商汤、清华、复旦等开源百亿级多模态数据集,可训练类GPT-4o模型
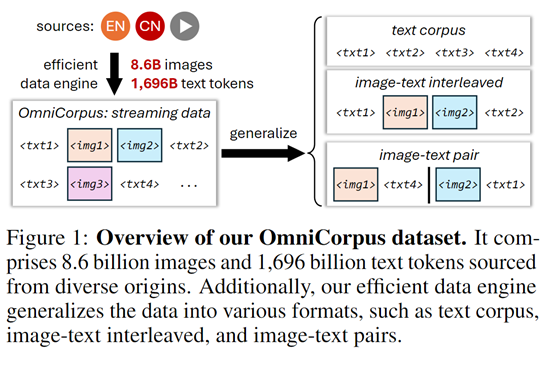
商汤科技等机构联合开源了百亿级图文交错数据集OmniCorpus,规模是现有数据集的15倍,包含86亿张图像和16,960亿个文本标记。OmniCorpus数据集在多语言、多类型数据抓取上进行了优化,提高了内容提取的质量和完整性。通过人工反馈和自动过滤规则,确保了数据集的高质量。在VQA和Image Captioning等测试中,基于OmniCorpus预训练的模型表现出色,对训练多模态大模型有重要帮助。
商汤科技、清华大学、上海AI实验室、哈尔滨工业大学、香港中文大学、复旦大学和南京大学的研究人员联合开源了百亿级图文交错数据集——OmniCorpus。
与现有的MMC4、OBELICS等数据集相比,OmniCorpus在规模上扩大了15倍,包含86 亿张图像和16,960亿个文本标记。在数据质量上同样出色,不仅涵盖了英语网站,还包含了非英语网站及视频为中心的平台,确保了内容的广泛性和丰富性。
此外,OmniCorpus还可以从图像文本交织格式轻松降级为纯文本语料库或图像文本对,以满足不同领域研究需求。
开源地址:https://github.com/OpenGVLab/OmniCorpus
论文地址:https://arxiv.org/abs/2406.08418
为了抓取不同语言、类型的数据,研究人员对Trafilatura工具进行了优化,能够更准确地识别和提取HTML文档中的主要内容区域,同时处理更多语言的数据。
还增强了对图像的提取能力,确保了在没有足够文本内容的情况下,能够基于HTML结构的密度来增强部分区域,显著提高了内容提取的质量和完整性。
在提取到主题数据之后进入初步的文本过滤阶段,目的是去除那些质量极低的文档,包含大量数字、文本过长或过短填充文本的文档。
研究人员使用了Gopher和C4策略,并引入了一些启发式规则,例如,去除连续行数过多或单个词频过高的文档等,有效减少了数据集中的冗余。
随后又进行了图像过滤,包括模糊、尺寸、宽高比不合适的图像。根据LAION-5B的指导方针,任何审美分数低于3.7或NSFW分数高于0.8的图像也将被排除,确保了图像数据的质量和相关性。
为了进一步提升OmniCorpus数据集的质量,还引入了人工反馈机制会根据完整性、可理解性、流畅性、相关性和安全性等标准,对文档的子集进行大规模采样。然后手动设计额外的过滤规则,进一步去除低质量文档。
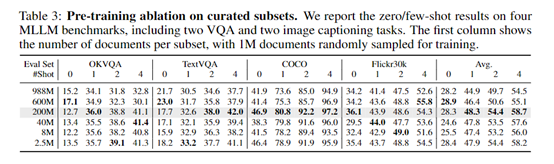
为了评估OmniCorpus数据集的性能,研究人员在VQA、Image Captioning、MLLM等测试平台上进行了综合测试。
在VQA视觉问答的众多子任务中,基于OmniCorpus数据集预训练的模型展现了强大的性能,不仅能够准确识别图像中的对象和场景,还能够理解问题的上下文给出准确的答案。
例如,在VQAv2测试中,模型的平均准确率达到了81.2%,在TextVQA上达到了61.7%,这比之前的训练数据集得分更高。
在Image Captioning测试任务中,OmniCorpus数据集的多样性和丰富性为模型提供了广泛的训练样本,使其能够捕捉到图像中的主要对象和事件,并理解和表达图像中的细节和情感。
在COCO Caption和Flickr30K Caption这两个图像描述基准测试中,基于OmniCorpus数据集预训练的模型生成的描述在质量和准确性上都有显著提升。所以,OmniCorpus数据集对于训练类似GPT-4o、Gemini等多模态大模型有很大的帮助。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
阿里云第九代企业级ECS实例g9i不到150天服务超2万家客户,现在已有接近3万用户。
Queen's大学研究团队提出结构化智能体软件工程框架SASE,重新定义人机协作模式。该框架将程序员角色从代码编写者转变为AI团队指挥者,建立双向咨询机制和标准化文档系统,解决AI编程中的质量控制难题,为软件工程向智能化协作时代转型提供系统性解决方案。
苹果在iOS 26公开发布两周后推出首个修复更新iOS 26.0.1,建议所有用户安装。由于重大版本发布通常伴随漏洞,许多用户此前选择安装iOS 18.7。尽管iOS 26经过数月测试,但更大用户基数能发现更多问题。新版本与iPhone 17等新机型同期发布,测试范围此前受限。预计苹果将继续发布后续修复版本。
西北工业大学与中山大学合作开发了首个超声专用AI视觉语言模型EchoVLM,通过收集15家医院20万病例和147万超声图像,采用专家混合架构,实现了比通用AI模型准确率提升10分以上的突破。该系统能自动生成超声报告、进行诊断分析和回答专业问题,为医生提供智能辅助,推动医疗AI向专业化发展。