
ЪЎФъвЛНЃЃЌTPUв§СьAIаОЦЌЪБДњ

1ЁЂTPU ШчКЮЗЂеЙЖјРДЃП
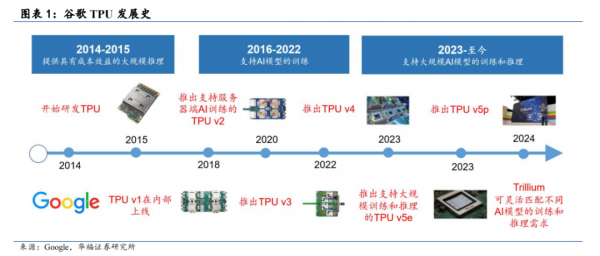
МђЖјбджЎЃЌЮЊИќзЈгУЕФ AI МЦЫуЖјРДЁЃ2013 ФъЃЌGoogle AI ИКд№ШЫЗЂЯжЃЌШчЙћга1 вкАВзПгУЛЇУПЬьЪЙгУЪжЛњгявєзЊЮФзжЗўЮё 3 ЗжжгЃЌЯћКФЕФЫуСІОЭвбЪЧЙШИшЫљгаЪ§ОнжааФзмЫуСІЕФСНБЖЁЃЖјДЋЭГЕФЭЈгУCPU вдМАзЈЙЅЭМаЮМгЫйЁЂЪгЦЕфжШОЕШИДдгШЮЮё GPUЮоЗЈТњзуЩюЖШбЇЯАЙЄзїИКдиЕФОоДѓашЧѓЃЌЭЌЪБДцдкаЇТЪНЯЕЭЁЂзЈгУдЫЫугаЯоЕШЮЪЬтЁЃ
гкЪЧЃЌЮЊЬНЫїГіИќОпГЩБОаЇвцЁЂНкФмЕФЛњЦїбЇЯАНтОіЗНАИЃЌЙШИшвуШЛОіЖЈздаабаЗЂЛњЦїбЇЯАзЈгУЕФДІРэЦїаОЦЌЃЌВЂгк 2015 ФъаћВМЕквЛДњ TPU аОЦЌЃЈTPU v1ЃЉдкФкВПЩЯЯпЃЌЫцКѓПЊЦєСЫГЄДя 10 ФъЕФ TPU ИќаТЕќДњЁЃ
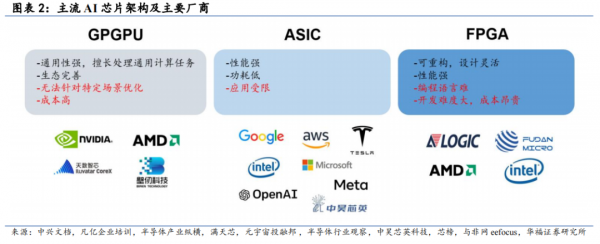
зїЮЊвЛжж AI аОЦЌЃЌTPU ЪЧзЈгУМЏГЩЕчТЗЃЈASICЃЉЕФДњБэЁЃжїСї AI аОЦЌМмЙЙАќРЈ GPGPUЁЂASIC КЭ FPGAЁЃGPGPU ЭЈгУадЧПЃЌЩњЬЌЭъЩЦЃЌGPGPU ЕФжївЊЙЉгІЩЬгЂЮАДяЪЧ AI ЪаГЁЕФОјЖдСњЭЗЃЌЕЋ GPGPU ДцдкзХГЩБОИпЕШЮЪЬтЃЛASIC ЫфШЛЫуСІЧПДѓЃЌЙІКФаЁЃЌЕЋЯрНЯгк GPGPU дкЭЈгУМЦЫуЩЯЩдгаЧЗШБЃЛFPGA ИќОпСщЛюадЃЌвВОпгазуЙЛЕФЫуСІЃЌЕЋЯрЖдПЊЗЂжмЦкГЄЃЌИДдгЫуЗЈПЊЗЂФбЖШДѓЃЌГЩБОАКЙѓЁЃ
TPU зЈЮЊЕЅвЛЬиЖЈФПЕФЖјЩшМЦЃКгУвддЫааЙЙНЈ AI ФЃаЭЫљашЕФЖРЬиОиеѓКЭЛљгкЪИСПЕФЪ§бЇдЫЫуЁЃЦфМмЙЙзЈЮЊОиеѓГЫЗЈЖјЩшМЦЃЌетЪЙЫќУЧФмЙЛДІРэДѓСПЪ§ОнвдМАИДдгЕФЩёОЭјТчЁЃашвЊЫЕУїЕФЪЧЃЌЮвУЧвВПДЕНЯрЙибаОПНЋ TPU ЙщРрЮЊ DSAЃЈзЈгУСьгђМмЙЙДІРэЦїЃЉЃЌвђЮЊASIC ЪЧМгЫйФГвЛЯюЙІФмЃЌЖј DSA ЪЧМгЫйФГвЛРрЙІФмЁЃЕЋзмЬхЩЯ ASIC КЭ DSA ЕФЬиеїНЯЮЊЯрЗТЃЌБОЮФВЛзїНјвЛВНЧјЗжЁЃ
