
一次AI开发1200万美元?华为盘古大模型说NO 原创
理论到实际应用是需要过程的。
比如5G从理论论文到应用有十年之长。任正非多次谈到,华为5G技术来自十多年前的土耳其教授的一篇论文。2008年,土耳其Erdal Arikan教授提出极化码(Polar code)理论之后,一个月后,华为从期刊上了解并评估了阿勒坎的论文,意识到这篇论文的重要性,之后十年,基于该理论,华为5G编码技术实现突破并开始全球应用。
同样目前火热的AI大模型也不是横空出世,在ChatGPT 火热之后,我们看到的ChatGPT 是2018基于OpenAI实验室研发的GPT模型(Generative Pre-trained Transformer)开发的。但其原理也是Google公司在2017年开源的Transformer神经网络架构而来的。
ChatGPT的火热,也让国内AI企业积极推出自己的AI大模型,有代表性的是百度、阿里各自推出自己的对话大模型,一个是一言,一个是千问,还有一个受到大家关注的是华为盘古大模型。
前两天,我们看到在中国人工智能学会主办的人工智能大模型技术高峰论坛上,华为云AI领域首席科学家、国际欧亚科学院院士田奇出席现场,对华为盘古系列大模型的研发与应用落地情况进行了分享。
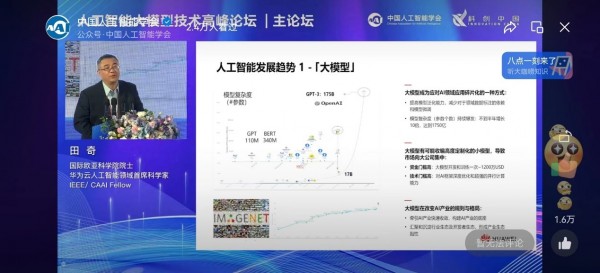
我们从田奇的分享可以看到,华为盘古大模型的当下的服务方式还是更实际一些,AI好不好用,包括算力、算法和数据三部分。这三个部分面临的挑战,田琦奇给点了出来,那就是AI大模型有两个高门槛:
一个是资金门槛高,开发和训练一次花费约1200万美元,一个是技术门槛高,需要对AI框架深度优化和超强的并行计算能力。
那么这两个门槛就让绝大部分的企业和用户挡在在AI大模型研发之外,华为的思路是就是解决传统AI开发面临作坊式开发、样本标注代价大、模型维护困难、模型泛化不足、行业人短缺等难题。这也是盘古大模型的价值和意义。
比如华为开放了盘古大模型开发的全流程大模型使能套件,包括TransFormers大模型套件MindSpore TransFormers、以文生图大模型套件MindSpore Diffusion、人类反馈强化学习套件MindSpore RLHF、大模型低参微调套件MindSpore PET,支撑大模型从预训练、微调、压缩、推理及服务化部署。
当然在“大模型时代”,到底如何实现价值,我们看到华为盘古大模型的思路是首先在强化大模型能力,实现在各垂直领域落地,通过参数微调,适配多个场景。所以华为盘古大模型所提供的服务更广,不仅提供像chatGPT一样的NLP大模型底座,还可以提供CV大模型、科学计算大模型等基础大模型。
同时华为盘古大模型还有一个特点是更灵活,据田奇介绍,在CV大模型和科学计算大模型的多个应用场景。矿山大模型、铁路巡检方案等,面向科学领域的盘古气象大模型、药物分子大模型、海浪预测大模型等。

当然个人建议,包括chatGPT在内的预训练大数据模型的原理是通过预测说话过程中的每个词和每个词的结合概率来生成语句。比如“我喜欢喝啤”,那下一个字的概率是什么,相信大家都知道。当然实际上现在模型已经实现了更复杂的的语音预测。包括词和词的概率,每一个句子的意思和下一个句子的意思,段落和段落的逻辑等。这么看来,有一些场景,预训练模型并不合适,包括气象、股市、经济等混沌事件就不适合预训练模型,因为这些场景,数据越多,越不确定,预测难度就越大。形成了一个死循环。
总之,当前大模型效果如何,还是让子弹飞一会,时间会检验的。同时我期待各个大模型企业可以形成直接的技术壁垒,技术护城河,但是不用形成技术傲慢,也就是你提供的AI产品应该是越来越简单,而不是越来越复杂,让人们望而生畏,那就不是AI护城河了,那就是AI霸权了。
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2023
04/10
11:19
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
