
马斯克展示Grok-1.5 Vision:多模态,能理解真实世界
与上一代1.0开源版本相比,Grok-1.5与GPT-4一样加入了Vision视觉功能可以深度理解真实世界,并进行数据解读、转换等。例如,给出一张蒙娜丽莎的图片,让其讲解该图片的来历以及故事等。
根据x.ai公布的测试数据显示,Grok-1.5 V的真实世界理解能力超过了GPT-4V、Claude 3 Opus 、Gemini Pro 1.5等知名多模态模型。
x.ai表示,Grok-1.5 V将很快向早期的测试者和现有Grok 用户推出。

Grok-1.5 V能力展示
用户可以向Grok-1.5 V发送一张图片,然后基于该内容进行文本问答。例如,让Grok-1.5 V解读一下职场非常有名的两张图片。

Grok-1.5 V:这张图是初创公司和大公司之间的幽默比较。在左侧,标有“初创公司”的标签上,有一群人正在一起挖坑。他们都在积极参与,坑已经相当深了。
在右侧,标有“大公司”的标签上,一群人站在一个洞周围。然而,与初创公司不同的是,实际上只有一个人在挖坑,而其他人则在观看或从事其他活动。
这张图片中的幽默来自于对初创公司和大公司之间差异的夸大。在初创公司中,通常会有一种紧迫感,每个人都被期望直接为手头的任务做出贡献。
相比之下,大公司通常被描述为官僚主义较多,所有团队成员对每个项目的直接参与较少。
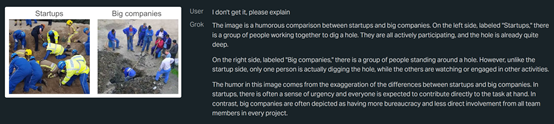
Grok-1.5 V基本很好的解读了这张图片的物理信息以及内涵的职场问题。
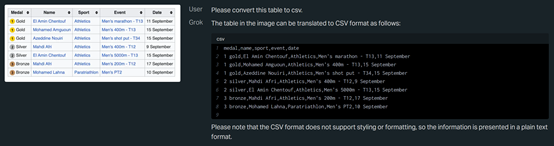
Grok-1.5 V不仅能解读信息,还能进行数据转换,例如,将一张表格转换成csv格式。
Grok-1.5 V也能将一张草图直接转换成真实的代码:你能把这张图片翻译成Python代码吗?
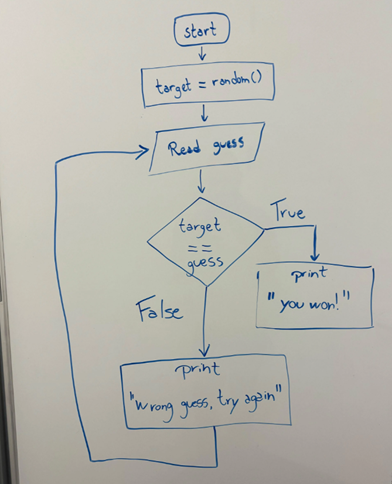
Grok-1.5 V:这个流程图描述了一个简单的猜谜游戏,其中计算机生成一个随机数,用户必须猜测它。下面是代表流程图中逻辑的 Python 代码。
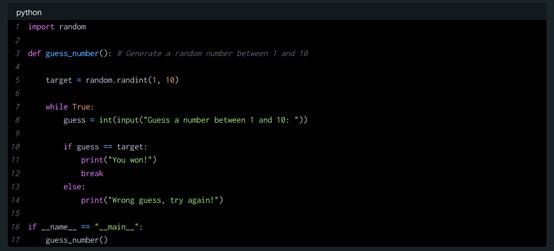
此代码将按照流程图中的描述运行猜谜游戏。系统将提示用户输入他们的猜测,直到他们猜出正确的数字。
Grok-1.5 V测试数据
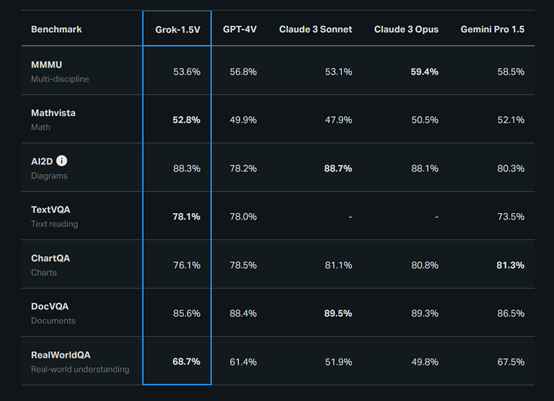
研究人员将Grok-1.5V在MMMU、Mathvista、TextVQA、RealWorldQA等知名测试平台中,与GPT-4V、Claude 3 Sonnet、Claude 3 Opus和Gemini Pro 1.5同类竞品进行了综合对比。
结果显示,Grok-1.5V的数学、图表理解、真实世界理解和文本阅读的能力高于其他模型。
此外,Grok-1.5还能处理更长、更复杂的提示,同时随着上下文窗口的扩大,仍能保持其指令跟踪能力。
在之前公布的 "大海捞针"(Needle In A Haystack,NIAH)评估中,Grok-1.5展示了强大的检索能力,可检索长度达 128K 字节的上下文中的嵌入文本,并取得了完美的检索结果。
来源:AIGC开放社区
好文章,需要你的鼓励


