
英伟达发布通用机器人模型RVT-2,训练效率提升6倍
随着AI技术的飞速发展,在工业和家庭领域中构建能够精确操作且仅需少量任务演示的通用实体机器人成为可能。例如,在工业制造中,人们希望实体机器人能够通过几次演示就学会高精度任务,如拧螺丝、搬货物等。
之前的PerAct、RVT等通用模型,在训练方面有一定的优势但还是有不少局限性。PerAct采用多任务模型,通过预测下一关键帧姿态来进行3D操作,但它使用的基于体素的场景表示限制了其扩展性。
RVT虽然解决了PerAct的一些功能缺陷,但在处理需要高精度的任务时仍存在困难。所以,英伟达的研究人员在RVT基础之上研发出了第二代,训练效率比第一代快6倍,推理效率快2倍,仅10次示范学习就能执行各种高精度任务。

在架构方面与RVT相比,RVT – 2进行了大幅度改进并引入了多阶段推理管道。在处理对象非常小且需要非常精确的抓手姿态的任务时,例如,在孔中插入销钉,之前RVT使用的固定视图可能无法完成。
RVT - 2采用了多阶段设计,在第一阶段使用固定视图预测感兴趣区域,然后在该区域进行放大并重新渲染图像,使用放大后的特写图像进行精确的抓手姿态预测。
RVT – 2还采用了凸上采样技术。RVT基于ViT,在预测热图时,会将图像tokens特征上采样到图像分辨率,这一过程内存消耗大。
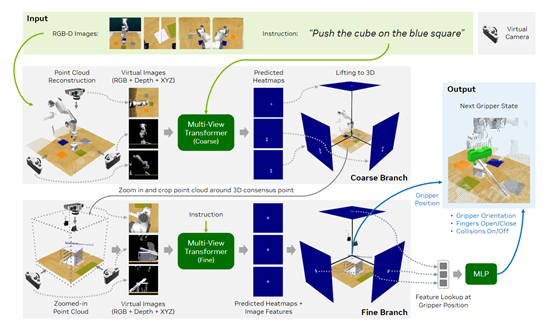
RVT - 2去除了特征上采样,直接从tokens分辨率的特征预测热图形状,使用凸上采样层,通过学习到的凸组合来进行预测,不仅节省了内存,还不会牺牲性能。
此外,RVT - 2对网络参数进行了合理化调整。RVT中一些网络参数,如虚拟图像大小和补丁大小,可能不是GPU友好的。R
VT - 2采用了类似于ViT的参数,如224的图像大小和14的补丁大小,这不仅使神经网络更适合GPU,还减少了多视图变压器内部tokens的总数,进一步提高了效率。
在旋转预测方面,RVT和PerAct使用全局视觉特征来预测末端执行器旋转,但当存在多个有效末端执行器位置且旋转依赖于位置时会出现问题。RVT - 2使用从末端执行器位置的特征图中汇集的局部特征进行旋转预测,实现了位置相关的旋转预测。
RVT渲染场景点云时使用了五个虚拟相机,分别放置在正交位置。但在RVT - 2的多阶段模型中,研究发现仅使用三个视图就足够了,且不会牺牲性能。
这是因为RVT - 2在最终预测中使用了放大后的视图,减少虚拟视图数量可以减少渲染器需要渲染的图像数量和多视图变压器需要处理的令牌数量,从而提高了训练和推理效率。
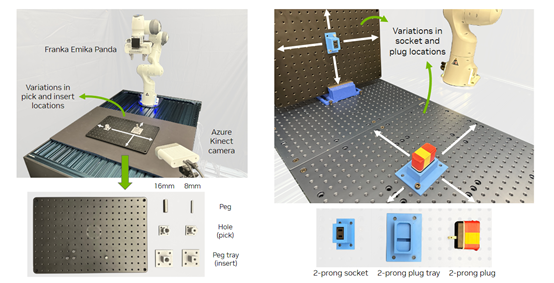
为了评估RVT - 2的性能,研究人员在模拟和现实世界中进行了综合实验。在模拟实验中,使用了RLBench中的18个任务进行测试,包括推按钮、放置物品和需要高精度的插销等任务。每个任务有2到60个变化,如处理不同颜色或位置的对象。
实验结果表明,RVT - 2在训练时间和性能上显著优于之前的模型。在训练时间方面,RVT - 2在相同计算资源下比RVT训练效率快6倍,推理效率快2倍。
在现实世界实验中,除了RVT中使用的堆叠方块、按压消毒器、将标记物放入杯子/碗中、将物体放入抽屉、将物体放入架子5个任务外,还增加了三个来自IndustRealKit的高精度任务,拾取并插入16mm销钉、拾取并插入8mm销钉、拾取并插入插头。
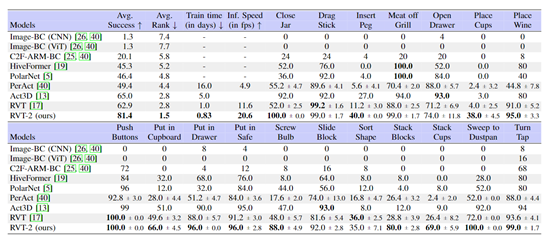
实验结果显示,RVT - 2在5个来自RVT的任务中,比RVT的性能相对提高了12.5%。在所有3个新的高精度任务上,RVT - 2的平均成功率为53.3%,而RVT为33.3%。
论文地址:https://arxiv.org/abs/2406.08545
好文章,需要你的鼓励


米拉·穆拉提重返公众视野,谨慎发声
穆拉蒂时隔18个月首次接受重大媒体采访,介绍其创立的Thinking Machines Lab正在开发的"交互模型"。该模型能以200毫秒间隔处理音频、文本和视频流,捕捉人类交流中的中断、修正和停顿。她还谈及OpenAI"政变周"经历,强调行业决策权过于集中的担忧,并回应了公司近期研究人员离职问题,表示这是初创实验室的正常波动。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
本期《Quick Charge》播客涵盖多个热点话题:特斯拉疑似试图删除FSD欺诈相关证据以规避巨额赔付;卡特彼勒持续推进建筑领域电气化布局;住宅太阳能30%税收抵免即将到期。此外,嘉宾Tom Pacheco就高压系统与电池技术培训展开探讨,强调电动车技术人才培养的紧迫性。节目同时提醒有意安装太阳能的用户尽快行动,可通过EnergySage平台比较多家安装商报价。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。
2024
12/30
11:04
分享
点赞

