
鲲鹏DevKit助力轩辕AI科学计算平台DataLab原生开发,性能提升89%
什么是科学计算平台?
科学研究是人们探索新事物、认知新规律、创造新技术的重要途径,随着人类社会的不断进步,今天科学研究已经前进到一个更加复杂深奥的世界,研究的对象也向着大范围、多领域的复杂系统工程进军。例如,航天工程、全球气候、生态环境问题等,对科研方法和手段也提出了新的挑战。
科学计算作为现代科研主要手段,广泛应用于信息检索、环境模拟、数值计算、数据分析等场景中,同时,机器学习的迅猛发展也推动着科学计算平台进入了百家争鸣的时代:各类统计软件、数据分析软件、仿真软件、制图软件多如牛毛……然而这种传统的、分散的科研方式,给科研工作带来了巨大挑战:
- 知识碎片化、孤岛化,难以建立起关联关系;
- AI模型搭建对编程技能要求高,时间成本巨大且后期训练优化费时费力;
- 人工处理复杂建模操作,效率低,高维方程求解难度大,精度和性能无法兼顾;
- 大量机器学习训练数据的采集、清洗和治理工作繁琐而枯燥;深度学习框架缺乏租户功能,难以实现资源的有效隔离和集群算力的有效管理。
工欲善其事,必先利其器。为了快速、实时的分析海量科学数据背后的意义、最大限度地满足科研机构和人员之间交流与协作的需要,基于现代信息技术的科研平台对于提高科研水平、促进学科交叉和融合、加强高层次创新人才的培养起着至关重要的作用。
轩辕研究院:
联合鲲鹏打造AI科学计算平台DataLab

轩辕研究院
是轩辕网络旗下的全资子公司,是围绕人工智能的科研和实训教学的新型研发机构,深耕教育行业23年,是国内领先的AI+产教融合服务商。该机构依托多年的高校的技术成果,以及丰富的产学研合作方式,将国内外先进的技术成果转化为科研应用技术和产品,助力科学技术的研究和创新。
轩辕AI科学计算平台DataLab是轩辕研究院联合广州“鲲鹏+昇腾”生态创新中心共同打造的辅助科研工作的一体化解决方案。该方案集鲲鹏算力、多领域科研样本数据、算法模型研发以及管理工具于一身,能有效支撑机器学习、神经网络、知识抽取、关联规律、智能预测、决策推理和高清科研图表输出等任务。可用于自然科学与社会科学研究,以及计算机、软件、电子、自动化相关科研团队进行计算机技术原理性的验证场景,基于算法、数据进行科研实验,并形成图形化界面呈现实验结果,攻关技术难题项目,助力科技成果转化和推广。

