
极智AI | 解读大模型量化算法之GPTQ
GPTQ (Gradient-based Post-training Quantization) 是一种针对大规模预训练模型的高效后量化算法 (Post-Training Quantization, PTQ)。其主要目标是在不重新训练模型的情况下,将大模型模型权重量化到低比特(如4-bit或更低),同时尽可能保持模型的性能。
一、算法原理
GPTQ 的核心思想是通过最小化量化引入的输出误差,实现高精度低比特量化。具体来说,GPTQ 在后量化过程中,针对每一层的权重矩阵,利用一小部分校准数据,最小化量化前后模型输出的差异。其量化算法的基本步骤如下:
- 收集校准数据:从训练数据或相关数据集中抽取一小部分样本,作为校准数据;
- 逐层处理:对模型的每一层进行独立量化,避免全局优化的复杂度;
- 最小化输出误差:对于每一层,寻找最佳的量化权重,使得在校准数据上的输出误差最小;
- 更新权重:将量化后的权重替换原始权重;
1. 误差最小化原理

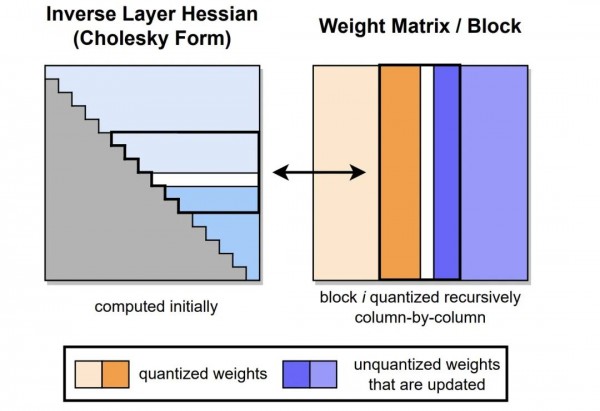
2. 逐列优化
为了降低计算复杂度,GPTQ 采用了逐列优化的方法。将权重矩阵 W 的列表示为 wi,对每一列进行量化,同时考虑之前列量化引入的误差累积。逐列量化的具体步骤如下:

3. 量化策略
在量化过程中,GPTQ 可以采用多种量化策略,如对称量化、非对称量化、均匀量化等。同时,量化器需要满足硬件的限制,确保量化后的值在表示范围内。
二、公式推导
1. 问题形式化

2. 问题转换

3. 最小化求解

4. 逐列更新的优势
逐列优化的主要优势在于:
- 降低计算复杂度:将高维的矩阵优化问题分解为多个低维的向量优化问题。
- 考虑误差累积:在每一步更新中,考虑了之前量化引入的误差,保证了整体误差的最小化。
三、GPTQ对比BNB和AWQ
1. BNB量化(BitsAndBytes Quantization)
BNB 主要实现了8-bit和4-bit的量化,支持在GPU上高效运行,BNB 采用了定点量化的方法,将浮点数映射到低比特的整数表示。其不足点主要体现在下面两点:
- 粗粒度量化:BNB量化通常使用定点量化,未充分考虑模型权重的分布特性。
- 缺乏误差最小化:未针对量化引入的误差进行优化,可能导致性能下降。
2. AWQ量化(Activation-aware Weight Quantization)
AWQ 量化考虑了激活值对权重量化的影响,通过联合优化权重和激活函数,实现更精细的量化。但其复杂度高:联合优化权重和激活函数,增加了实现和调试的复杂度。
3. GPTQ的优势
- 高精度:GPTQ通过最小化量化引入的输出误差,实现了在低比特下的高精度量化;
- 无需重新训练:作为后量化训练方法,只需一小部分校准数据,避免了重新训练的高昂成本;
- 适用性广:适用于各种大规模预训练模型,尤其是 Transformer 架构;
- 高效性:逐列优化的方法降低了计算复杂度,量化过程快速;
四、示例代码
下面展示使用 GPTQ 对模型进行量化的示例代码。
1. 安装必要的库
pip install transformerspip install acceleratepip install auto-gptq
2. 量化模型
import torchfrom transformers import AutoTokenizerfrom auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig# 指定模型名称model_name_or_path = "gpt2"# 定义量化配置quantize_config = BaseQuantizeConfig(bits=4, # 量化到4-bitgroup_size=128, # 分组大小,通常为128或Nonedesc_act=False, # 是否禁用激活函数的量化)# 加载模型并进行量化model = AutoGPTQForCausalLM.from_pretrained(model_name_or_path,quantize_config=quantize_config,use_triton=False # 如果安装了triton加速器,可设为True)# 加载分词器tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)# 保存量化后的模型save_directory = "gpt2-quantized"model.save_quantized(save_directory)tokenizer.save_pretrained(save_directory)
3. 推理测试
# 加载量化后的模型model_quantized = AutoGPTQForCausalLM.from_quantized(save_directory,use_safetensors=True,device="cuda:0" if torch.cuda.is_available() else "cpu",use_triton=False,)# 加载分词器tokenizer = AutoTokenizer.from_pretrained(save_directory, use_fast=True)# 准备输入input_text = "今天天气如何?"inputs = tokenizer(input_text, return_tensors="pt")# 将输入移动到模型设备inputs =# 生成输出with torch.no_grad():output_ids = model_quantized.generate(**inputs,max_new_tokens=50,do_sample=True,temperature=0.7,)# 解码输出output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)print(output_text)
其中:
- 设备选择:确保模型和输入的 Device;
- 内存优化:对于大型模型,一般就是在 GPU 上运行,并注意显存占用;
- 参数调整:根据模型和硬件情况,调整量化配置中的
bits、group_size等参数;
需要注意的是,某些大型模型(如Llama系列)使用了自定义的模型结构,需要在加载时设置 trust_remote_code=True。
好了,以上分享了 解读大模型量化算法之 GPTQ,希望我的分享能对你的学习有一点帮助。
好文章,需要你的鼓励


谷歌免费存储空间调整:未绑定手机号仅享5GB
谷歌近期悄然调整账户存储政策:新注册用户若未绑定手机号,免费存储空间将从原来的15GB缩减至5GB。用户需验证手机号后,方可获得完整的15GB空间,用于Gmail、Drive和Photos的共享使用。谷歌表示,此举旨在确保存储空间"每人仅限一份",有效防止滥用。有分析认为,存储硬件成本上升也是推动此次政策调整的重要原因之一。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

美国三大运营商携手卫星技术,向信号盲区宣战
AT&T、Verizon和T-Mobile宣布计划组建合资企业,利用卫星技术消除美国境内的网络覆盖盲区,重点服务农村及网络欠发达地区。该合资企业将整合知识产权与地面频谱资源,推动下一代直连设备(D2D)通信发展。目前三方尚未签署正式协议,现有运营商与卫星服务协议不受影响。此前,T-Mobile已与SpaceX合作推出星链卫星服务,美国联邦通信委员会也刚批准了价值400亿美元的EchoStar频谱出售案。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。