2ЁЂTPU гХЪЦКЮдкЃП
2.1ЁЂаОЦЌВуУцЃКФмаЇЭѕепЃЌМмЙЙЩшМЦжЎУРСмРьОЁжТ
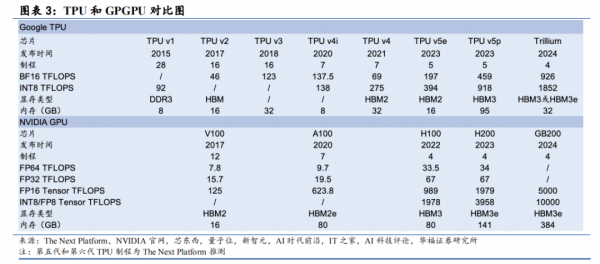
СљДњАцБОИќаТЃЌгы GPGPU ЦНЗжЧяЩЋЁЃЮвУЧНЋРњДњ TPU вдМАЭЌЪБДњЕФ GPGPUНјааЪсРэЁЃЪзЯШЃЌЮвУЧЙлВьЕНЭЌДњ TPU гы GPGPU ДѓЖрЪ§ДІгкЭЌДњЛђЯрНќжЦГЬЁЃЕкЫФДњ TPU вбВЩгУ 7nm жЦГЬЃЌОн The Next Platform ЭЦВтЕкЮхДњ/ЕкСљДњ TPU ЗжБ№ВЩгУ5nm/4nm жЦГЬЃЌЖјгЂЮАДя Ampere/Hopper/Blackwell МмЙЙЗжБ№ВЩгУ 7nm/4nm/4nm жЦГЬЁЃ
дкЫуСІЩЯЃЌЙШИшФПЧАднЪБТфКѓвЛДњЁЃ2024 ФъЙШИшЗЂВМЕкСљДњ TPU TrilliumЃЌЪЕЯжзюДѓЫуСІ 926TFLOPSЃЈBF16ЃЉ/1852TFLOPSЃЈINT8ЃЉЃЌЯрНЯгкЕкЮхДњ TPU v5e КЭ v5pЪЕЯжСЫЗЩдОЪНЩЯЩ§ЃЌБШМчгЂЮАДя 2023 ФъЗЂВМЕФ H100ЃЌЖдгІЫуСІЮЊ 989TFLOPSЃЈFP16ЃЉ/1978TFLOPSЃЈINT8 or FP8ЃЉЁЃЕЋдкадФмЙІКФБШЩЯЃЌЮвУЧШЯЮЊЙШИшгХЪЦЯджјЁЃЙШИшВЂЮДХћТЖзюаТВњЦЗЕФЙІКФжИБъЃЌЮвУЧДгЧАДњВњЦЗПЩвдПњМћвЛЖў——2021 ФъЗЂВМЕФЕкЫФДњ TPU v4 адФмЙІКФБШЮЊ 0.89-1.31TOPS/WЃЌЖјгЂЮАДяЭЌДњВњЦЗ A100ЃЈ2020 ФъЗЂВМЃЉЕФадФмЙІКФБШЮЊ 1.56TOPS/WЁЃ
ЖдДЫЯжЯѓЃЌЮвУЧПЩвдДгТпМаОЦЌМмЙЙЕФНЧЖШРДНјааНтЪЭ——ЭЈгУДІРэЦї CPU КЭGPGPU вђМмЙЙЩшМЦЖјдк AI МЦЫуЩЯДцдкЕЭаЇЮЪЬтЁЃЮвУЧвЛАуШЯЮЊ GPGPU ЮЊИФЩЦCPU аЇТЪЖјЩњЃЌЖј TPU ПЩвдНјвЛВНИФЩЦ GPGPU ЮДгХЛЏЭъШЋЕФВПЗжЃЌШ§епЪЧДгЭЈгУЕНзЈгУВЛЖЯбнНјЕФЙ§ГЬЁЃ
