
第一个开源的具有实时对话能力的多模态模型:Mini-Omni
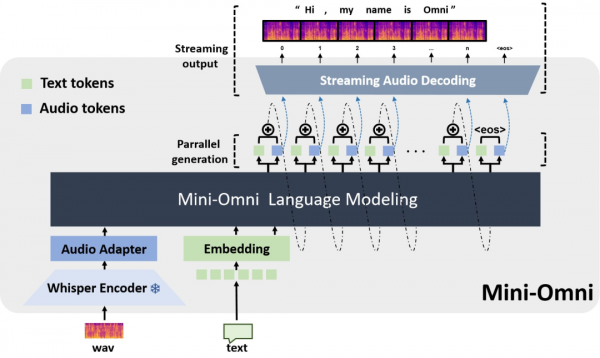
Mini-Omni是清华大学启元实验室开源的多模态模型,具备实时语音到语音的对话能力,无需额外的ASR或TTS模型。它能够边思考边说话,支持流式音频输出,并能通过'Any Model Can Talk'方法为其他模型添加语音交互能力。
第一个开源的具有实时对话能力的多模态模型:Mini-Omni ,支持端到端的语音输入、输出。Mini-Omni是清华大学启元实验室开源的项目,能听、能说也能实时思考,在实时语音交互上媲美GPT-4o。特点:
- 实时语音到语音的对话能力: 无需额外的ASR或TTS模型
- 边思考边说话: 能够同时生成文本和音频
- 流式音频输出: 支持流式音频输出
- "Any Model Can Talk" 方法: Mini-Omni 可以将语音交互能力添加到其他模型中,为其他模型赋能
参考文献:
[1] github:https://github.com/gpt-omni/mini-omni
[2] 论文:https://arxiv.org/abs/2408.16725
好文章,需要你的鼓励



印度理工学院突破性发现:大脑学习规律启发的全新AI图像生成技术
印度理工学院研究团队从大脑神经科学的戴尔定律出发,开发了基于几何布朗运动的全新AI图像生成技术。该方法使用乘性更新规则替代传统加性方法,使AI训练过程更符合生物学习原理,权重分布呈现对数正态特征。研究团队创建了乘性分数匹配理论框架,在标准数据集上验证了方法的有效性,为生物学启发的AI技术发展开辟了新方向。

英伟达与诺基亚联手开创AI驱动6G通信平台
英伟达和诺基亚宣布战略合作,将英伟达AI驱动的无线接入网产品集成到诺基亚RAN产品组合中,助力运营商在英伟达平台上部署AI原生5G Advanced和6G网络。双方将推出AI-RAN系统,提升网络性能和效率,为生成式AI和智能体AI应用提供无缝体验。英伟达将投资10亿美元并推出6G就绪的ARC-Pro计算平台,试验预计2026年开始。

Sony AI推出SoundReactor:让AI实时从画面生成身临其境的立体声音效
Sony AI开发出SoundReactor框架,首次实现逐帧在线视频转音频生成,无需预知未来画面即可实时生成高质量立体声音效。该技术采用因果解码器和扩散头设计,在游戏视频测试中表现出色,延迟仅26.3毫秒,为实时内容创作、游戏世界生成和互动应用开辟新可能。
2024
09/03
20:04
分享
点赞

