
极智AI | 解读强化学习中的Q-learning
马尔可夫决策过程 (MDP)

Q函数
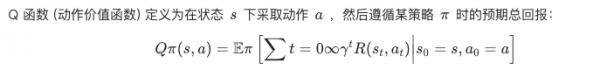
贝尔曼最优方程
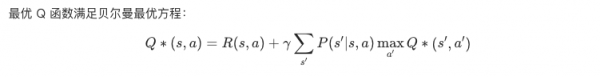
Q-learning更新规则

Q-learning算法步骤

下面以经典的 FrozenLake 环境(一个 4x4 的网格世界)为例,使用 Python 和 OpenAI Gym 库来实现 Q-learning 算法。
import numpy as npimport gym# 创建FrozenLake环境env = gym.make('FrozenLake-v1', is_slippery=False)# 初始化参数num_states = env.observation_space.nnum_actions = env.action_space.nQ = np.zeros((num_states, num_actions))num_episodes = 1000max_steps = 100alpha = 0.1 # 学习率gamma = 0.99 # 折扣因子epsilon = 0.1 # 探索率for episode in range(num_episodes):state = env.reset()for step in range(max_steps):# 选择动作(ε-贪心策略)if np.random.uniform(0, 1) < epsilon:action = env.action_space.sample()else:action = np.argmax(Q[state, :])# 执行动作,获得下一个状态和奖励next_state, reward, done, info = env.step(action)# 更新Q函数best_next_action = np.argmax(Q[next_state, :])td_target = reward + gamma * Q[next_state, best_next_action]td_error = td_target - Q[state, action]Q[state, action] += alpha * td_error# 状态更新state = next_state# 回合结束if done:breakprint("训练完成后的Q表:")print(Q)
其中:
- 环境初始化:使用
gym.make('FrozenLake-v1')创建环境; - Q表初始化:Q 是一个二维数组,维度为
[num_states, num_actions],用于存储每个状态-动作对的价值; - 主循环:循环进行多个回合,每个回合代表一次完整的游戏;
- 动作选择:使用 ε-贪心策略,以概率 ε 随机选择动作,或以概率 1-ε 选择当前 Q 值最大的动作;
- Q值更新:根据之前提到的 Q-learning 更新公式更新 Q 表;
- 回合终止条件:如果到达终止状态(成功或者掉入陷阱),则结束当前回合;
为了平衡探索和利用,ε-贪心策略以 ε 的概率进行探索 (随机选择动作),以 1-ε 的概率进行利用(选择当前最优动作)。学习率决定了新获取的信息在多大程度上覆盖旧的信息,较高的学习率意味着对新信息的依赖性更强。折扣因子用于权衡即时奖励和未来奖励的重要性。接近1的折扣因子表示更加看重未来的奖励。在满足一定条件下,如所有状态-动作对被无限次访问、学习率满足罗宾条件等,Q-learning 算法能够保证收敛到最优 Q 函数。Q-learning 是强化学习中最经典和基础的算法之一,它通过学习状态-动作值函数来指导智能体的决策。通过不断地与环境交互和更新 Q 值,智能体最终能够学到一个最优策略,即在每个状态下选择使得长期累积奖励最大的动作。
好文章,需要你的鼓励

英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。

