
不急于求成的雷鸟创新,想造出“年轻人的第一台AR眼镜” 原创
10月28日,在今年的秋季新品发布会上,雷鸟创新正式对外发布了雷鸟Air 3系列产品。
这是在雷鸟创新在今年陆续完成5亿元融资、XR光学和整机两大总部落地计划公布后,雷鸟对外发布的又一款新品。
值得注意的是,雷鸟此次发布的雷鸟Air 3用上了与TCL联合研发的孔雀光学引擎、与视涯联合研发的第五代Micro-OLED方案,还在画质调校、扬声器设计上下了大功夫。
雷鸟创新创始人兼CEO李宏伟在发布会上称,雷鸟创新希望借助这代产品,开创全民AR时代。

为此,雷鸟创新不仅将这代产品定价到了1699元,还发布了针对索尼屏幕进行了重新色彩调校优化的雷鸟Air 2三周年冠军版,并将这款产品定价到了1399元。
AR行业的歧途和正道
“大家都想将AR眼镜变成下一代计算平台,但91%的分体式AR眼镜用户主要使用AR眼镜来做两件事——观影和游戏。”
当前市场上大量AR公司在用户使用9%的场景里投入了90%的研发精力,李宏伟认为,现在的AR行业正在“误入歧途”。
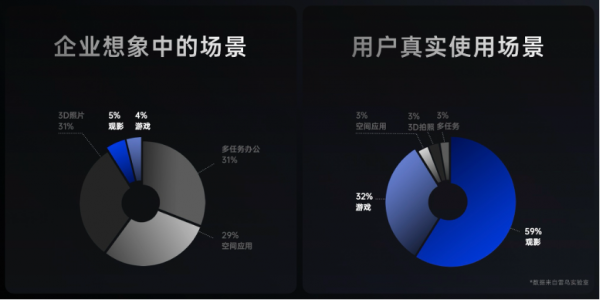
“雷鸟Air 3的定位十分清晰,即抛弃其他一切伪需求场景,专注于用户的观影和游戏体验,打造影音AR眼镜的下一代天花板。”李宏伟在发布会上如是说。
在李宏伟看来,当前的AR眼镜尚未成熟到可以完全取代手机的地步,离真正成为主流智能终端还有一段路要走。
因此,雷鸟创新一方面持续在最前沿的光波导技术上进行突破,以实现更高的显示效果和更轻便的佩戴体验。
实际上,前不久Meta对外发布并引起高度关注的AR眼镜Orion,用的也正是光波导技术路线。
此外,这代产品沿用了对观影体验更友好的BirdBath光学方案,并针对关键技术细节进行了优化,具体而言:
在画质上,雷鸟Air 3搭载了雷鸟创新与TCL联合研发的全新孔雀显示引擎,在光路系统上率先实现了多层高精度AR镀膜,有效减少杂光干扰,带来更纯净的画面。

Air 3实现了14mm*7mm的超大Eyebox面积,可适配93%的瞳距人群,使不同头型的用户都可以获得一致的清晰观影体验。
这代产品还搭载了雷鸟创新与视涯共同首发的第五代Micro-OLED,相比上一代产品,第五代Micro-OLED在降低功耗的同时,显著提升了显示效果,并实现了硬件级的抗疲劳保护,为长时间观影提供了专业护眼保障。

据雷鸟创新官方数据显示,雷鸟Air3能实现145% sRGB色域覆盖,650nits的入眼亮度和200000:1的对比度,使高光和暗部细节呈现更为丰富。
在护眼技术上,Air 3首次将高端手机的护眼科技引入AR眼镜领域,实现了双重护眼。雷鸟Air 3不仅延续了上一代的硬件防蓝光技术,还支持3840Hz的PWM高频调光,有效缓解用眼疲劳,并通过南德TUV防蓝光和抗疲劳双重认证。
在音质上,Air 3搭载了独家的双单元背靠背音频结构,声压级为行业平均水平的2.5倍,让眼镜音质表现达到新的高度,实现更为震撼的听觉体验。
全民AR时代要来了?
作为被视为科技感十足的硬件品类,如何推动这一品类在消费市场普及,让AR眼镜真正成为一种生活方式,是AR厂商需要考虑的问题。
作为国内核心玩家,雷鸟创新同样希望推动这一产品在国内普及开来。
为此,雷鸟创新将雷鸟Air 3定价到了2000元以内——1699 元。
李宏伟称,“雷鸟创新希望雷鸟Air 3的推出可以像电动汽车行业中的Model 3,依托行业领导者的地位,通过技术迭代和产业链联动,不断降低成本、提高品质,从而让价格触及更多消费者的可承受范围。”
实际上,此次雷鸟创新在新品上的定价策略背后,有赖于雷鸟创新核心部件和显示技术的自主研发,以及与供应链伙伴的深度合作。
雷鸟创新对产业链的深度整合,让雷鸟Air 3有了进一步进行市场下沉的可能。
此外,雷鸟创新还发布了定价1399元的雷鸟Air 2三周年冠军版,李宏伟称,雷鸟创新是希望这款产品可以成为“年轻人的第一台AR眼镜”。
聚焦用户最关心的“观影+游戏”体验,以高质量的显示和音效体验打破传统界限,为用户提供极致的影音享受,是雷鸟创新当下做AR眼镜的产品策略,也是李宏伟对当下AR行业的判断。
那么,不急于求成的雷鸟创新,能否打造出“年轻人的第一台AR眼镜”?
好文章,需要你的鼓励


一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

借鉴生态学模型评估AI风险的新方法
本文提出一种评估人工智能风险的新方法,借鉴生态学与演化论视角,从理论生态模型中推导出三项风险指标,涵盖种群模型与生态系统模型。研究旨在为AI治理策略提供量化工具,并对分析局限性及政策改进方向进行了深入探讨,为构建更科学的AI风险评估体系提供参考框架。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。
2024
10/28
23:09
分享
点赞

对标Ray-Ban Meta,现货发售的雷鸟V3能否卖出百万销量?
不急于求成的雷鸟创新,想造出“年轻人的第一台AR眼镜”
Meta Connect 2024,Meta 推出 Orion AR 眼镜、Quest 3S VR头显、Ray-Ban智能眼镜
雷鸟创新宣布完成多轮融资,2024年总融资金额超过5亿元
抢先苹果Vision Pro,雷鸟创新正式上线AI空间照片转换功能
布局2.2亿MAU市场,雷鸟创新携手谷歌发布全球首款AR版的Google TV
Vuforia 洞察 —— 来自 AR 领先者的观点
一年三轮融资!雷鸟创新完成新一轮亿元级融资
FFALCON雷鸟春季新品发布会亮点揭秘:鹤7 24款电视与Q8/U8显示器齐亮相
雷鸟X2 Lite亮相CES 2024:首发骁龙AR1平台,支持大模型语音助手
