
MiniGPT4-Video:让大模型分析视频内容,依然有难度 原创
Sora的发布,让文生视频成了过去几个月里最热门的一个话题,与此同时,行业里也涌现出了不少与视频内容分析相关的多模态大模型应用。
MiniGPT4-Video就是最近面世的与视频相关的多模态大模型应用之一。
该应用由KAUST和哈佛大学研究团队在今年4月发表的论文中提出,是一个专为视频理解设计的多模态大模型框架。

这一研究团队在论文中指出,在MiniGPT4-Video出现之前,行业中已经有诸多多模态大模型的研究项目,诸如MiniGPT、Video-ChatGPT等,但这些研究项目各有缺陷,例如Video-ChatGPT在对视频中内容进行转换过程中,往往会造成信息丢失,而且无法充分利用视频中的动态时间信息。
他们提出的MiniGPT4-Video是通过将每四个相邻视觉标记连接,减少了标记数量,同时也降低了信息损失对应用带来的影响。
与此同时,他们通过为视频的每一帧添加字幕,从而将每一帧表示为由视频编码器提取的视觉标记与由LLM标记器提取的文本标记的组合,这让大模型能够更全面地理解视频内容,从而同时响应视觉和文本查询信息。
众所周知,对于多模态大模型而言,数据最为关键。
据悉,为了训练MiniGPT4-Video,该研究团队用到了三个数据集:
第一个数据集是包含了15938个浓缩电影视频字幕的视频作为数据集(CMD),在这个数据集中,每个视频长度为1-2分钟;
第二个数据集是牛津大学发布的一个拥有200万视频量的开源数据集Webvid,为了和CMD数据保持一致,该研究团队将这一数据集中的数据也都裁剪到了1-2分钟;
第三个数据集是一个拥有13224个视频、100000个问答对话和注解的数据集,这个数据集中的数据质量很高,不仅针对视频内容提供了平均57个单词组成的问题答案,这些问题还涵盖多种问题类型,例如视频摘要、基于描述的QA,以及时间、空间、逻辑关系方面的推理。
由此研发出的这样一个MiniGPT4-Video模型,究竟能有什么用?
该研究团队在研究过程中,一共测试了MiniGPT4-Video三项能力:视频ChatGPT能力、开放式问题回答能力、选择题回答能力。
作为通过视频数据训练的多模态,MiniGPT4-Video最核心的能力其实是开放式问题的回答能力。
就这一能力,至顶网分别找了三个视频进行了实际测试——一个是由Pika生成的3秒煎肉视频、一个是42秒的机器人演示视频、一个是50秒的《老友记》节选片段。
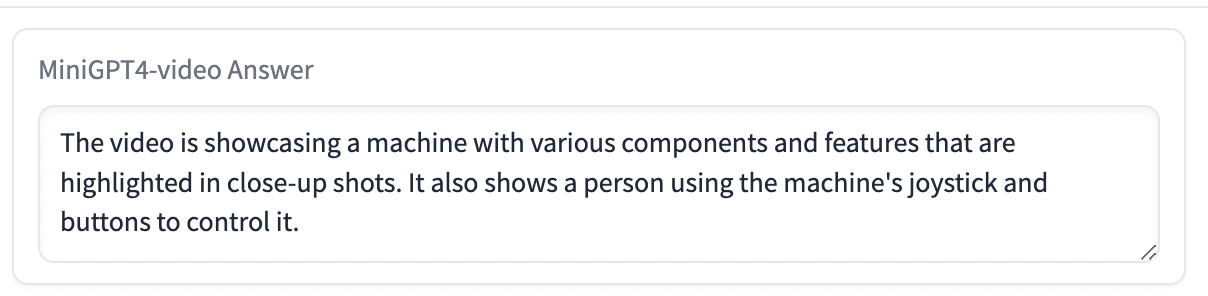
先说测试结果,将三个视频分别上传,并对MiniGPT4-Video进行提问——“这个视频谈了什么?”后,最终只有第二个视频给出了完整的答案,给出的答案与视频内容基本一致。
由此可见,现在的MiniGPT4-Video在做视频内容解析时,不仅对视频长度有要求,对视频质量同样有较高的要求,第二个视频之所以能有不错的输出结果,主要是因为视频内容逻辑性更强,而且有一些字幕介绍。

不过,针对第二个视频,我们就同一问题进行了多次提问,给出的答案并不一致,这是生成式AI的特性,第二次给出的答案还将视频中的机器人识别成了人,整体描述也出现了错误。
现在看来,MiniGPT4-Video在实际使用时,仍会存在各种各样的问题,还有待研究团队继续调优。
好文章,需要你的鼓励


米拉·穆拉提重返公众视野,谨慎发声
穆拉蒂时隔18个月首次接受重大媒体采访,介绍其创立的Thinking Machines Lab正在开发的"交互模型"。该模型能以200毫秒间隔处理音频、文本和视频流,捕捉人类交流中的中断、修正和停顿。她还谈及OpenAI"政变周"经历,强调行业决策权过于集中的担忧,并回应了公司近期研究人员离职问题,表示这是初创实验室的正常波动。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
本期《Quick Charge》播客涵盖多个热点话题:特斯拉疑似试图删除FSD欺诈相关证据以规避巨额赔付;卡特彼勒持续推进建筑领域电气化布局;住宅太阳能30%税收抵免即将到期。此外,嘉宾Tom Pacheco就高压系统与电池技术培训展开探讨,强调电动车技术人才培养的紧迫性。节目同时提醒有意安装太阳能的用户尽快行动,可通过EnergySage平台比较多家安装商报价。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。
2024
04/26
17:15
分享
点赞

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
智能体网络流量首超真人访问,"死亡互联网"理论引发新争议
Mentium Technologies Luna-R1 AI芯片入选ET-01星座任务,完成多星部署里程碑
汤道生×姚顺雨:腾讯AI下半场,拼的是“模型×产品”系统能力
AI驱动网络犯罪数量飙升,勒索软件受害者年增389%:Fortinet 发布2026年全球威胁态势研究报告
Inbolt将在Automate展会发布视觉驱动机器人编程新功能
笔记本电脑深度清洁指南:内外兼修焕然一新
加利福尼亚州城市通过全美首个由选民投票决定的数据中心禁令
柴油替代方案:AI数据中心如何利用燃气引擎与蒸汽涡轮供电
AI定义汽车时代,车载以太网可靠性面临全新挑战
安全算法的持续更新正变得愈发困难
轨道数据中心本质上是功能强化的卫星
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
