
强推理模型书生InternThinker开放体验:自主生成高智力密度数据、具备元动作思考能力

上海人工智能实验室(上海AI实验室)致力于通过“通专融合”路径探索开放、可控、可信的通用人工智能(AGI),其关键技术之一在于同步提升深度推理与专业泛化能力。
2024年11月25日,上海AI实验室展示了自主生成高智力密度数据、具备元动作思考能力的“模型”等一系列创新进展,并开放强推理模型书生InternThinker试用体验。该模型具备长思维能力,并能在推理过程中进行自我反思和纠正,从而在数学、代码、推理谜题等多种复杂推理任务上取得更优结果。
试用链接:https://internlm-chat.intern-ai.org.cn(点击文末“阅读原文”直达,登录后点击左侧InternThinker即可体验)。
在OpenAI o1模型发布之前,上海AI实验室就已开展了相关技术的独创性探索与实践:在训练数据侧,在国内率先开发出大规模合成数据技术;在任务场景侧,新模型在数学、代码、推理谜题等多种场景都能体现出较强的推理能力,并具备一定的任务泛化性。
上海AI实验室的研究团队创新性地设计了元动作思考范式来引导模型的搜索空间,使模型更高效地习得和产生多样化的推理策略组合;基于通专融合的方式进行数据合成,并通过构建大规模沙盒环境获取反馈,在不依赖o1这类已有强推理模型的情况下,实现高质量思维链的独立构建,并大幅提升模型的复杂任务处理性能。
强大的推理能力是迈向通用人工智能的重要基础,今年7月发布的书生·浦语2.5实现了开源模型中领先的推理能力,InternThinker则使大模型的推理能力再上新台阶。下一步,上海AI实验室将把相关技术融入下一代书生大模型,并继续沿着通专融合发展路径,通过开源与产学研各界共同推动技术进步。
“元动作”思考:提升推理策略习得效率
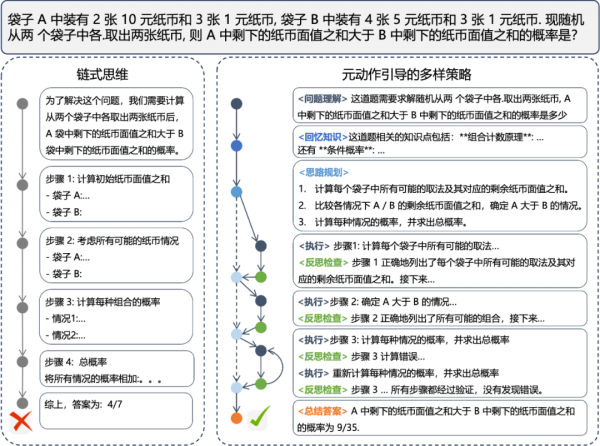
“通专融合”探索高密度监督数据路径
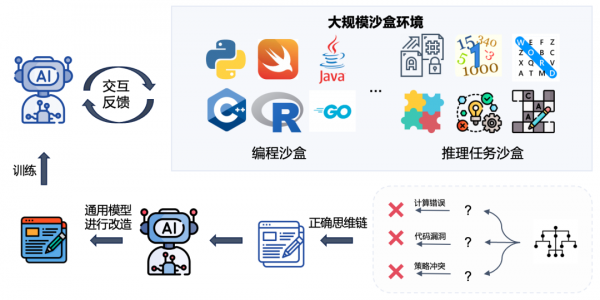
高密度监督数据路径框架
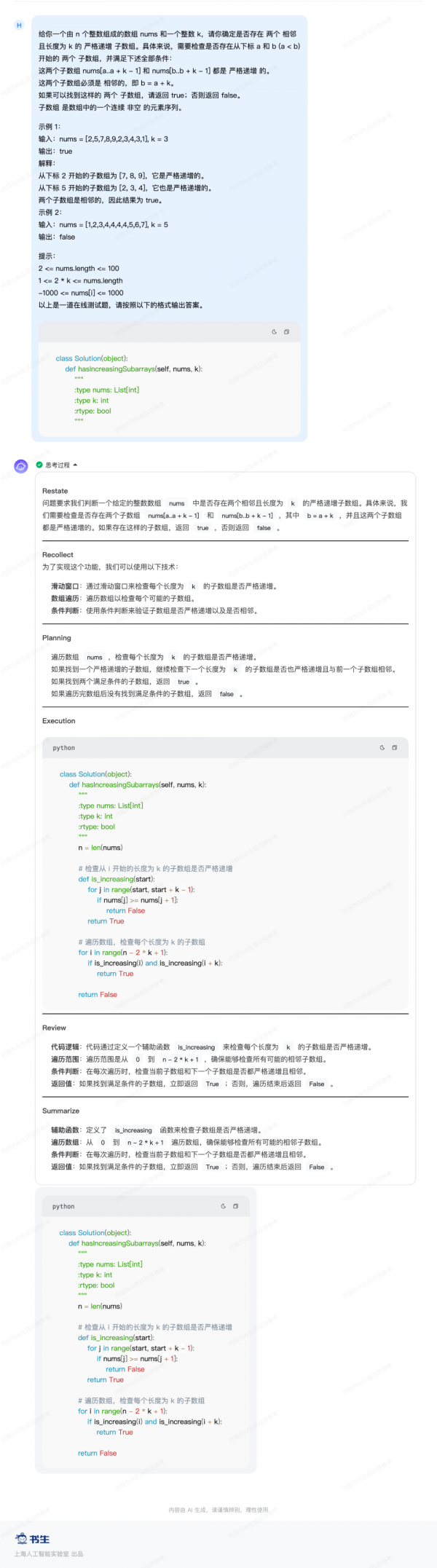
体验案例









好文章,需要你的鼓励


AI对就业的影响:大规模裁员背后的真相与数据
近期数据显示,2026年5月前企业已宣布约9万个与AI相关的裁员岗位,部分预测称未来五年美国15%的工作将被AI取代。然而,Ramp与Revelio Labs追踪近2.2万家企业的最新报告显示:重度投入AI的企业反而实现了更快的人员增长,包括初级岗位在内的各职能人数均有上升。但这一数据主要来自技术型企业,能否普遍适用仍存疑。报告同时指出,资源匮乏的企业可能在AI浪潮中持续落后。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

AI重复申请问题推动电网转向“承诺优先“规划
AI数据中心开发商向多家电力公司同时提交大负荷接入申请以确定选址,导致区域需求预测虚高、电网投资失衡。美国联邦能源监管委员会(FERC)及ERCOT、PJM、SPP等机构正推动"承诺优先"规划机制,要求项目具备实质性商业承诺方可纳入长期传输规划。谷歌、亚马逊、微软、OpenAI等科技巨头支持建立标准化的项目成熟度评估体系,但各方在具体机制上仍存分歧。发电建设问题尚未被纳入联邦传输改革议程。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。