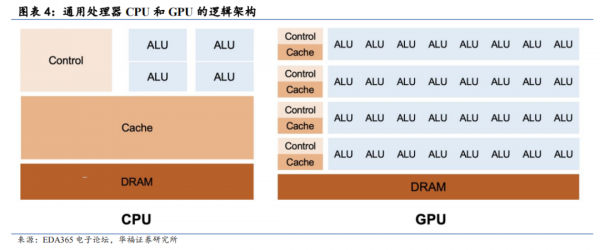
ОнаТжЧдЊЃЌCPU ЪЙгУСЫЗЧГЃДѓСПЕФЦЌЩЯДцДЂРДзіЛКДцЃЈCacheЃЉЃЌНЋГЬађОГЃЗУЮЪЕФЪ§ОнЗХдкЦЌЩЯЃЌетбљОЭВЛБиЗУЮЪФкДцСЫЃЌДгЖјЪЕЯж“ФкДцЗУЮЪНќКѕСубгГй”ЃЌЯрБШжЎЯТИКд№дЫЫуЕФЫуЪѕТпМЕЅЃЈALUЃЉжЛеМОнСЫвЛаЁВПЗжЃЌетОЭЪЧ CPU НјааДѓЙцФЃВЂааЪ§ОндЫЫуЪБаЇТЪЕЭЕФдвђжЎвЛЁЃGPU РяУцгаЪ§ЧЇИіаЁКЫаФЃЌУПИіЖМПЩвдПДГЩЪЧИіаЁ CPUЃЌЫќПЩЭЌЪБдЫаазюЖрЪ§ЪЎЭђИіаЁГЬађЁЃЫфШЛ GPU ЕЅКЫЕФДІРэФмСІШѕгк CPUЃЌЕЋЪЧЪ§СПХгДѓЃЌALU еМБШДѓЃЌЗЧГЃЪЪКЯИпЧПЖШВЂааМЦЫуЁЃ
ЕЋЪЕМЪЩЯДѓЖрЪ§ГЬађЛсвђЮЊЕШД§ЗУДцЖјПЈзЁЃЌЧвЙмРэКЭзщжЏДѓСПГЬађЛсИЖГіОоДѓЕФЙшЦЌУцЛ§ДњМлКЭФкДцДјПэЕФДњМлЃЌетИіЪЧ GPU ЕЭаЇЕФИљдДЁЃ
TPU гХЪЦ#1 ТіЖЏеѓСаЮЊЛљЃЌеХСПМЦЫуКсПеГіЪР——діДѓЭЬЭТСПЃЌНкЪЁЪБМфTPU БОвхЮЊеХСПДІРэЦїЃЌетЦфжаЕФ“еХСП”ЪЧдкЪ§бЇКЭЮяРэСьгђГЃМћЕФИХФюЁЃ
ДгЖЈвхЩЯНВЃЌеХСПЪЧвЛИіЖрЮЌЪ§зщЃЌПЩвдОпгаШЮвтЮЌЖШЃЌеХСПЕФдЊЫиПЩвдЪЧБъСПЁЂЯђСПЛђИќИпЮЌЖШЕФеХСПЁЃвЛИіЪ§жЕПЩвдПДзївЛИіБъСПЃЈСуЮЌеХСПЃЉЃЌвЛИівЛЮЌЪ§зщПЩПДзївЛИіЯђСПЃЈвЛЮЌеХСПЃЉЃЌвЛИіЖўЮЌЪ§зщЪЧвЛИіОиеѓЃЈЖўЮЌеХСПЃЉЁЃдкЩюЖШбЇЯАКЭЩёОЭјТчжаЃЌЮвУЧОГЃгУИпЮЌЕФеХСПРДБэЪОЭМЯёЁЂвєЦЕЁЂЮФБОЕШЪ§ОнЁЃЭЈЙ§дкЩёОЭјТчЕФИїИіВуМЖжЎМфНјааеХСПЕФДЋЕнКЭМЦЫуЃЌЩёОЭјТчФмбЇЯАКЭДІРэИДдгЕФЪфШыЪ§ОнЃЌжДааЬиеїЬсШЁЁЂЗжРрЁЂЛиЙщЕШШЮЮёЁЃ
