
GPT-4o发挥重要作用,赢得第一届AIMO进步奖!开源大模型数据集
在今年的7月11日,全球著名开源大模型分享平台Hugging Face与专业数学大模型平台Numina合作,共同角逐AIMO(人工智能奥林匹克竞赛)第一届进步奖。
本次大赛有81个国家/地区,1161支队伍共计16100人参加。Numina一路披荆斩棘、过关斩将,在50道超难的数学竞赛题中,其AI模型回答对了29道比第二名多出7道顺利拿下第一名。
随后,Numina宣布开源其参赛大模型NuminaMath 7B TIR,并深度分享了训练该模型的方法、流程以及如何避免过拟合性、过度压缩等,但当时并没有开源训练数据集。
数据集开源地址:https://github.com/project-numina/aimo-progress-prize
在线demo:https://huggingface.co/spaces/AI-MO/math-olympiad-solver
模型开源地址:https://huggingface.co/AI-MO/NuminaMath-7B-TIR
 Numina获奖信息
Numina获奖信息
7月21日晚,Numina联合创始人、前Mistral AI科学家-Li Jia在社交平台宣布,正式开源了NuminaMath 7B TIR的训练数据集——NuminaMath。
高质量训练数据集对于开发人员来说,其帮助性有时甚至超过了模型架构本身。根据微软、Meta、谷歌等科技巨头开源的小模型显示,在高质量数据的洗礼下,即便是参数很小但性能依然可以媲美、超过大参数模型,而部署、推理成本却大幅度下降。
Li Jia表示,NuminaMath是迄今为止最大的数学竞赛数据集,共有86万个数学竞赛题组成,可帮助开发者大幅度提升其模型的数学能力。
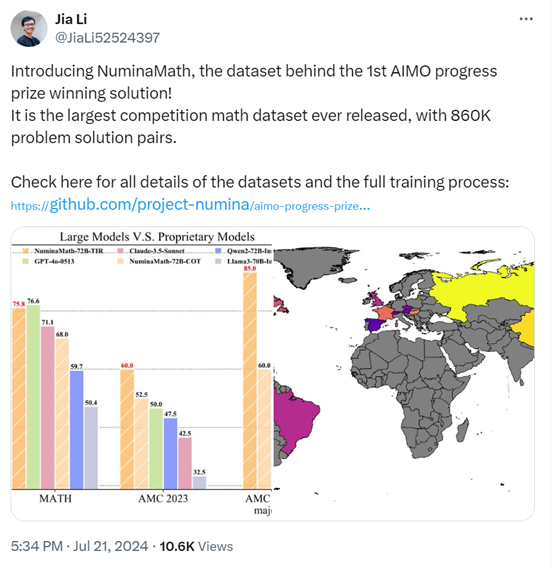
根据NuminaMath的技术报告显示,GPT-4o凭借其强大的理解、生成等多模态能力,在构建、翻译、数据格式化、集成推理、合成数据、链式思考注释等多个模块发挥了重要作用。
研究人员搜集了多数国家的专业数学竞赛题,从MATH、GSM8K、Orca-Math再到AMC、AIME等专业大赛共计86万个。这些数学题横跨了从基础到复杂的所有难度级别,确保了数据集的全面性。
但是搜集到的数学题中多数都是PDF格式的,提取复杂公式和符号非常麻烦。所以,研究人员又基于OCR(光学字符识别)发了专有算法,极大地提升了数学公式和符号的识别精度,确保了题目和答案的准确无损提取。
在提取到原始数据后,通过GPT-4o强大的语言理解能力对NuminaMath数据集进行了大量转换,包括使用统一的格式表示常见的数学符号,例如,积分、极限、导数等,同时将非英文题目统一翻译成英文,满足了国际化大模型的训练需求。
为了维护数据集的纯净度和有效性,研究人员实施了严格的内部验证流程,利用精确字符串匹配和基于嵌入的最近邻搜索技术,检测并移除重复或受污染的题目。尤其对于AMC和AIME这类专业数据源,采取了额外的去污染措施确保了数据的高质量。

此外,为帮助大模型能更深层次地理解数学解题逻辑,NuminaMath数据集采用了链式思考(CoT)格式,这意味着每个解答都详尽地记录了解题步骤与推理过程可以有效学习解决数学题的思维路径并非仅呈现最终答案,在训练模型、应用场景化落地方面帮助非常有帮助。
为了扩展NuminaMath数据集的规模和多样性,GPT-4o还被用于生成合成数据。通过使用现有的数学题作为种子,GPT-4o能够生成新的数学问题和相应的解决方案,有效引入了新的数学概念和题目类型,从而提高了数据集的覆盖面和深度。
在传统的大语言模型中,推理的过程往往依赖于模型内部的逻辑和知识,在处理一些需要精确计算或验证的数学问题时可能会出现不准确的情况。
所以,研究人员在推理阶段又引入了TIR(Tool-Integrated Reasoning)模块,将传统的文本推理与程序执行相结合,这种方法不仅需要模型理解问题的文字描述,还要求它能够生成并执行代码,以验证其推理过程的正确性。
构建TIR模块的第一步是从NuminaMath-CoT数据集中提取问题和解决方案。研究人员从这个数据集中,挑选了大约100,000个具有明确数值输出的问题,这些问题覆盖了从基础数学到高级竞赛级别的广泛主题。
然后使用GPT-4o为每个问题生成解决方案,来增加生成解决方案的多样性和正确性。对于整数输出问题,使用精确匹配;对于其他表达式,则通过GPT-4o作为裁判来判断匹配度。
在生成解决方案的过程中,TIR模块还会生成相应的Python代码。不仅需要能够执行,还需要能够产生正确的输出以验证数学题的准确度。
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2024
07/23
19:04
分享
点赞

