书生·浦语大模型升级,突破思维密度,4T数据训出高性能模型
上海人工智能实验室对书生大模型进行重要版本升级,书生·浦语3.0(InternLM3)通过精炼数据框架,大幅提升了数据效率,并实现思维密度的跃升。仅使用4T训练数据的InternLM3-8B-Instruct,其综合性能超过了同量级开源模型,节约训练成本75%以上;同时,书生·浦语3.0首次在通用模型中实现了常规对话与深度思考能力融合,可应对更多真实使用场景。
“尺度定律”之下,大模型除了要突破算力瓶颈,亦面临高质量数据即将“见底”难题。如何通过“通专融合”技术路径实现通用人工智能,正日益成为业内共识。
1月15日,上海人工智能实验室对书生大模型进行重要版本升级,书生·浦语3.0(InternLM3)通过精炼数据框架,大幅提升了数据效率,并实现思维密度的跃升。仅使用4T训练数据的InternLM3-8B-Instruct,其综合性能超过了同量级开源模型,节约训练成本75%以上;同时,书生·浦语3.0首次在通用模型中实现了常规对话与深度思考能力融合,可应对更多真实使用场景。
体验页面:https://internlm-chat.intern-ai.org.cn(点击文末阅读原文直达)
GitHub链接:https://github.com/InternLM/InternLM
HuggingFace链接:https://huggingface.co/internlm
ModelScope链接:https://www.modelscope.cn/models/Shanghai_AI_Laboratory/internlm3-8b-instruct
数据是大模型能力提升的重要“推进剂”。目前主流开源模型多以扩大预训练数据规模作为性能提升路径,预训练数据量普遍接近20T token,训练成本也随之线性增长,同时也引起业内关于数据瓶颈和Scaling Law可持续性的思考。
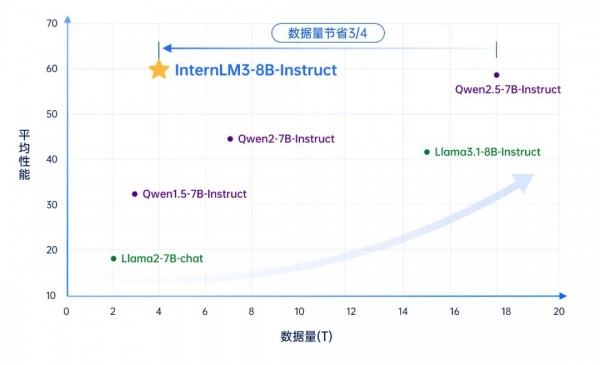
上海AI实验室研究团队认为,数据质量的提升带来的增益会显著高于数据规模的提升,而数据的“思维密度”(IQPT,Intelligence Quality per Token)是数据质量的核心,即数据的思考过程中蕴含的逻辑性、复杂性、启发性等。为此,团队提出大规模数据精炼框架,大幅提高了训练数据的质量。在具体实践中,书生·浦语3.0仅使用4T token的预训练数据,即实现主流开源模型18T数据的训练效果。通过构建数据“思维密度”杠杆,撬动模型性能提升,为突破Scaling Law带来了新的研究范式。
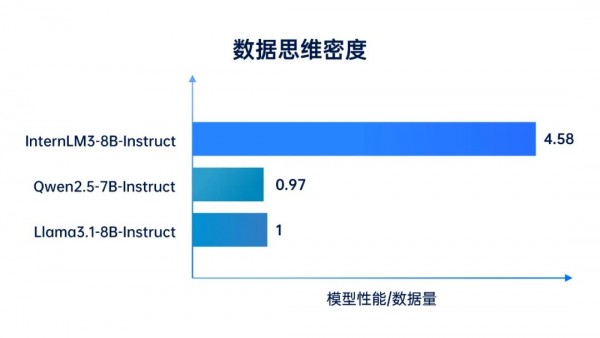
为了更好评估数据“思维密度”的影响,研究人员对指标进行量化定义,将数据思维密度(IQPT,Intelligence Quality per Token)定义为模型平均性能与训练数据量的比值,可以衡量大模型训练数据的“投入产出比”。对比国内外性能领先的同量级开源模型,以Llama3.1作为基准,书生·浦语3.0的数据思维密度高出4倍以上。
通过数据精炼框架,研究团队使书生·浦语3.0大幅提升了数据效率,实现思维密度的跃升。该框架包括以下两个核心要素:
-
数据处理的智能化:为了实现数据的精细化处理,研究团队将数据分为千万个领域,在此类人力难以负担的规模上,通过智能体自我演进技术,大规模自动化质检,根据错例进行反思,为每个领域进行定制化处理。