TPU ЕФКЫаФЪЧ MXUЃЈОиеѓГЫЗЈЕЅдЊЃЉЃЌMXU вдТіЖЏеѓСаЮЊМмЙЙЃЌЪЙ TPU ФмЙЛвдКмИпЕФЭЬЭТСПжДааОиеѓГЫЗЈКЭРлМгЁЃТіЖЏеѓСазїЮЊ TPU ЕФЕзВуММЪѕЃЌЪЧвЛжжЪЪгУгкНјааДѓСПЕФВЂааМЦЫуЃЈгШЦфЪЧОиеѓГЫЗЈЃЌвВЪЧЩюЖШбЇЯАжазюГЃМћЕФВйзїЃЉЕФМЦЫугВМўНсЙЙЁЃ
ТіЖЏеѓСаЕФУћзжРДдДгкЫќЕФЙЄзїЗНЪНЃЌМДЪ§ОндкеѓСажа“ТіЖЏ”ЪНЕиСїЖЏЃЌОЭЯёаФдрдкбЊЙмжаБУбЊвЛбљЁЃЭЈЙ§етжжЗНЪНЃЌТіЖЏеѓСаПЩвдИпаЇЕижДааОиеѓМЦЫуВйзїЃЌвђЮЊЪ§ОнЕФСїЖЏЗНЯђЗћКЯМЦЫуЙцдђКЭЪ§ОнвРРЕЙиЯЕЁЃетжжВЂааЕФЪ§ОнСїЖЏЗНЪНПЩвдГфЗжРћгУгВМўНсЙЙЕФВЂааадЃЌМгЫйОиеѓМЦЫуЙ§ГЬЁЃТіЖЏеѓСавВБиШЛДцдкОжЯоадЃЌБШШчЫќЕФМЦЫуФЃЪНЯрЖдЙЬЖЈЃЌВЛЪЪКЯжДаагаДѓСППижЦСїЕФМЦЫуЁЃВЛЙ§ЃЌдкЩюЖШбЇЯАжаЃЌДѓВПЗжЕФМЦЫуЖМЪЧЪ§ОнСїЪНЕФЃЌЧвжДааВЂааЕФОиеѓМЦЫуЃЌвђДЫетИіОжЯоадЕФгАЯьВЂВЛДѓЁЃ
TPU гХЪЦ#2 жБЛї AI гІгУЃЌОлНЙЕЭОЋЖШМЦЫу——НкЪЁаОЦЌУцЛ§
ЛиПДБОЮФПЊЦЊЖдЙШИшЗЂеЙРњГЬЕФИДХЬЃЌДѓжТПЩвдНЋЦфЛЎЗжЮЊСНИіЪБДњ——вдChatGPT ЮЊЗжЫЎСыЕФ AI ГѕЬНЫїНзЖЮКЭ AI ДѓБЌЗЂЪБДњЁЃTPU здЗЂУївдРДвЛжБвдЕЭОЋЖШжјГЦЃЌДг AI ГѕЬНЫїНзЖЮТѕШы AI ДѓБЌЗЂЪБДњЃЌTPU вВОРњСЫ“ВІдЦМћШе”ЕФЙ§ГЬЁЃ
AI ГѕЬНЫїНзЖЮЃКГѕДњ TPU ШыОж AI ЭЦРэЃЌTPU v2 ШыОж AI бЕСЗ——ЕЭОЋЖШМЦЫуМДПЩТњзу AI МЦЫуашЧѓЃЌЬиЖЈЗНЯђгХЛЏГіЦцаЇЁЃЩёОЭјТчЕФСНИіжївЊНзЖЮЪЧбЕСЗЃЈTraining ЛђепбЇЯА LearningЃЉКЭЭЦРэЃЈinference ЛђепдЄВт PredictionЃЉЁЃЪЕМЪЩЯЃЌГѕДњ TPU ЭЦГіЕФЭЌвЛЪБЦкЃЌбЕСЗМИКѕЖМЪЧЛљгкИЁЕудЫааЃЌетвВЪЧ GPU СїааЕФдвђжЎвЛЁЃ
