.5-34B-Chat版本排在了第六名;知名大模型平台Cohere开源带RAG功能的Command R+ 104B排名第7;
英伟达开源的Smaug-72B-v0.1曾经排名第一,但在新的排行榜只有第8名;第9和第10名,全部都是阿里之前开源的Qwen1.5基础和Chat版本。
所以,全新排行榜的前10名竞争非常激烈,很多都是当过之前排行榜第一名的高手,相当于大模型界的“华山论剑”。
阿里开源的4款大模型傲视群雄,无愧于“中神通”的名号,这也充分说明中国对全球开源大模型的重要贡献以及领导地位。
对于这个排名结果,StabilityAI的研究总监,19岁便获得博士学位的Tanishq表示,他很早就说过中国在开源大模型领域非常有竞争力,除了Qwen2,还有零一万物、InternLM、Deepsseek等很多知名的开源模型。
关于中国在开源大模型领域处于落后状态简直可笑,相反,他们却处于领导者地位。
对于阿里Qwen-2取得如此高的成绩,确实让很多人感到惊讶,但事实结果就是这样。
他们也把希望寄托在Meta身上了,赶紧发布点新模型和Qwen-2再来一次大PK。

其实,不只是huggingface,曾经就有人发布过ElyzaTasks100性能评测,Qwen2-72B的指令微调版本也是性能最高的开源大模型,仅次于OpenAI的GPT-4o,高于谷歌的Gemini1.5Pro。
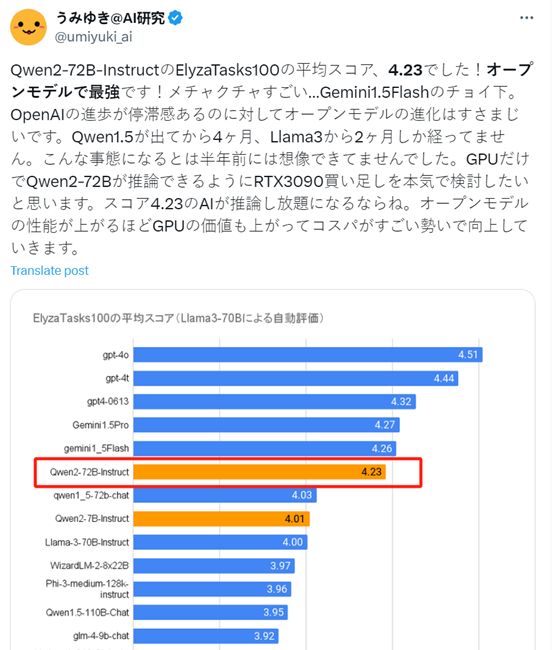
其实在与OpenAI、Anthropic这两家著名闭源大模型平台进行PK时,Qwen2-72B指令微调版本也丝毫不落下风,也是中国唯一进入美国评估标准前10的国内公司。
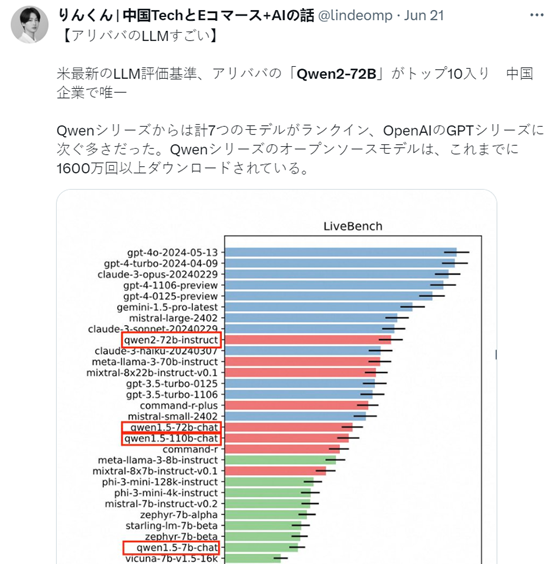
希望阿里砥砺前行,更上一层楼。期待未来发布更多高性能的开源大模型,造福全人类。
来源:AIGC开放社区
好文章,需要你的鼓励


奥运级别的努力:首席信息官为2026年AI颠覆做准备
AI颠覆预计将在2026年持续,推动企业适应不断演进的技术并扩大规模。国际奥委会、Moderna和Sportradar的领导者在纽约路透社峰会上分享了他们的AI策略。讨论焦点包括自建AI与购买第三方资源的选择,AI在内部流程优化和外部产品开发中的应用,以及小型模型在日常应用中的潜力。专家建议,企业应将AI建设融入企业文化,以创新而非成本节约为驱动力。

字节跳动发布GAR:让AI能像人类一样精准理解图像任何区域的突破性技术
字节跳动等机构联合发布GAR技术,让AI能同时理解图像的全局和局部信息,实现对多个区域间复杂关系的准确分析。该技术通过RoI对齐特征重放方法,在保持全局视野的同时提取精确细节,在多项测试中表现出色,甚至在某些指标上超越了体积更大的模型,为AI视觉理解能力带来重要突破。

Spotify推出AI播放列表功能让用户掌控推荐算法
Spotify在新西兰测试推出AI提示播放列表功能,用户可通过文字描述需求让AI根据指令和听歌历史生成个性化播放列表。该功能允许用户设置定期刷新,相当于创建可控制算法的每周发现播放列表。这是Spotify赋予用户更多控制权努力的一部分,此前其AI DJ功能也增加了语音提示选项,反映了各平台让用户更好控制算法推荐的趋势。

Inclusion AI推出万亿参数思维模型Ring-1T:首个开源的超大规模推理引擎如何重塑AI思考边界
Inclusion AI团队推出首个开源万亿参数思维模型Ring-1T,通过IcePop、C3PO++和ASystem三项核心技术突破,解决了超大规模强化学习训练的稳定性和效率难题。该模型在AIME-2025获得93.4分,IMO-2025达到银牌水平,CodeForces获得2088分,展现出卓越的数学推理和编程能力,为AI推理能力发展树立了新的里程碑。
2024
06/28
21:04
分享
点赞