-
高价值数据的合成:基于通专融合的方式,以通用模型快速迭代合成算法,再精选数据训练专用模型,通过在海量天然数据中进行素材挖掘,改进的树状搜索策略,以及多维度质量验证,合成大量内容丰富,质量可靠的高价值数据。
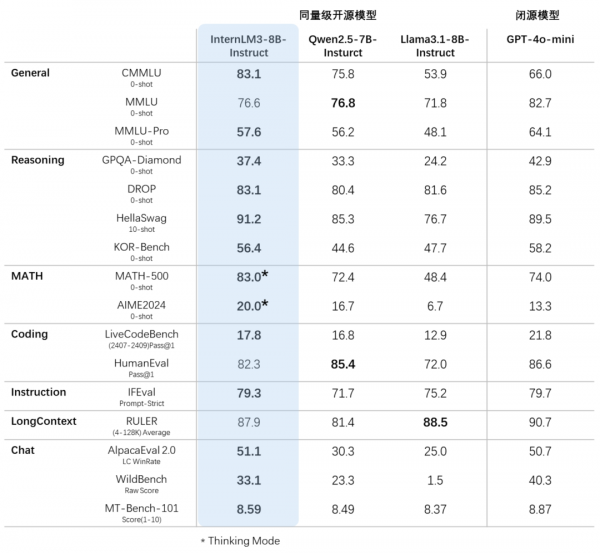
基于司南OpenCompass开源评测框架,研究团队使用统一可复现的方法,对书生·浦语3.0等模型进行了评测。评测采用了CMMLU、GPQA等十多个权威评测集,维度包括推理、数学、编程、指令跟随、长文本、对话及综合表现等多方面性能。评测结果显示,相比同量级开源模型,书生·浦语3.0在大多数评测集得分领先,综合性能十分接近GPT-4o-mini。
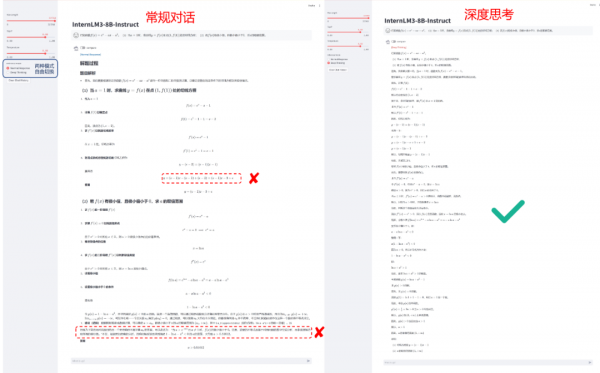
以“通专融合”路径探索通用人工智能,其关键技术之一在于同步提升深度推理与专业泛化能力。本次发布的书生·浦语3.0,首次在通用模型中实现深度思考与常规对话融合,一个模型就能应对更多真实使用场景。
由于深度思考和常规对话的数据风格存在较大差异,当前业界普遍针对强推理能力单独构建专用模型。此前,上海AI实验室亦发布了强推理模型书生 InternThinker,其具备长思维能力,并能在推理过程中进行自我反思和纠正,在数学竞赛评测集上超越了 o1-preview。基于通专融合的技术路线,研究团队探索了不同类型数据的融合训练方案,使得书生·浦语3.0 同时具备常规对话和深度思考能力,通过系统提示词(system prompt)的控制,可以让单一模型在两种模式间的一键切换,让通用模型具备深度思考能力。
在后训练阶段,研究团队还构建了以任务场景和知识体系驱动的合成数据探索方案,探索了基于世界知识树(World Knowledge Tree)的指令标注与合成方案,并运用基于多智能体的方式构建生成了高质量的回复。通过充分挖掘用户真实指令和合成指令的潜力,进行了多任务场景精细化分类,打造了数十万高质量微调指令数据集,从而大幅提升模型的对话体验。
如下图所示,在进行推理任务时,用户可以将书生·浦语3.0从常规对话模式一键转变成深度思考模式。
在研究范式创新及模型能力提升的基础上,上海AI实验室持续推进以高质量开源赋能创新,通过推出开源基座模型、全栈开源工具链、各类开源框架等形式,让产业界及开发者便捷实现书生系列模型的训练、部署与应用。同时,基于DeepLink开放计算体系,实验室与昇腾、寒武纪、沐曦等算力硬件厂商开展合作,在新兴算力硬件上实现了书生·浦语3.0的微调训练与高效推理,从软硬件多角度共同促进AI生态繁荣。
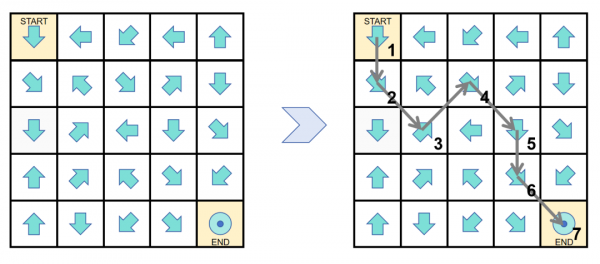
书生·浦语3.0可用于解答有趣的推理谜题,在箭头迷宫问题中,让模型在棋盘格中找到从起点到终点的可行路径。这道题目需要空间理解和算法综合应用能力,对于OpenAI o1模型而言也极具挑战。
书生·浦语3.0通过深度推理,圆满地找到了可行的路径:
对于经典的猜数字问题,书生·浦语3.0也可轻松应对:
在“高智商”之外,书生·浦语3.0同样拥有“高情商”和优秀创作能力。
书生·浦语3.0也将深度思考能力拓展到了智能体任务,成为了开源社区内首个支持浏览器使用的通用对话模型,支持20步以上网页跳转以完成深度信息挖掘。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。