ЪТЪЕЩЯЃЌЭЦРэЙ§ГЬЪЙгУ INT8 вВЛљБОЙЛгУЁЃINT8 дЫЫуЯрНЯгкИЁЕуЪ§ЖјбдЃЌЖдећИіаОЦЌЕФФмКФЁЂУцЛ§ЖМгаНЯДѓГЬЖШЩЯЕФНкЪЁЃЌжївЊАќРЈвдЯТСНЗНУцЃК
ЃЈ1ЃЉГЫЗЈдЫЫуЃКINT8ГЫЗЈБШ IEEE 754 БъзМЯТ FP16 ГЫЗЈНЕЕЭ 6 БЖЕФФмКФЃЌеМгУЕФЙшЦЌУцЛ§вВЩй 6 БЖЃЛ
ЃЈ2ЃЉМгЗЈдЫЫуЃКећЪ§МгЗЈЕФЪевцЪЧ 13 БЖЕФФмКФгы 38 БЖЕФУцЛ§ЁЃДгетвЛНЧЖШГіЗЂЃЌЙШИшTPU ЩшМЦЫГЪЦВЩгУЕЭОЋЖШМЦЫуФЃЪНЃЌTPU v1 НіжЇГж INT8 ОЋЖШЃЌЖјЭЌЪБДњгЂЮАДяЕФAI ЭЦРэаОЦЌ K80ЃЈ2014 ФъЭЦГіЃЉзюЕЭашвЊжЇГж FP32 ОЋЖШЁЃ
ЪЕМЪаЇЙћЯдЪОЃЌгы GPUЯрБШЃЌTPU ЕФПижЦТпМЕЅдЊИќаЁЃЌИќШнвзЩшМЦЃЌУцЛ§жЛеМећЬхаОЦЌУцЛ§ЕФ 2%ЃЌИјЦЌЩЯДцДЂЦїКЭОиеѓМЦЫуЕЅдЊСєЯТСЫИќДѓЕФПеМфЁЃКѓРДДг TPU v2 ПЊЪМЃЌЙШИшв§ШыСЫздДДЕФИЁЕуОЋЖШ BF16ЃЌЫфгы FP16 БЃГжЯрЭЌЮЛЪ§ЃЈдкИЁЕуОЋЖШЕФЮЛЪ§ЩЯгыгЂЮАДяЭЌЪБДњВњЦЗ V100 БЃГжСЫвЛжТЃЉЃЌЕЋФмЙЛМѕЩйФкДцеМгУЃЌвВЖд AI гВМўЕФЗЂеЙВњЩњЩюдЖгАЯьЁЃ
дкетвЛНзЖЮЃЌAI гІгУЕФЗНЯђЛЙВЛЙЛЧхЮњЃЌAI гВМўЕФЗЂеЙТЗОЖвВВЂВЛУїРЪЁЃTPUЪЧЙШИшЛљгкздЩэвЕЮёвдМАЖд AI ЕФРэНтЖјзіГіЕФбЁдёЁЃЖдгкЕЭОЋЖШЕФОлНЙЃЌМШЪЧдкAI МЦЫуЩЯЕФгХЪЦЃЌЭЌбљвВЪЧдкЦфЫћМЦЫуСьгђЕФСгЪЦЁЃетвВЪЧ ASIC БОЩэЕФзЈгУЛЏЬиеїЫљдьОЭЕФЁЃеОдкЕБЯТЛиЭћЃЌЮвУЧЗЂЯжЃЌTPU ОпБИЕФгХЪЦЦфЪЕзюжеЖМаЮГЩСЫ AI аОЦЌЙВЭЌЕФЧїЪЦЃЌдкгХЛЏЗНЯђЩЯДѓЭЌаЁвьЃЌЖјЙШИшЕФЧПДѓдкгк“ЧАеА”ЁЃ
