评测结果超过GPT-4,Anthropic发布第三代大语言模型Claude3,具有多模态能力,实际评测表现优秀!但幻觉问题不小!
Anthropic被认为是最像OpenAI的一家公司。他们推出的Claude2模型是全球首个支持200K超长上下文的商业模型。在PDF理解方面被认为表现优秀。就在2023年3月4日,Anthropic推出了他们的第三代大语言模型Claude3,包含3个不同的版本,支持多模态和最高100万上下文输入!
-
Claude3系列模型简介
-
Claude3系列模型的评测结果
-
Claude3能更少地拒绝回答用户问题
-
Claude3系列模型不同的应用
-
Claude3当前如何使用
-
Claude3实际测试
Claude3系列模型简介
Claude3系列模型包含3个版本,分别是Claude3-Opus、Claude3-Sonnet和Claude3-Haiku,能力从高到低依次下降,成本也随之下降。尽管官方没有透露Claude3这三个版本模型的参数细节和模型架构。但是从成本和表现结果来看,参数应该是逐次递减的。
三者的区别对比如下:
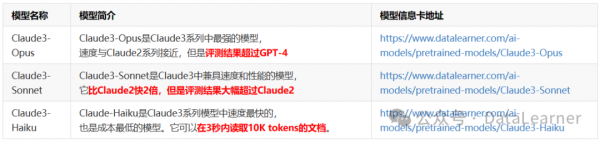
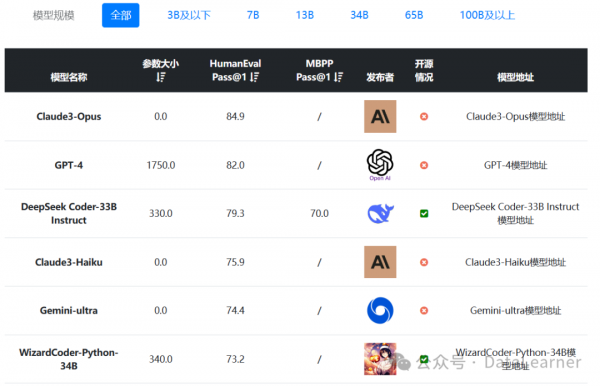
从上表中可以看到,这三个模型各有特色,其中Claude3-Opus在多项评测结果中超过了GPT-4,因此也是最被大家期待的模型。
Claude3系列模型的评测结果
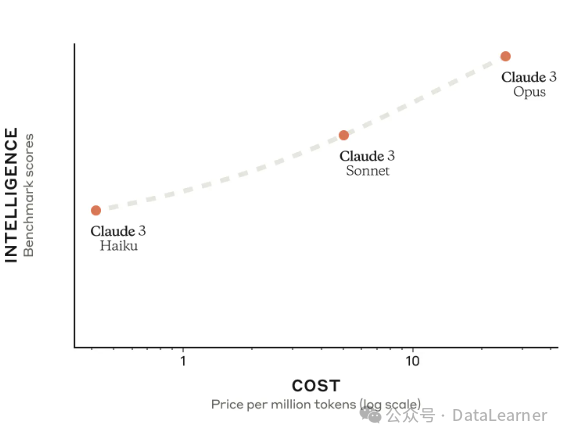
Claude3系列模型在各项评测结果中表现都非常好。下图是DataLearnerAI收集的关于Claude3与其它模型的对比结果,按照GSM8K排序降序。
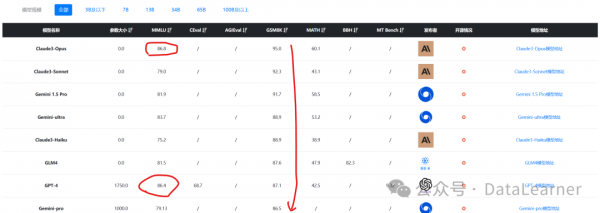
从这个表格中可以看到,Claude3三个模型在GSM8K上的得分都非常高。而按照MMLU排序的话,Claude3-Opus得分86.8,略超GPT-4的86.4,超过了Gemini Ultra的83.7,是目前全球的分最高的预训练模型了。
除了文本理解和数学能力外,Claude3-Opus在代码生成方面表现也非常好。在HumanEval 5-shot评测上得分84.9,超过了GPT-4,也是全球目前排名第一的模型。
Claude3能更少地拒绝回答用户问题
此前,Claude模型最被大家诟病的就是它经常拒绝回答用户问题。由于Anthropic做了过度的对齐优化,导致Claude2.1模型经常错误的拒绝回答用户问题。例如当用户问“如何杀死一个进程”这样一个计算机问题,Claude会认为这是不道德的拒绝回答。此次发布的Claude3模型,官方说它可以更加准确理解用户意图,在错误的拒绝方面表现更好。
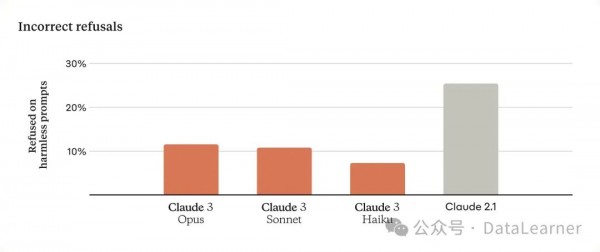
上图是Anthropic的内部测试,结果显示,相比较Claude2.1错误拒绝概率高达26%左右,Claude3系列模型的错误拒绝概率都有较大的下降,最高的Claude3-Opus也就只有12%左右。
Claude3系列模型不同的应用
官方也给出了三个模型的不同应用场景,帮助大家如何选择模型。而这些应用场景其实也是我们在做大模型应用时候需要考虑的模型能力和成本的权衡因素。
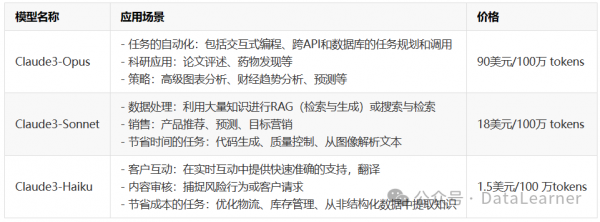
从上面的对比可以看到,越强大的模型,越能处理复杂的任务,价格也更贵。而相应的,目前最新的GPT-4的接口价格是40美元/100万 tokens,比Claude3-Opus还是便宜不少。gpt-3.5-turbo价格是9美元/100万tokens,因此Claude3-Haiku的价格是gpt-3.5-tubo的1/6,如果能力与gpt-3.5差不多的话,那是非常有吸引力的。
此外,这三个Claude3模型都支持最高200K的上下文输入,而官方说的是Claude3-Opus未来可以支持100万的上下文输入!另外,Claude3的模型全部是多模态大模型!支持图像理解和图像生成!
Claude3当前如何使用
目前Claude3-Opus和Claude3-Sonnet都可以通过API接口使用,因此开发者可以直接调用测试。而免费版本的Claude聊天服务也是直接上了Claude3-Sonnet,大家可以直接测试。至于最快最便宜的Claude3-Haiku,大家还需要等等。
Claude3实际测试
我们做了几组测试,Claude3-Opus模型的结果令人满意。
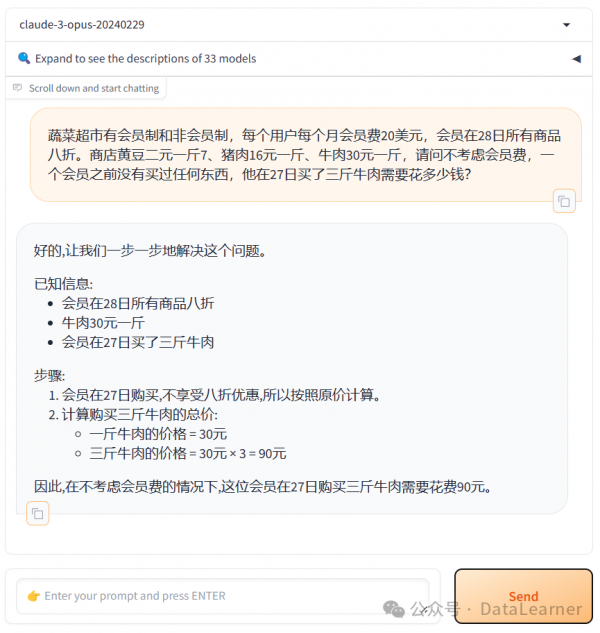
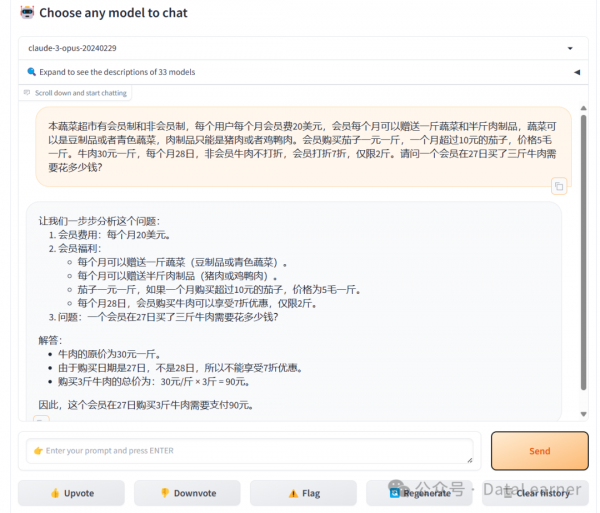

