
自动驾驶汽车的未来趋势:集中式传感器融合
现如今,大多数自动驾驶汽车都依靠传感器融合,即将毫米波雷达、激光雷达和摄像头的多传感器数据以一定的准则进行分析和综合来收集环境信息。正如自动驾驶汽车行业巨头们所证明的那样,多传感器融合提高了自动驾驶汽车系统的性能,让车辆出行更安全。
但并非所有的传感器融合都会产生相同的效果。虽然许多自动驾驶汽车制造商依靠 "目标级"的传感器融合,但只有集中式传感器前融合才能为自动驾驶系统提供最佳驾驶决策所需的信息。接下来我们将进一步解释目标级融合和集中式传感器前融合之间的区别,以及解释证明集中式前融合不可或缺的原因。
集中式传感器前融合保留了原始传感器数据可做出更精确的决策
自动驾驶系统通常依靠一套专门的传感器来收集关于其环境的底层原始数据。每种类型的传感器都有优势和劣势,如图所示:
|
优势 |
劣势 |
|
|
毫米波雷达 |
可在不佳的天气条件下检测远距离的物体 性价比高 |
空间角分辨率差 不能辨别小物体 |
|
摄像头 |
可使用高清晰度图像和文本数据对物体进行分类检测 性价比高 |
能见度较低的环境下性能差 距离和速度测量性能不佳 |
|
激光雷达 |
可精确地检测物体的边缘 可生成高清晰的三维图像 |
能见度较低的环境下性能差 维护成本高 价格高 |
融合了毫米波雷达、激光雷达和摄像头多传感器后可最大限度地提升所收集数据的质量和数量,从而生成完整的环境图像。
多传感器融合,相对于传感器单独处理的优势已经被自动驾驶汽车制造商普遍接受,但这种融合的方式通常发生在 “目标级”的后处理阶段。在这种模式下,物体数据的收集、处理、融合和分类都发生在传感器层面。然而,数据综合处理前,单个传感器通过对信息的预先分别过滤,使得对自动驾驶决策所需的背景信息也几乎都被剔除了,这使得目标级融合很难满足未来的自动驾驶算法的需要。
集中式传感器前融合则很好地规避了此类风险。毫米波雷达、激光雷达和摄像头传感器将底层原始数据发送到车辆中央域控制器进行处理。这种方法最大限度地提高了自动驾驶系统获取的信息量,使得算法能够获取全部的有价值的信息,从而能够实现比目标级融合提供更好的决策。
AI增强型毫米波雷达通过集中化处理大幅提升自动驾驶系统的性能
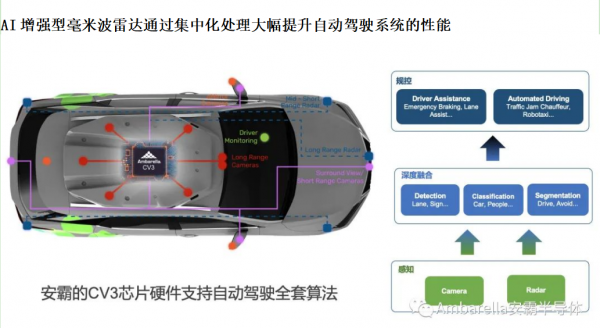
如今,自动驾驶系统已经集中式处理摄像头数据。但当涉及到毫米波雷达数据时,集中化处理仍然是不现实的。高性能的毫米波雷达通常需要数百个天线通道,这就大幅增加了产生的数据量。因此,本地处理就成了一个更具性价比的选择。
然而,安霸的 AI 增强的毫米波雷达感知算法在不需要额外物理天线的情况下,可以提高雷达角分辨率和性能。来自较少信道的原始雷达数据可以通过使用标准汽车以太网等接口,以较低的成本传送到中央处理器。当自动驾驶系统将原始的 AI 增强雷达数据与原始摄像头数据相融合时,它们就能充分利用这两种互补的传感方式来建立一个完整的环境图像,使融合后的结果更加全面,超越任何单一传感器所获得的信息。
毫米波雷达的更新迭代有助于降低成本,也大幅地提高自动驾驶系统的性能。传统的低成本雷达量产时,每个毫米波雷达的价格可以低于 50 美元,比激光雷达的目标成本低一个数量级。与无处不在的低成本摄像头传感器相结合,AI 雷达提供了可接受的精确度,这对大规模商业化的自动驾驶汽车量产至关重要。而激光雷达传感器与运行 AI 算法的摄像头/毫米波雷达感知融合系统相重叠,如果激光雷达的成本逐渐下降,将可作为摄像头 + 毫米波雷达在 L4/L5 自动驾驶系统中的安全冗余。
算法优先的中央处理架构深化传感器融合以优化自动驾驶系统性能
现行的目标级传感器融合有一定局限性。这是因为前端传感器都带有本地处理器,从而限制了每个智能传感器的尺寸、功耗和资源分布,从而进一步限制了整个自动驾驶系统的性能。此外,大量数据处理会快速耗尽车辆的动力并缩短其行驶里程。
相反,算法优先的中央处理架构实现了我们称之为深度、集中式的传感器前融合。该技术利用最先进的半导体工艺节点优化了自动驾驶系统的性能,这主要是因为该技术在所有传感器上动态分布的处理能力,以及能根据驾驶场景提升不同传感器和数据动向的性能。通过获取高质量、底层原始数据,中央处理器可以做出更智能、更准确的驾驶决策。
自动驾驶汽车制造商可以使用低功耗毫米波雷达和摄像头传感器,并结合尖端的算法优先的特定应用处理器,如安霸最近宣布的 5 纳米制程 CV3 AI 大算力域控制芯片,具备最佳感知和路径规划性能、具有最高的能效比,显著增加每辆自动驾驶汽车行驶里程的同时,降低电池消耗。
不要抛弃传感器——投资于它们的融合
自动驾驶系统需要多样化的数据才能做出正确的驾驶决策,只有深度、集中式的传感器融合才能提供最佳自动驾驶系统的性能和安全所需的广泛数据。在我们的理想模型中…
- 低功耗、AI 增强的毫米波雷达和摄像头传感器在本地与自动驾驶汽车外围的嵌入式处理器相连。
- 嵌入式处理器将原始检测级对象数据发送到中央域SoC。
- 使用 AI、中央域处理器分析组合的数据以识别物体,做出驾驶决策。
集中式传感器前融合可以改进现有的高层级融合架构,让使用传感器融合的自动驾驶汽车强大而可靠。为了获得这些好处,自动驾驶汽车制造商必须投资算法优先的中央处理器,以及支持 AI 的毫米波雷达和摄像头传感器。通过多方努力,AI 制造商可以迎来下一阶段的自动驾驶汽车发展的技术变革。
好文章,需要你的鼓励