AI ДѓБЌЗЂЪБДњЃКAI гІгУДѓЪЦЫљЧїЃЌЕЭОЋЖШдЫЫуГЩЮЊДѓЙцФЃ AI бЕСЗ&ЭЦРэЕФБъЧЉЬиеї——TPU v5жЇГжДѓЙцФЃбЕСЗЭЦРэЫЎЕНЧўГЩЁЃЫцзХAIгІгУРДЕН“ChatGPT”ЪБПЬЃЌДѓгябдФЃаЭДяЕНЪ§ЭђвкВЮЪ§ЃЌДѓЙцФЃ AI МЦЫуЪБДњвбОЕНРДЁЃAIЁЂИпадФмМЦЫуКЭЪ§ОнЗжЮіБфЕУШевцИДдгЃЌAI ФЃаЭГЇЩЬгаЪБдИвтЮўЩќОЋЖШжЕРДЛёШЁДѓФЃаЭбЕСЗЕФМЦЫуФмСІЃЌвВОЭЪЧгУИпдЫЫуЫйЖШЁЂЕЭДцДЂашЧѓРДМгЫйМЦЫуЙ§ГЬЁЃЭЈЙ§ЪсРэЮвУЧЗЂЯжЃЌВЛжЙ TPUЃЌGPGPU вВдкЯђзХЕЭОЋЖШЧїЪЦЗЂеЙЁЃ
2.2ЁЂМЏШКВуУцЃКЫуСІРћгУТЪЪЧзюКУЕФжЄУї
дкAI ДѓФЃаЭдЄбЕСЗЗНУцЃЌЙШИш TPU ЕФЫуСІРћгУТЪБэЯжУїЯдСьЯШгкгЂЮАДяЁЃОнСПзгЮЛЃЌЫуСІРћгУТЪЃЈMFUЃЉЪЧЪЕМЪЭЬЭТСПгыРэТлзюДѓЭЬЭТСПжЎБШЁЃбЕСЗДѓгябдФЃаЭВЂЗЧМђЕЅЕФВЂааШЮЮёЃЌашвЊдкЖрИі GPU жЎМфЗжВМФЃаЭЃЌВЂЧветаЉ GPU ашвЊЦЕЗБЭЈаХВХФмЙВЭЌЭЦНјбЕСЗНјГЬЁЃЭЈаХжЎЭтЃЌВйзїЗћгХЛЏЁЂЪ§ОндЄДІРэКЭ GPU ФкДцЯћКФЕШвђЫиЃЌЖМЖдЫуСІРћгУТЪЃЈMFUЃЉетИіКтСПбЕСЗаЇТЪЕФжИБъгагАЯьЁЃGPT-3 ЕН GPT-4УїЯдПДЕНЫуСІРћгУТЪгЩ 21.3%ЬсЩ§жС 34%ЃЈ32-36%ЧјМфЃЌБОЮФШЁжажЕДжТдМЦЫуЃЉЃЌЧїЪЦЩЯНЯЮЊУїШЗЁЃ
КсЯђЖдБШЗЂЯжЃЌЯрНЯгк OpenAI ЕФ GPT ЯЕСаЃЌЙШИшРћгУ TPU бЕСЗЕФGropher КЭ PaLM УїЯддкЫуСІРћгУТЪЩЯИќЪЄвЛГяЃЌЮвУЧШЯЮЊЙШИшздба TPU дкздгаДѓФЃаЭбЕСЗЩЯеЙЯжГіЖРЬиЕФгХЪЦЁЃ
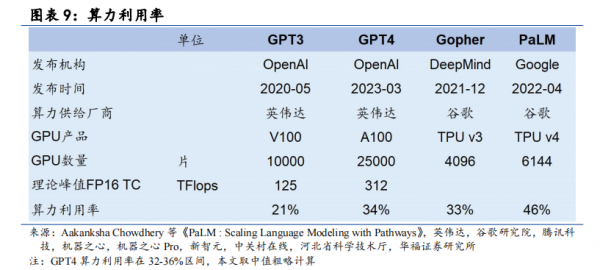
