
Nature子刊发表!基于昇思MindSpore打造的AI+科学计算新成果PeRCNN面世
近日,华为与中国人民大学高瓴人工智能学院孙浩教授团队合作,基于昇思MindSpore AI框架提出了物理编码递归卷积神经网络(Physics-encoded Recurrent Convolutional Neural Network,PeRCNN),该成果已在《Nature》子刊《Nature Machine Intelligence》上发表,相关代码已在开源社区Gitee的MindSpore Flow代码仓开源[1]。
PeRCN相较于物理信息神经网络、ConvLSTM、PDE-NET等方法,模型泛化性和抗噪性明显提升,长期推理精度提升了10倍以上,在航空航天、船舶制造、气象预报等领域拥有广阔的应用前景。
PDE方程在对物理系统的建模中占据着中心地位,但在流行病学、气象科学、流体力学和生物学等等领域中,很多的底层PDE仍未被完全发掘出来。而对于那些已知的PDE方程,比如Navier-Stokes方程,对这些方程进行精确数值计算需要巨大的算力,阻碍了数值仿真在大规模时空系统上的应用。目前,机器学习的进步提供了一种PDE求解和反演的新思路。

PerCNN的模型架构
已有的数据驱动的模型依赖于大数据[2],这在大多数的科学问题上很难满足,同时还存在解释性的问题。物理约束的神经网络(PINNs)[3]虽然做到了利用先验知识去约束模型的训练从而减少对数据的依赖,但是PINN基于损失函数的软约束限制了最终结果的准确性。如何在缺少有效数据的情形下,得到具有高精度、鲁棒性、可解释性和泛化性的结果,仍是学界努力的方向。
因此,华为与孙浩教授团队合作,利用昇腾AI澎湃算力、依托昇思MindSpore AI框架开发了物理编码递归卷积神经网络[4],实现了对非线性PDE的精确逼近。
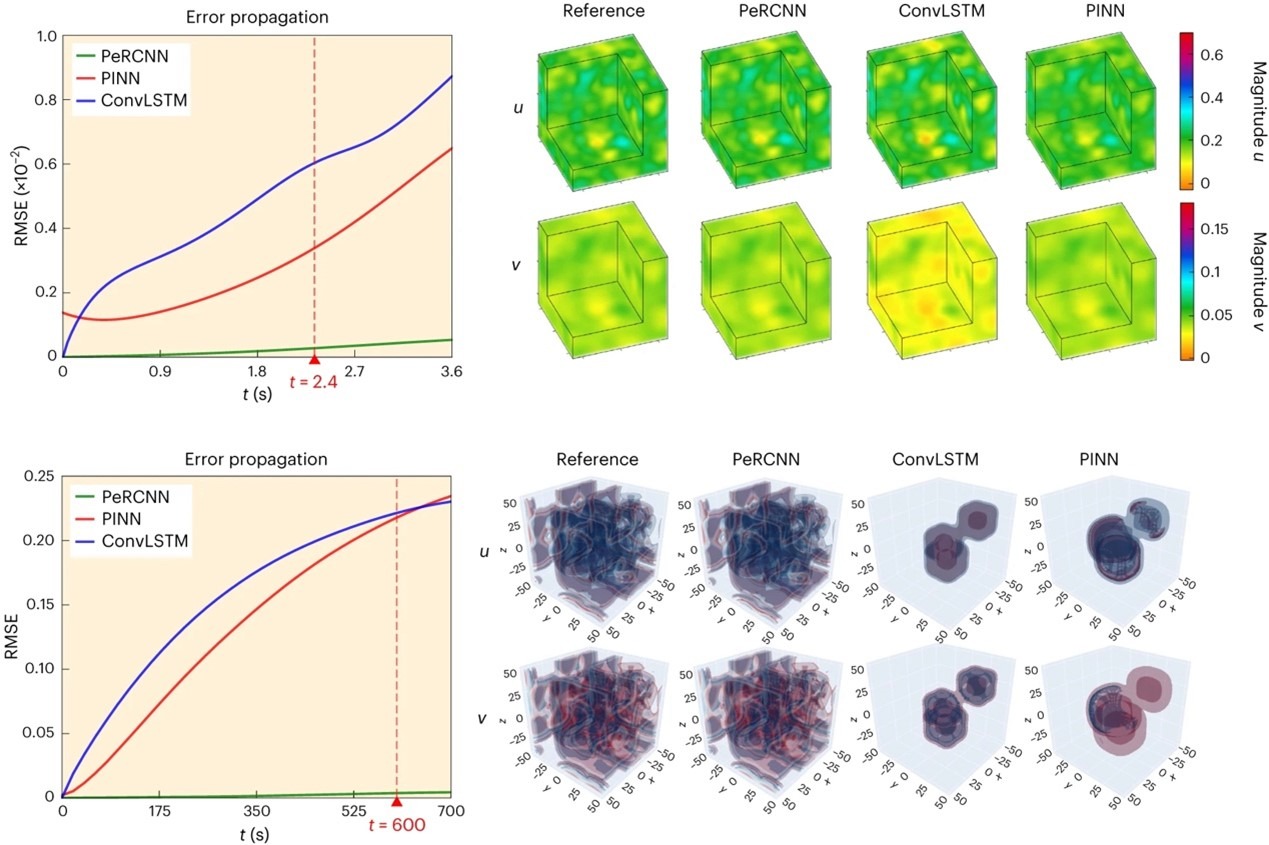
PeRCNN在反应扩散方程的应用,长期演化上优于ConvLSTM\PINN等方法