【轩辕AI科学计算平台DataLab解决方案架构】
伴随着科研数据持续爆炸性增长,科学家们需要更高的计算效率、数据处理效率以及工程效率,从而更好地支撑跨领域科研,这也对IT平台的算力提出了更高挑战。
- 鲲鹏天然的多核多并发、高性能、高算力以及低功耗等优势,能够很好的满足科研平台海量数据处理、并行计算、低时延、绿色计算等要求;
- 作为轩辕研究院AI科学计算平台DataLab的算力底座,鲲鹏还提供完善的鲲鹏DevKit开发套件以及专业服务,能够帮助用户快速完成应用的迁移、开发、编译和调优,支撑科研平台的高效创新。
鲲鹏DevKit 1人天/应用
快速迁移AI科学计算平台
在项目实施初期,开发人员需要将DataLab平台快速迁移到鲲鹏。由于整个系统的模块众多给迁移工作带来不少挑战:
- 代码量大:5个子模块个微服务,共计100万行左右代码;
- 第三方软件多:包含redis、rabbitmq、nacos、datax、hadoop,500+JAR包,手工查找兼容版本非常耗时;
经分析,采用手动迁移的话整个系统15个微服务需要30人天才能完成。
而鲲鹏DevKit代码迁移工具可以实现依赖文件自动识别、兼容JAR包一键下载、代码修改建议一键替换,无须耗时耗力检查跟进。在鲲鹏DevKit的帮助下整个系统只用了10人天,平均每个服务不到1人天即可完成自动迁移。
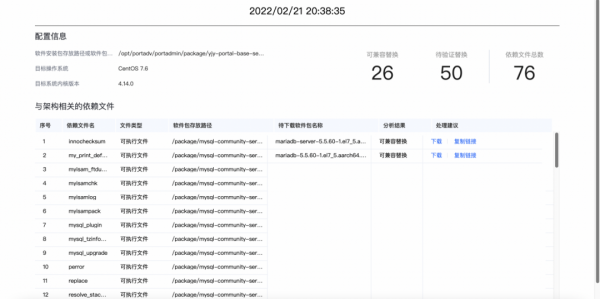
【使用鲲鹏DevKit代码迁移工具进行代码分析】
基于鲲鹏DevKit高效开发建筑违章检测算法模型,性能提升89%
迁移完成之后,轩辕研究院需要针对DataLab平台中GIS领域科研场景,在鲲鹏平台上新开发建筑违章检测算法模型。在开发过程中,为进一步提升业务性能和稳定性,将平台之前使用的OpenJDK换成毕昇JDK,毕昇JDK在鲲鹏架构中提供了更好的版本稳定性、GC(Gabarage Collector)性能、加解密性能,能够提升DataLab平台数据处理应用的运行效率。
此外,针对系统出现的性能瓶颈,轩辕研究院的技术人员使用了鲲鹏性能分析工具进行了调优,对操作系统、JVM的运行状态进行了分析和优化,提升DataLab平台AI计算模型相关业务的运行效率:
在系统性能分析中创建系统全景分析任务
通过采集系统软硬件配置信息,以及系统CPU、内存、存储IO、网络IO资源的运行情况,识别出CPU单次利用率高和两处热点函数占比较大的瓶颈,并给出了优化建议 ,解决了DataLab平台93093线程的38-CPU单次利用率高的问题,提高了平台运行性能。
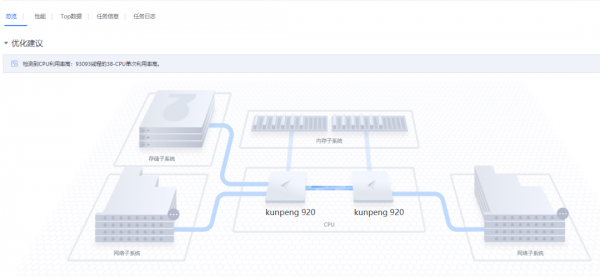
【AI科学计算平台DataLab系统性能调优-全景分析】
通过访存分析功能高阶分析能力
分析到应用存在跨片跨DIE的内存访问,并在系统建议下进行了进程绑核,从而优化各个微服务的硬件资源分配,提升计算资源利用率。
通过微架构分析对DataLab平台的操作系统进行采样分析
发现了badSpeculation的branchMispredic占比较高,以及代码中for循环嵌套的if判断存在大量分支预测响应失败情况,并针对上述问题给出了优化建议,对平台程序响应时间、内存分配等方面进行了性能优化。
通过Java性能分析
对平台的Java方法采样、线程转储、老年代对象采样等多种采样分析方式,经过调整垃圾回收器的配置策略,改善查询业务的吞吐量;
通过上述一系列的优化分析,轩辕研究院DataLab平台在鲲鹏上运行性能得到有效提升:比如对比鲲鹏DevKit优化前后,模型查询业务的平均响应时间典型场景下(1分钟200并发)缩短27%,极限压测场景下(1分钟10000并发)缩短89%;
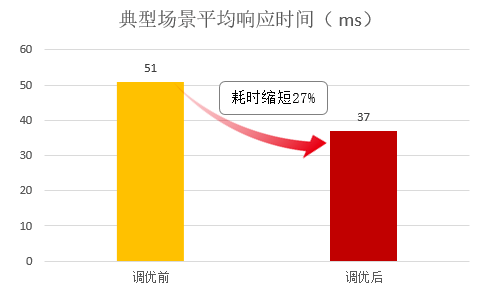
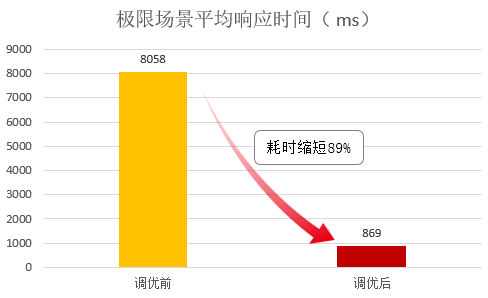
【模型查询业务平均响应时间对比】
模型查询业务的吞吐量在鲲鹏DevKit优化后也整体提升了30%。
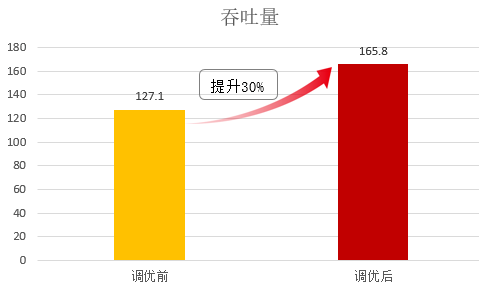
【模型查询业务吞吐量对比】
此外,数据集检索、数据集上传、模型训练等业务的综合性能均得到明显提升。轩辕研究院在进行鲲鹏原生开发过程中,通过鲲鹏DevKit优化了DataLab平台数据处理能力,有效提升了违章建筑检测的查询速度,同时也让GIS领域的科研工作更加便捷和高效。
轩辕研究院的AI科学计算平台DataLab能够在地理遥感、生物医药、地球科学、工业互联网以及社会科学等众多领域发挥重要作用,该方案已经在2021年鲲鹏应用创新大赛广东赛区斩获了金奖,成为2022年科研领域唯一入选鲲鹏精选解决方案。作为鲲鹏计算产业生态重要伙伴,轩辕研究院也与广州“鲲鹏+昇腾”生态创新中心建立了长期合作关系,后续也将持续基于鲲鹏原生开发实现科学计算领域的应用创新。
鲲鹏原生开发是指使用鲲鹏DevKit的原生开发能力,如鲲鹏开发框架(含场景化SDK)、编译调试工具、云测服务、调优&诊断工具等,在鲲鹏平台上开发新软件/新功能,充分发挥鲲鹏架构优势,从而获得开发效率/运行性能提升。
未来,鲲鹏DevKit将持续增强开发体验、优化工具能力,提升鲲鹏开发效率,促进千行百业数字化转型。
来源:至顶网人工智能频道
好文章,需要你的鼓励