不过我们测试中也发现一个问题,Claude3的模型幻觉比较严重,如果没有给牛肉价格,它会自己给一个价格,这个价格其实我们没有提到。而GPT-4则会用x代替没有给出的价格。
好文章,需要你的鼓励


AI时代Chiplet设计中不可或缺的可观测性层
在基于Chiplet的架构中,可观测性正成为系统设计的关键缺失环节。多位半导体行业专家指出,AI可从硅层遥测数据中挖掘价值,但前提是架构须提供一致的检测手段、近传感器数据压缩及可编程采集能力。专家们强调,多供应商Chiplet生态系统需要标准化、安全的遥测模式,以实现跨芯片、封装和互联域的故障定位,同时保护敏感运营数据。目前,AI在遥测分析阶段已展现出显著价值,但可观测性的扩展本质上仍是架构问题。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

从传统CRM迈向智能化客户互动的转型之路
生命科学企业在全渠道战略和AI平台上投入巨大,但成效往往不尽如人意。问题根源不在于技术本身,而在于组织架构、数据治理和工作方式未能同步演进。许多转型项目止步于试点阶段,原因是各部门数据孤立、职责不清。要实现从传统CRM向智能互动的真正转型,企业需优先建立统一的数据基础和跨团队协作机制,并将AI能力嵌入日常工作流程,而非将其视为独立模块。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2024
03/06
14:04
分享
点赞