PeRCNN神经网络强制编码物理结构,基于结合部分物理先验设计的π-卷积模块,通过特征图之间的元素乘积实现非线性逼近。该物理编码机制保证模型根据我们的先验知识严格服从给定的物理方程。所提出的方法可以应用于有关PDE系统的各种问题,包括数据驱动建模和PDE的发现,并可以保证准确性和泛用性。
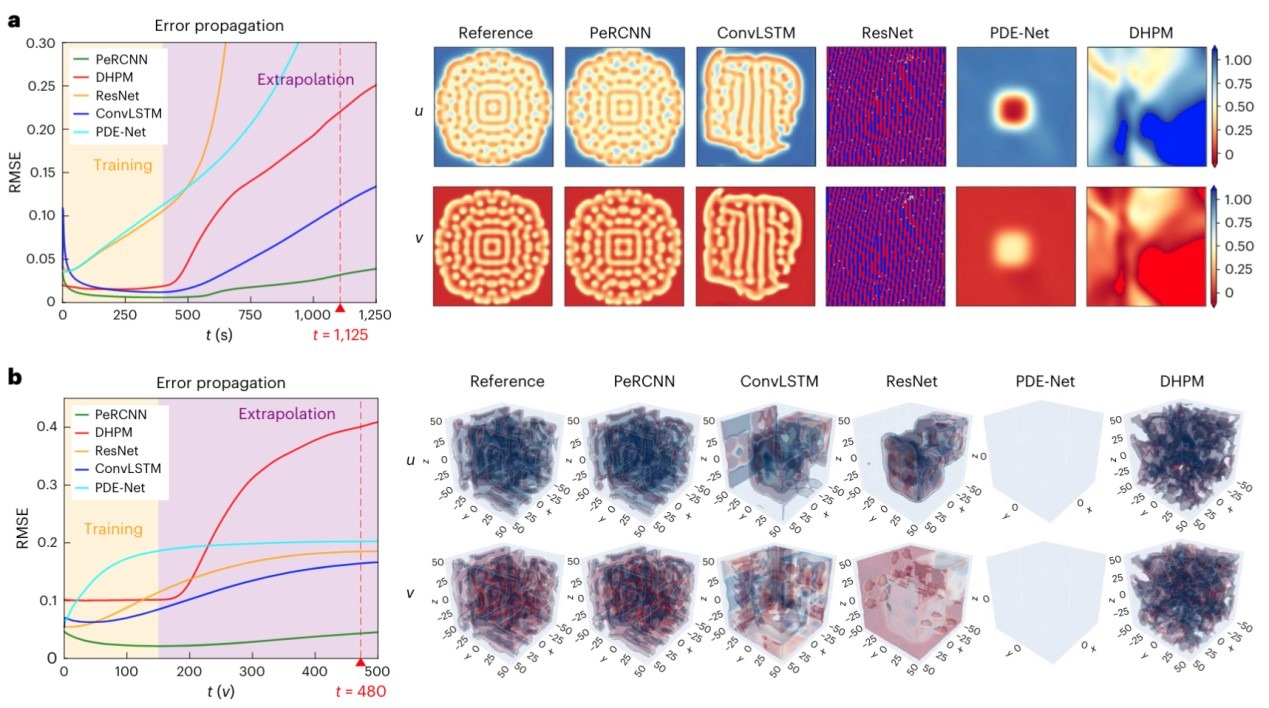
PeRCNN在预测和外推的性能上也优于ConvLSTM/ResNet/PDE-Net/DHPM等方法
PeRCNN的另一个独特优势是其可解释性,这源自π-卷积的乘法形式。通过符号计算,可以从学习到的模型中进一步提取底层的基础物理学表达式。这让PeRCNN能够作为一项有效的工具帮助人们从不完善和高噪声的数据中准确可靠地发现潜在的物理规律。
流体力学、气象、海洋等学科中,存在湍流、激波等强非线性现象,传统数值方法的求解需要大量计算资源,当前AI已经在飞行器流场、中期天气预报等问题中展现出极大的潜力,PeRCNN具备高精度、泛化性强和抗噪性强等特点,将有望在这些领域突破传统计算瓶颈,加速工业仿真和设计,成为AI+科学计算领域的新利器!
[1]https://gitee.com/mindspore/mindscience/tree/master/MindFlow/applications/data_mechanism_fusion/PeRCNN
[2]Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Nature, 521(7553):436–444, 2015.
[3]Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378:686–707, 2019.
[4]Chengping Rao, Pu Ren, Qi Wang, Oral Buyukozturk, Hao Sun*, Yang Liu*. Encoding physics to learn reaction-diffusion processes. Nature Machine Intelligence, 2023, DOI: 10.1038/s42256-023-00685-7
来源:至顶网人工智能频道
好文章,需要你的鼓励