ДгбЕСЗаЇЙћЩЯПДЃЌЙШИш TPU вВгаВЛЫзБэЯжЁЃ22 ФъЗЂВМЕФЕкЫФДњ TPU дкаэЖрMLPerf ЛљзМВтЪдЃЈзюЯджјЕФЪЧЩюЖШбЇЯАКЭОэЛ§ЭјТчЃЉЩЯЕФБэЯжгХгкгЂЮАДяЁЃдк MLPerfЮхЯюЛљзМВтЪджаЃЌTPUv4 адФмБШ A100 ИпГі 40%ЁЃЭЌЪБЃЌдкИї AI ГЇЩЬЙизЂЕФбЕСЗГЩБОЩЯЃЌЙШИшЕФ TPU v4 ЯрНЯгк A100 БэЯжИќгХвьЁЃ
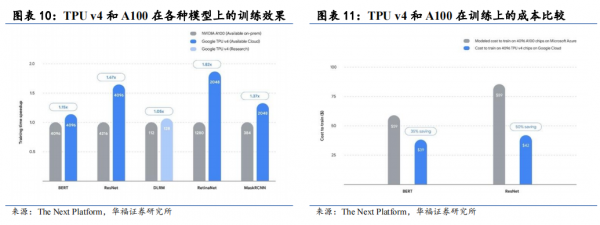
#гВМўгХЪЦ ЙШИшздбаЙтбЇаОЦЌ PalomarЃЌДгМЏШКЛЅСЌНЧЖШЙЙНЈгХЪЦЁЃЙШИшЩшМЦTPU ЕФФПЕФОЭЪЧЙЙНЈздМКЕФГЌМЖМЦЫуЛњЃЌШчКЮИпЫйЖШЁЂЕЭбгГйЕиАбОЁПЩФмЖрЕФ TPUаОЦЌСЌНгЦ№РДЪЧвЛИіВЛПЩБмУтЕФЮЪЬтЁЃЙШИшгжвЛДЮАбЮеЧАеАЗНЯђЃЌдкГЃЙцЕФЛЅСЌЭиЦЫНсЙЙжаКБМћЕиздбаСЫЙтбЇаОЦЌ PalomarЃЈЙШИш TPU v4 ЩшМЦЕФЦфжавЛИіжиЕуЃЉЃЌЪЙгУИУаОЦЌЪЕЯжСЫШЋЧђЪзИіЪ§ОнжааФМЖЕФПЩжиХфжУ OCSЁЃдк Palomar аОЦЌМгШыКѓЃЌСЂЗНЬхНсЙЙНкЕужЎМфЕФЛЅСЌВЂЗЧвЛГЩВЛБфЕФЃЌЖјЪЧПЩвдЯжГЁжиХфжУЃЌетбљзіЕФзюДѓКУДІЪЧПЩвдИљОнОпЬхЕФЛњЦїбЇЯАФЃаЭРДИФБфЭиЦЫЃЌвдМАИФЩЦГЌМЖМЦЫуЛњЕФПЩППадЁЃШчЯТЭМЫљЪОЃЌдкЪЙгУПЩжиХфжУЙтЛЅСЌЃЈвдМАЙтТЗПЊЙиЪБЃЉЃЌЯЕЭГгааЇЭЬЭТСПКЭРћгУТЪДѓЗљЬсЩ§ЁЃ
#ШэМўгХЪЦ TPU зЈЮЊ TensorFlow ДђдьЃЌШэМўгыгВМўЯрИЈЯрГЩЁЃTensorFlow ЪЧGoogle ЕФвЛИіПЊдДЛњЦїбЇЯАШэМўПтЁЃTPU ЪЧИљОн TensorFlow ЩшМЦЕФЃЌДгЖјФмЙЛНЕЕЭдЫЫуОЋЖШЃЌдкЯрЭЌЪБМфФкДІРэИќИДдгЁЂИќЧПДѓЕФЛњЦїбЇЯАФЃаЭВЂНЋЦфИќПьЭЖШыЪЙгУЁЃ
РДдДЃКМмЙЙЪІММЪѕСЊУЫ
КУЮФеТЃЌашвЊФуЕФЙФРј


УзРЁЄФТРЬсжиЗЕЙЋжкЪгвАЃЌНїЩїЗЂЩљ
