
Qwen2-VL:阿里巴巴云计算团队开发的多模态大型语言模型系列
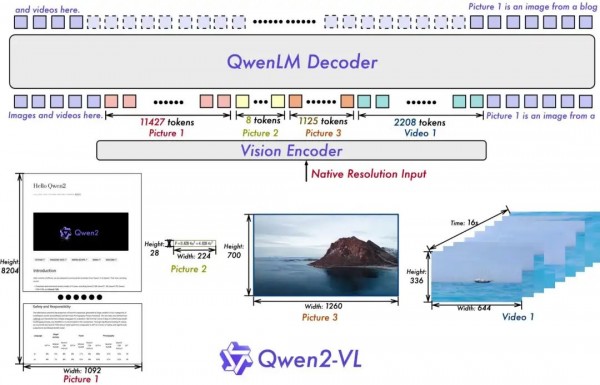
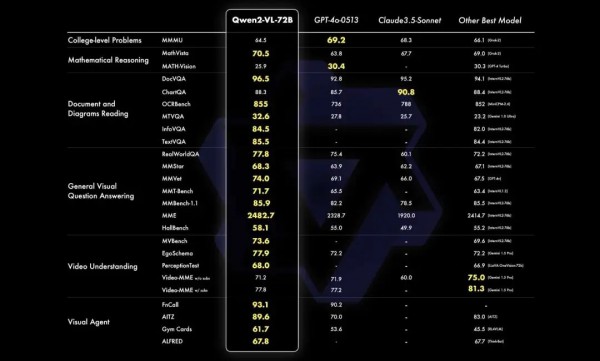
Qwen2-VL:阿里巴巴云计算团队开发的多模态大型语言模型系列,具备处理各种分辨率和比例的图像、理解超过20分钟视频、操作移动设备和机器人、以及支持多语言文本理解等多项先进功能。
参考文献:
[1] http://github.com/QwenLM/Qwen2-VL
[2] https://huggingface.co/collections/Qwen/qwen2-vl-66cee7455501d7126940800d
[3] https://modelscope.cn/organization/qwen?tab=model
[4] https://qwenlm.github.io/blog/qwen2-vl/
[5] https://huggingface.co/spaces/Qwen/Qwen2-VL
[6] https://help.aliyun.com/zh/model-studio/developer-reference/qwen-vl-api
好文章,需要你的鼓励



Allen AI团队推出SAGE:首个能像人类一样“想看多长就看多长“的智能视频分析系统
Allen AI研究所联合多家顶尖机构推出SAGE智能视频分析系统,首次实现类人化的"任意时长推理"能力。该系统能根据问题复杂程度灵活调整分析策略,配备六种智能工具进行协同分析,在处理10分钟以上视频时准确率提升8.2%。研究团队创建了包含1744个真实娱乐视频问题的SAGE-Bench评估平台,并采用创新的AI生成训练数据方法,为视频AI技术的实际应用开辟了新路径。

联想推出DE6600系列:更智能的存储解决方案
联想推出新一代NVMe存储解决方案DE6600系列,包含全闪存DE6600F和混合存储DE6600H两款型号。该系列产品延迟低于100微秒,支持多种连接协议,2U机架可容纳24块NVMe驱动器。容量可从367TB扩展至1.798PiB全闪存或7.741PiB混合配置,适用于AI、高性能计算、实时分析等场景,并配备双活控制器和XClarity统一管理平台。

AI视觉模型真的能看懂长篇文档吗?中科院团队首次揭开视觉文本压缩的真相
中科院团队首次系统评估了AI视觉模型在文本压缩环境下的理解能力,发现虽然AI能准确识别压缩图像中的文字,但在理解深层含义、建立关联推理方面表现不佳。研究通过VTCBench测试系统揭示了AI存在"位置偏差"等问题,为视觉文本压缩技术的改进指明方向。
2024
09/03
13:04
分享
点赞