OpenClaw 智能体正式登陆 iOS 与 Android 平台
开源AI智能体OpenClaw今日宣布正式推出iOS和Android应用。用户可通过手机连接OpenClaw Gateway路由层,调用AI智能体及其工具完成各类任务,涵盖编程、餐饮规划等场景。OpenClaw此前因MoltBook社交媒体实验走红,其创始人Peter Steinberger已于今年2月加入OpenAI。尽管MoltBook事件后来被揭露部分由真人假扮智能体,此次移动端上线标志着AI智能体正加速渗透日常生活。

当AI团队“各自为政“时,伊利诺伊大学如何用“梯度指纹“找出问题根源?
多智能体AI系统常因无法精准定位错误来源而难以优化,GBC通过梯度计算为每个AI的输出建立影响力评分,实现跨智能体的精细归因与针对性提示词优化。

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

香港大学与字节跳动联手:教机器人“看“人类动作来学习新技能,只需去掉那些令人头疼的旋转信息
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。
2023
07/25
11:11
分享
点赞

智引芯程,定义未来:德州仪器亮相 2026 慕尼黑上海电子展
“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
软件定义汽车时代:从“年”到“周”,研发团队如何高效驾驭复杂度?
美国消费品安全委员会拟出台电动自行车电池安全新规
昇思MindSpore 2.3全新发布 | 昇思人工智能框架峰会2024圆满举办
中国光谷·多模态人工智能大会暨多模态人工智能产业联合体第三次全体会议圆满召开
Nature子刊发表!基于昇思MindSpore打造的AI+科学计算新成果PeRCNN面世
WAIC2023最高荣誉SAIL奖揭晓!昇思MindSpore使能大模型、AI4S打造流体仿真重器
人工智能框架生态峰会2023·昇思MindSpore科学智能专题论坛顺利举办
人工智能框架生态峰会MindSpore TechDay成功举办,一起昇思,无尽创新
人工智能框架生态峰会2023顺利举办,助力产教融合,使能千百行业
人工智能框架生态峰会2023丨软通动力成为昇思MindSpore开源社区理事会首批成员单位
基于昇思AI框架的全模态大模型“紫东.太初2.0”正式发布
昇思MindSpore与产学界共同探索大模型&科学智能原生创新
