
MiniGPT4-Video:让大模型分析视频内容,依然有难度 原创
Sora的发布,让文生视频成了过去几个月里最热门的一个话题,与此同时,行业里也涌现出了不少与视频内容分析相关的多模态大模型应用。
MiniGPT4-Video就是最近面世的与视频相关的多模态大模型应用之一。
该应用由KAUST和哈佛大学研究团队在今年4月发表的论文中提出,是一个专为视频理解设计的多模态大模型框架。

这一研究团队在论文中指出,在MiniGPT4-Video出现之前,行业中已经有诸多多模态大模型的研究项目,诸如MiniGPT、Video-ChatGPT等,但这些研究项目各有缺陷,例如Video-ChatGPT在对视频中内容进行转换过程中,往往会造成信息丢失,而且无法充分利用视频中的动态时间信息。
他们提出的MiniGPT4-Video是通过将每四个相邻视觉标记连接,减少了标记数量,同时也降低了信息损失对应用带来的影响。
与此同时,他们通过为视频的每一帧添加字幕,从而将每一帧表示为由视频编码器提取的视觉标记与由LLM标记器提取的文本标记的组合,这让大模型能够更全面地理解视频内容,从而同时响应视觉和文本查询信息。
众所周知,对于多模态大模型而言,数据最为关键。
据悉,为了训练MiniGPT4-Video,该研究团队用到了三个数据集:
第一个数据集是包含了15938个浓缩电影视频字幕的视频作为数据集(CMD),在这个数据集中,每个视频长度为1-2分钟;
第二个数据集是牛津大学发布的一个拥有200万视频量的开源数据集Webvid,为了和CMD数据保持一致,该研究团队将这一数据集中的数据也都裁剪到了1-2分钟;
第三个数据集是一个拥有13224个视频、100000个问答对话和注解的数据集,这个数据集中的数据质量很高,不仅针对视频内容提供了平均57个单词组成的问题答案,这些问题还涵盖多种问题类型,例如视频摘要、基于描述的QA,以及时间、空间、逻辑关系方面的推理。
由此研发出的这样一个MiniGPT4-Video模型,究竟能有什么用?
该研究团队在研究过程中,一共测试了MiniGPT4-Video三项能力:视频ChatGPT能力、开放式问题回答能力、选择题回答能力。
作为通过视频数据训练的多模态,MiniGPT4-Video最核心的能力其实是开放式问题的回答能力。
就这一能力,至顶网分别找了三个视频进行了实际测试——一个是由Pika生成的3秒煎肉视频、一个是42秒的机器人演示视频、一个是50秒的《老友记》节选片段。
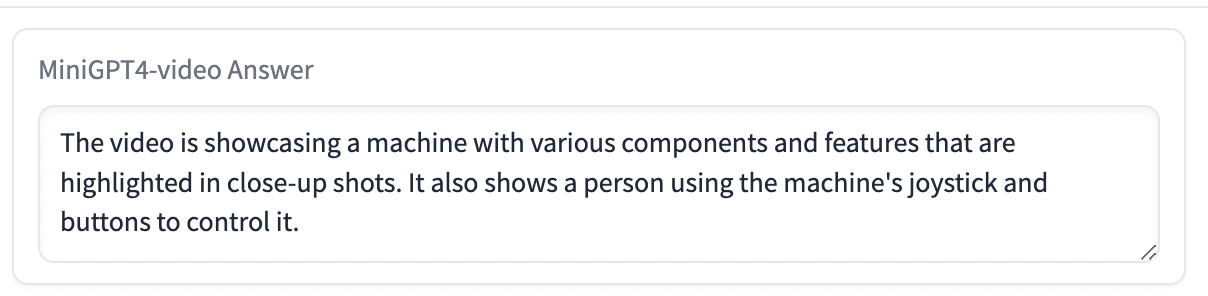
先说测试结果,将三个视频分别上传,并对MiniGPT4-Video进行提问——“这个视频谈了什么?”后,最终只有第二个视频给出了完整的答案,给出的答案与视频内容基本一致。
由此可见,现在的MiniGPT4-Video在做视频内容解析时,不仅对视频长度有要求,对视频质量同样有较高的要求,第二个视频之所以能有不错的输出结果,主要是因为视频内容逻辑性更强,而且有一些字幕介绍。

不过,针对第二个视频,我们就同一问题进行了多次提问,给出的答案并不一致,这是生成式AI的特性,第二次给出的答案还将视频中的机器人识别成了人,整体描述也出现了错误。
现在看来,MiniGPT4-Video在实际使用时,仍会存在各种各样的问题,还有待研究团队继续调优。
好文章,需要你的鼓励


亚马逊Mechanical Turk停止接受新用户,众包平台走向终结
亚马逊旗下运营近20年的众包平台Mechanical Turk已停止接受新用户注册,并将于2026年7月30日正式关闭。该平台于2005年上线,早于AWS公有云业务,曾是全球知名的众包任务市场,涵盖验证码识别、情感标注等人工任务,后转型为AI训练数据标注工具。随着亚马逊推出SageMaker Ground Truth等替代方案,Mechanical Turk的历史使命已宣告终结。

当AI助手“看“电脑屏幕,就像让一个视力正常的人蒙眼操作——德克萨斯大学达拉斯分校的解法
LUMOS是一个让AI通过操作系统无障碍接口直接读取界面语义信息来操控电脑的中间层,避免依赖截图识别,降低AI电脑操作的资源消耗和出错率。

微软推出Memora,致力于解决AI智能体的记忆难题
微软研究院发布Memora记忆系统,旨在解决AI智能体在长期部署中记忆碎片化、检索效率低的问题。Memora通过将存储内容与检索方式解耦,引入"主抽象"与"线索锚点"双组件架构,在LoCoMo和LongMemEval两项基准测试中表现优异,上下文token用量最高可降低98%。但专家提醒,实际企业成本还需考虑索引、存储及合规审计,且该项目目前仍处于研究阶段,尚未达到生产就绪水平。

腾讯混元携手多所高校,让3D网格生成快如闪电——PolyFlow如何破解困扰业界多年的“拓扑难题“
腾讯混元联合多所高校提出PolyFlow,用流匹配模型并行生成艺术家风格3D网格,速度比自回归方法快百倍,几何精度达到新高。
2024
04/26
17:15
分享
点赞

亚马逊Mechanical Turk停止接受新用户,众包平台走向终结
微软推出Memora,致力于解决AI智能体的记忆难题
SGE计划在英国部署14座BWRX-300小型模块堆,总装机容量达4.2吉瓦
特斯拉在迈阿密划定Robotaxi小范围服务区,得克萨斯扩张仍受阻
Luxonis完成1400万美元融资,为智能自动化打造视觉感知层
.NET 8 与 .NET 9 即将停止支持,微软建议升级至 .NET 10
苹果供应商塔塔电子遭黑客攻击,iPhone 18 Pro核心机密外泄
美国解除对Anthropic旗下Fable 5和Mythos 5大语言模型的出口限制
Meta推出定制CXL芯片Vistara,让旧内存在新服务器中焕发新生
Bending Spoons完成180亿美元IPO,创始人谈如何将运气从成功方程式中剔除
浏览器大战进入新阶段:Chrome与Safari之外的最佳替代选择
华盛顿特区都会区迎来首批途中电动公交充电桩
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