5位IT领导者分享2026年新年决心
2025年AI占据了IT领导者的主要注意力,但现实检验显示,虽然三分之二的组织在生产中使用生成式AI,仅15%报告对收益产生积极影响。2026年,IT领导者将重新校准AI策略,减少技术债务。他们强调情商和人际技能在AI时代的重要性,关注"什么值得自动化"而非"能自动化什么",并致力于以人为中心的AI部署和技术债务管理。

上海AI实验室研究者想出妙招:让AI像优秀学生一样高效思考,告别“想太多“毛病
上海AI实验室开发RePro训练方法,通过将AI推理过程类比为优化问题,教会AI避免过度思考。该方法通过评估推理步骤的进步幅度和稳定性,显著提升了模型在数学、科学和编程任务上的表现,准确率提升5-6个百分点,同时大幅减少无效推理,为高效AI系统发展提供新思路。

罗技鼠标因证书过期在Mac上停止工作,需手动修复
罗技公司因苹果开发者证书过期导致其鼠标产品在Mac系统上停止工作。证书失效不仅使配套应用无法运行,还无法自动更新修复问题。Reddit用户首先发现MX Master 3S鼠标出现故障并找出根本原因。罗技承认这是不可原谅的错误,迅速创建支持页面提供手动修复指南。用户需下载Options+或G HUB的更新补丁安装程序,手动安装后可恢复设备设置和自定义功能。

MIT团队让机器人终于不再“卡顿“:一种让机器人像人一样流畅反应的突破性技术
MIT团队开发的VLASH技术首次解决了机器人动作断续、反应迟缓的根本问题。通过"未来状态感知"让机器人边执行边思考,实现了最高2.03倍的速度提升和17.4倍的反应延迟改善,成功展示了机器人打乒乓球等高难度任务,为机器人在动态环境中的应用开辟了新可能性。
2022
08/30
16:20
分享
点赞

至顶AI实验室硬核评测|落定个人AI超算下一块“拼图” NVIDIA DGX Spark实现本地千亿级参数模型推理
5位IT领导者分享2026年新年决心
罗技鼠标因证书过期在Mac上停止工作,需手动修复
经典系列回归,戴尔重启 XPS 产品线
戴尔、惠普、联想与苹果分道扬镳:选择可维修笔记本设计
MPS推出车规级TFT LCD偏压驱动IC,可广泛适用多种车载显示屏场景
戴尔科技为现代化容器应用提供灵活可靠的存储方案
飞利浦Hue照明系统即将推出SpatialAware空间感知功能
Aqara智能门锁U400发布:支持Apple Wallet全自动解锁
AI代码编辑器扩展推荐漏洞引发供应链安全风险
身份暗物质威胁企业网络安全的新挑战
Ambiq推出首款能耗优化NPU芯片组,为电池设备带来先进AI能力