AI将在2030年前渗透所有IT工作——但不会取代所有IT岗位
Gartner预测,到2030年所有IT工作都将涉及AI技术的使用,这与目前81%的IT工作不使用AI形成鲜明对比。届时25%的IT工作将完全由机器人执行,75%由人类在AI辅助下完成。尽管AI将取代部分入门级IT职位,但Gartner认为不会出现大规模失业潮,目前仅1%的失业由AI造成。研究显示65%的公司在AI投资上亏损,而世界经济论坛预计AI到2030年创造的就业机会将比消除的多7800万个。

揭秘“CORA“:微软与谷歌联手打造的突破性多模态AI模型,让计算机真正“看懂“世界
CORA是微软研究院与谷歌研究团队联合开发的突破性AI视觉模型,发表于2023年CVPR会议。它通过创新的"区域提示"和"锚点预匹配"技术,成功解决了计算机视觉领域的一大挑战——开放词汇目标检测。CORA能够识别训练数据中从未出现过的物体类别,就像人类能够举一反三一样。在LVIS数据集测试中,CORA的性能比现有最佳方法提高了4.6个百分点,尤其在稀有类别识别上表现突出。这一技术有望广泛应用于自动驾驶、零售、安防和辅助技术等多个领域。

AI工厂引领产业变革:芯片巨头如何重塑计算基础设施
人工智能正从软件故事转向AI工厂基础,芯片、数据管道和网络协同工作形成数字化生产系统。这种新兴模式重新定义了性能衡量标准和跨行业价值创造方式。AI工厂将定制半导体、低延迟结构和大规模数据仪器整合为实时反馈循环,产生竞争优势。博通、英伟达和IBM正在引领这一转变,通过长期定制芯片合同和企业遥测技术,将传统体验转化为活跃的数字生态系统。

中国电信研究院首发T2R-bench基准:让AI从表格数据生成专业报告有多难?
中国电信研究院联合重庆大学、北航发布T2R-bench基准,首次系统评估AI从工业表格生成专业报告的能力。研究涵盖457个真实工业表格,测试25个主流AI模型,发现最强模型得分仅62.71%,远低于人类专家96.52%。揭示AI在处理复杂结构表格、超大规模数据时存在数字计算错误、信息遗漏等关键缺陷,为AI数据分析技术改进指明方向。
2024
04/16
00:05
分享
点赞

