
Meta的Llama-3.1-405B遭泄漏,可下载,性能超GPT-4o!
7月23日凌晨,有人爆料,Meta的Llama 3.1-405B评测数据遭遇泄漏,明天可能会发布Llama 3系列中最大的参数模型,同时还会发布一个Llama 3.1-70B版本。
这也是在3.0版本基础之上进行了功能迭代,即便是70B的基础模型的性能也超过了GPT-4o。

就连磁力链接都流出来了,试了一下大约有763.84G。本来huggingface上也有的,后来库被删除了。
磁力地址:Magnet: magnet:?xt=urn:btih:c0e342ae5677582f92c52d8019cc32e1f86f1d83&dn=miqu-2&tr=udp%3A%2F%http://2Ftracker.openbittorrent.com%3A80
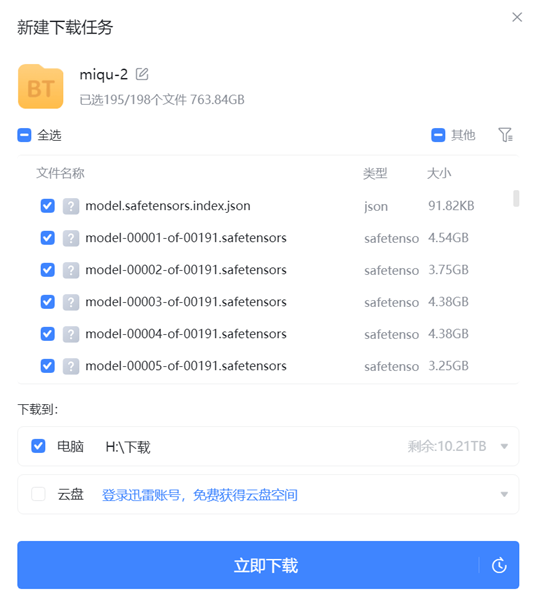
下载速度也还可以,每秒14M左右,看来确实是有不少人在下这个模型。

但这个模型一般的GPU肯定是跑不起来,如此大的参数在部署方面个人开发者也负担不起(如果你有一些H100也没问题),估计是给企业、政务公共部门用的。
对于Meta即将发布的模型,就有网友泼冷水。相比OpenAI最新的GPT-4o mini版本,Llama 3.1-70B推理成本提升了3倍,但编码的性能却要差很多。
从性价比、功能来看,Meta的新模型也没什么值得期待的。
还有人甚至在GitHub上看到了上述发布的模型,但很快就拿下来了,估计有一些人可能已经能使用了。

也有人表示,对于这个泄漏事件他认为是真的,因为这是从微软的Azure Github流出来的。

但是这个模型参数较大,对GPU的要求太高了,不如GPT-4o mini性价比高。

虽然模型是免费的,想运行起来还是相当费劲的,没有企业级的算力基础真的无法使用。所以,这对于企业来说是一个不错的好消息。
有人指出即便对Llama 3.1-405B模型进行大幅度优化,量化到5位数,仍然无法适用于消费级GPU,真的是对硬件要求特别高。
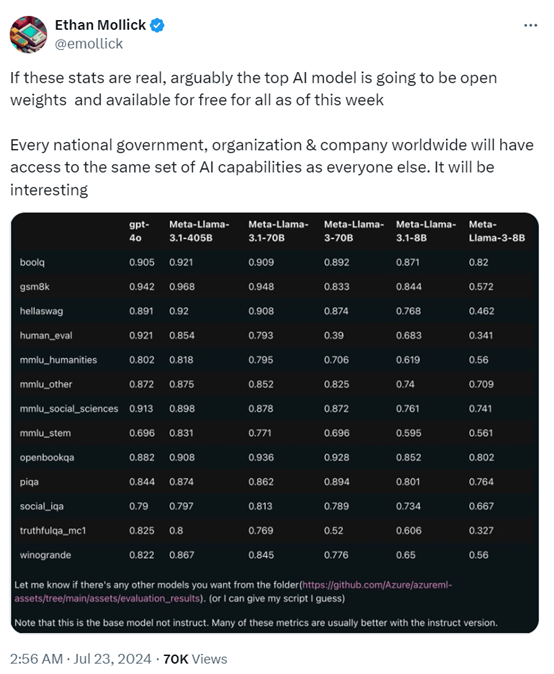
如果这份评测数据是真的,那么对于全球多数国家来说都是一个天大的福利。因为这是Meta的Llama 3系列的顶级模型并且是全部开放权重,也就是说人人都能用上免费的AI模型。
但是如果想开发生成式AI应用,也需要强大的AI算力基础、高质量数据以及微调技术。
由于监管机构和各种法案的原因,Meta一直在推迟405B系列模型的发布。那么,本次泄漏是否是Meta特意放出来的呢,因为这是他们的老传统了,去年的Llama模型就干过一次。
来源:AIGC开放社区
好文章,需要你的鼓励


苹果注重隐私的年龄验证方案可解决两大难题
美国多州和部分国家要求特定应用进行年龄验证,澳大利亚已禁止16岁以下用户使用社交媒体。新提案《应用商店问责法案》建议由苹果和谷歌负责统一验证用户年龄,而非各开发者单独验证。这将提升用户体验,用户只需向苹果或谷歌验证一次身份。凭借苹果在隐私保护方面的优势,该方案可扩展至Safari浏览器,为需要年龄验证的网站提供确认信息,而无需透露用户个人数据。

Meta AI团队首次破解多模态奖励模型评估难题,让AI既能看懂图片又能准确判断好坏
Meta AI首次发布多模态奖励评估基准MMRB2,专门评价AI同时处理文字和图像的能力。该基准包含四大任务类型共4000个专家标注样本,测试23个先进模型。结果显示最佳模型Gemini 3 Pro达75-80%准确率,仍低于人类90%水平。研究揭示AI评价存在视觉偏见等问题,为多模态AI发展提供重要参考标准。

Cursor通过收购Graphite继续扩张之路
AI编程助手Cursor背后的公司Anysphere宣布收购AI代码审查工具初创公司Graphite。据报道收购价远超Graphite今年早些时候B轮融资时2.9亿美元的估值。此次收购具有战略意义,将AI代码生成与AI代码审查工具相结合,可大幅提升从编写到交付的整体效率。Anysphere估值已达290亿美元,近期频繁收购,上月收购技术招聘公司,今年7月还收购AI客户关系管理初创公司Koala的团队。

快手推出Kling-Omni:一个AI模型搞定所有视频制作需求
快手推出的Kling-Omni是首个真正统一的AI视频制作系统,能够理解文字、图像、视频等多种输入方式,不仅可以生成视频,还能进行复杂编辑和推理。该系统通过三个核心模块的协作,实现了从创意理解到最终输出的全流程自动化,让普通用户也能制作专业水准的视频内容,代表了AI视频技术的重要突破。
2024
07/24
11:04
分享
点赞