Google Messages 2026年6月最新功能更新汇总
谷歌Messages近期推出多项新功能:长按消息或图片将弹出悬浮菜单,背景模糊并触发触觉反馈;已读回执移至消息气泡右下角圆圈内,左滑查看时间戳和加密标识,右滑可快速回复;苹果iOS 26.5支持端对端加密RCS,安卓与iPhone用户间的消息实现全程加密;智能回复新增"点击后先填入输入框"选项,减少误发;已删除对话将在回收站保留30天后才彻底清除。

AI机器人真的“看懂“数字了吗?西北大学等多校联合研究揭开视觉语言模型的空间盲区
研究揭示当前主流视觉语言模型无法真正理解空间中的数字含义,18个模型测试成绩普遍接近随机猜测,并系统分析了失败原因与改进方向。

Mozilla数据合作社:以信任为基础重构AI数据经济
Mozilla数据协作组织致力于解决生成式AI的数据困境。该组织由Mozilla基金会提供1000万美元初始资金,于去年11月正式成立,旨在建立一个以社区所有权、用户同意和公平价值交换为核心的AI数据市场。平台现已收录逾300种语言的精选数据集,覆盖阿富汗哈扎拉语文学、喀麦隆马达语口述历史等稀缺资源。数据贡献者可自主决定数据使用方式,并获得完整收益,平台另收取基础设施费用。

西交利物浦大学联手香港中文大学:用“信息几何“给AI安全装上“地震仪“
这项研究提出用费舍尔信息矩阵谱范数衡量深度神经网络的内在脆弱性,无需发动对抗攻击即可评估模型稳健性,并推导了VGG、ResNet、DenseNet和Transformer的理论排名。
2022
06/30
11:14
分享
点赞

Mozilla数据合作社:以信任为基础重构AI数据经济
毕马威因AI幻觉问题撤回智能体AI研究报告
iOS 27为iPhone主屏幕带来全新独立Siri应用
AI公司竞相上市,谁将搭上这班顺风车?
优化生成式AI与智能体AI成本的十大最佳实践
谷歌广告预告下一次Pixel Drop更新:屏幕反应与Gemini Omni功能即将到来
马斯克:SpaceX愿景是攀登卡尔达肖夫指数,我们必须去太空
Andrew Yang:降低生活成本是下一个创业大机遇
PeopleSoft零日漏洞波及数百机构,数十GB数据遭窃
Broadcom强化Spring安全体系,全力防御AI驱动的网络攻击
Apple Silicon大幅提升Mac整体拥有成本优势
iOS 27 新增多语言键盘支持及输入体验全面升级