ФТРЕйЪБИє18ИідТЪзДЮНгЪмжиДѓУНЬхВЩЗУЃЌНщЩмЦфДДСЂЕФThinking Machines Labе§дкПЊЗЂЕФ"НЛЛЅФЃаЭ"ЁЃИУФЃаЭФмвд200КСУыМфИєДІРэвєЦЕЁЂЮФБОКЭЪгЦЕСїЃЌВЖзНШЫРрНЛСїжаЕФжаЖЯЁЂаое§КЭЭЃЖйЁЃЫ§ЛЙЬИМАOpenAI"еўБфжм"ОРњЃЌЧПЕїаавЕОіВпШЈЙ§гкМЏжаЕФЕЃгЧЃЌВЂЛигІСЫЙЋЫОНќЦкбаОПШЫдБРыжАЮЪЬтЃЌБэЪОетЪЧГѕДДЪЕбщЪвЕФе§ГЃВЈЖЏЁЃ

ЕБAIЛњЦїШЫЁАздаХЕиЁАзВЯђЧНБкЃКSTATE16баОПдКНвЪОЮяРэAIЯЕЭГжаФЧаЉЮоЩљЮоЯЂЕФжТУќДэЮѓ
STATE16баОПдКетЦЊзлЪіЗЂЯжЃЌЮяРэAIЯЕЭГДцдк"ОВФЌЪЇаЇ"ЗчЯеЁЊЁЊAIвдИпЖШздаХжДааЛљгкДэЮѓЪРНчаХЯЂЕФЖЏзїЃЌШДВЛДЅЗЂШЮКЮБЈОЏЃЌВЂЬсГідкAIЪфГігыЮяРэжДаажЎМфНЈСЂЖРСЂЪкШЈВуЕФПђМмЁЃ

ЬиЫЙРвЩЫЦЩОГ§FSDжЄОнЃЌПЈЬиБЫРеМгЫйЕчЖЏЛЏВМОжЃЌИпбЙЯЕЭГММЪѕХрбЕПЬВЛШнЛК
БОЦкЁЖQuick ChargeЁЗВЅПЭКИЧЖрИіШШЕуЛАЬтЃКЬиЫЙРвЩЫЦЪдЭМЩОГ§FSDЦлеЉЯрЙижЄОнвдЙцБмОоЖюХтИЖЃЛПЈЬиБЫРеГжајЭЦНјНЈжўСьгђЕчЦјЛЏВМОжЃЛзЁеЌЬЋбєФм30%ЫАЪеЕжУтМДНЋЕНЦкЁЃДЫЭтЃЌМЮБіTom PachecoОЭИпбЙЯЕЭГгыЕчГиММЪѕХрбЕеЙПЊЬНЬжЃЌЧПЕїЕчЖЏГЕММЪѕШЫВХХрбјЕФНєЦШадЁЃНкФПЭЌЪБЬсабгавтАВзАЬЋбєФмЕФгУЛЇОЁПьааЖЏЃЌПЩЭЈЙ§EnergySageЦНЬЈБШНЯЖрМвАВзАЩЬБЈМлЁЃ

ЕБAIбЇЛсЁАБпИЩБпбЇЁАЃКUIUCгыЮЂШэСЊКЯДђдьЕФЭјвГжЧФмЬхбЕСЗаТЗЖЪН
UIUCгыЮЂШэСЊКЯбаЗЂЕФOpenWebRLПђМмШУ4BаЁФЃаЭНіЦО400ЬѕГѕЪМЪ§ОнЃЌЭЈЙ§дкецЪЕЭјеОЩЯБпзіБпбЇЕФЧПЛЏбЇЯАЗНЪНЃЌдкЭјвГжЧФмЬхЛљзМЩЯГЌдНСЫгУ27ЭђЬѕЪ§ОнбЕСЗЕФОКељЖдЪжЁЃ
2024
11/01
11:04
ЗжЯэ
Еудо

