
微软开源视觉GUI智能体:增强GPT-4V能力,超3800颗星
随着GPT-4V等多模态视觉大模型的出现,在理解和推理视觉内容方面获得了巨大进步。但是将预测的动作准确转换为UI上的实际操作时却很难。
例如,难以准确识别用户界面内可交互的图标,以及在理解屏幕截图中各种元素的语义并将预期动作与屏幕上相应区域的关联。
为了解决这个难题,微软研究人员开源了纯视觉GUI智能体OmniParser,能够轻松将用户界面截图解析为结构化元素,显著增强GPT-4V等模型对应界面区域预测的能力。目前,OmniParser在Github上非常火,已经超过3800颗星。

开源地址:https://github.com/microsoft/OmniParser
通常在UI识别操作任务中,模型需要具备两个关键能力:一是理解当前UI屏幕的内容,包括分析整体布局以及识别带有数字 ID 标注的图标的功能;二是基于当前屏幕状态预测下一步有助于完成任务的动作。
研究人员发现,将这两个任务整合在一个模型中执行会给模型带来较大负担,影响其性能表现。因此,OmniParser 采用了一种分阶段处理的策略,在屏幕解析阶段预先提取相关信息,来减轻GPT - 4V在动作预测时的负担,使其能够更好地聚焦于核心任务。
OmniParser的核心组件包括一个微调的交互式图标检测模型、一个微调的图标描述模型以及OCR光学字符识别模块。这三个组件协同工作,可以生成用户界面的结构化表示,类似于文档对象模型,并且还会在截图上叠加显示潜在可互动元素的边界框。
在OmniParser的整体架构中,可互动区域检测模型扮演着至关重要的角色,是识别用户界面截图中所有潜在可互动元素的关键组件。为了训练这样一个高效的检测模型,研究人员采取了一系列策略和技术手段。
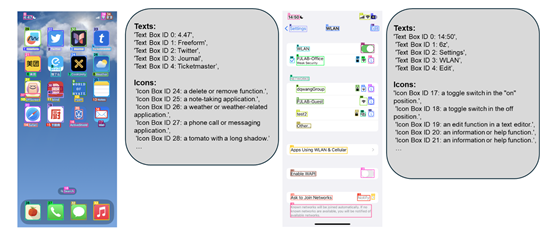
首先,利用先前构建的大规模数据集,该模型被赋予了识别多种类型可互动图标的能力。这些图标包括但不限于按钮、链接、菜单选项等常见控件。通过对大量带有精确边界框标注的真实网页截图进行学习,模型逐渐掌握了不同类型图标之间的细微差别,以及它们在不同上下文环境中可能出现的变化形式。不仅提高了模型的泛化能力,也使其能够在遇到新样式或未曾见过的图标时仍能做出准确判断。
除了直接使用图像作为输入外,研究人员还引入了一种称为Set-of-Marks的方法来辅助训练过程。这种方法通过在原始截图上叠加一层高亮显示的边界框来明确指出哪些区域属于可互动元素,可以有效地引导模型关注那些真正重要的地方,而非整个屏幕的所有细节。
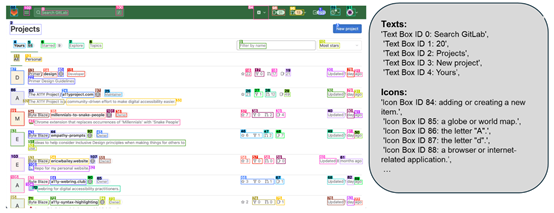
此外,相比于其他类似工作中采用的真实DOM树节点位置信息或者人工标注的数据集,这种方式具有更好的灵活性和适用范围,特别是在移动端设备的小屏幕上也能表现出色。
图标描述模型的主要职责是对检测出来的图标进行功能性语义的理解,不仅要识别出图标本身,还要能够解释其在用户界面中的具体作用。
研究人员首先定义了一套详细的标签体系,涵盖了许多常见的图标类型及其对应的功能说明。例如,“搜索”图标通常代表查找功能,“设置”图标则指向系统配置选项。
基于这套体系,他们精心挑选并标注了一批高质量的图标样本,以便让模型学会如何根据视觉特征来推断图标背后的含义。为了增强模型处理未知图标的能力,训练过程中还特意加入了一些变异或非标准样式的图标案例,以提高GPT-4V的泛化能力,能够基于更丰富的信息作出更加合理的决策。

OCR则主要用于识别和转换图像中的文本内容。经过性能优化的OCR不仅可以轻松应对常规印刷体文字,还能有效处理手写体或其他特殊字体的情况。此外,为了进一步提高识别精度,研究人员还引入了预处理步骤,如图像去噪、倾斜校正等方式,确保输入至OCR引擎的图像质量达到最佳状态。
值得一提的是,OCR在集成到OmniParser整体架构后,与其他组件之间实现了无缝衔接。当可互动区域检测模型定位到某个包含文字的按钮或字段时,OCR模块便会被激活迅速读取其中的文字信息,极大提升了模型的识别能力和范围。
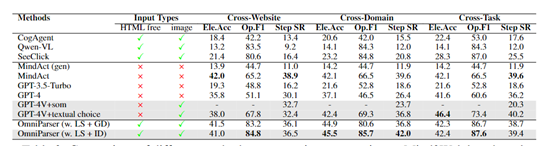
在多个基准测试结果显示,GPT-4V在与OmniParser集成后性能得到显著提升,超过同类模型。例如,在SeeAssign任务评估中加入局部语义信息后,GPT-4V正确分配图标的能力大幅提升;
在ScreenSpot基准测试中显著提高了GPT-4V在不同平台上的操作准确性;在Mind2Web基准测试中,其表现优于使用HTML信息辅助的GPT-4V;在AITW基准测试中,也使GPT-4V在移动导航任务中的表现得到显著提升。
来源:AIGC开放社区
好文章,需要你的鼓励


Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
火箭实验室(Rocket Lab)宣布计划以现金加股票方式,斥资80亿美元收购主要卫星运营商铱星通信(Iridium Communications),交易预计于2027年中完成。铱星目前运营着由66颗活跃低轨卫星组成的星座网络,拥有约255万活跃用户,2024年营收达8.717亿美元。收购完成后,Rocket Lab计划借助其新型重型运载火箭Neutron及Lightning卫星平台,扩大铱星星座规模,开拓未被覆盖的市场并降低发射成本。

腾讯混元视觉团队打造“图像翻译官“:让AI用离散数字读懂每一张照片
腾讯等机构提出ViQ框架,通过两阶段渐进量化训练,让离散视觉编码在多模态理解和图像重建上同时追平连续特征编码器,训练速度最高提升70%。

Tidal宣布将为AI生成音乐添加标签并移除欺诈内容
音乐流媒体平台Tidal宣布,将于7月中旬启用自动化工具,对完全由AI生成的音乐添加"AI"标识,并移除具有欺诈性质的曲目。平台还将取消AI生成音乐的版税资格,仅向真人创作、演唱的原创音乐开放变现渠道。此外,Tidal明确将高频异常上传、干扰真实艺术家等行为列为欺诈活动。Deezer、Spotify等竞争对手此前已推出类似检测机制,流媒体行业正加速构建AI内容治理体系。

香港科技大学联手华为研究院:AI绘图训练速度提升2.78倍,秘诀藏在“概率分工“里
香港科技大学与华为联合提出LISA训练方法,通过让副网络对齐"似然分数",将ControlNet等图像生成模型的训练收敛速度提升逾2.78倍,同时改善图像质量与条件控制精度。
2024
11/04
11:04
分享
点赞

