
LlamaIndex:如何为大模型加载一个AI知识库? 原创
大模型被喻为人类正在经历的一场科技革命,而横亘在大模型和实际业务场景之间的,是大模型在面对企业复杂业务场景时解决问题的能力,要具备这样的能力,数据是关键。
这其中需要的数据,不是通用大模型训练时用到的那些常见数据,而是与企业业务相关的数据,这些数据是大模型厂商在做模型训练难以触达的。
这就使得,当大模型真正进入实际应用场景中时,往往需要由企业再次提供这些数据进行再训练。
这些由企业提供的数据,往往又会构成一个本地数据库,这个数据库又可以被称为本地知识库。
LlamaIndex就是桥接大模型和本地知识库的一个神奇的框架。
给大模型“补钙”
自2022年11月ChatGPT一鸣惊人后,全球科技巨头都开始部署自己的大模型业务,大模型成了这个时代最性感的名词,也被认为是人类又一次颠覆式的科技革命。
那么大模型究竟从何而来?
众所周知,人类对人工智能技术的研究由来已久,大模型是人工智能技术研究中的一个分支,而大模型的本质是大数据、大算力。
大算力自不必提,就大数据而言,ChatGPT在训练过程中,使用的数据普遍源于互联网上的公开数据,例如维基百科、媒体文章、网上问答、开源社区等中的数据。
OpenAI团队基于这些公开数据对模型进行训练后,就让ChatGPT具备了摘要生成、文本生成、问答对话这些最基本的能力,这也是为什么ChatGPT最早的商用尝试,是被微软集成到了Bing中,用户优化搜索引擎。
不过,这样的通用大模型,只是拥有了互联网意义上的通用,在解决个人或企业遇到的实际问题时,现有大模型的能力依然有些捉襟见肘。
为了解决大模型在进入实际业务场景中的问题,就需要对给大模型“补钙”,目前行业中最流行的有三种方法:
第一种方法是提示词工程,这一方法是在已经训练好的大模型上,通过输入你想要查询内容的上下文,让大模型运行补充一定的语境,然后通过编写高效、准确的prompt,让大模型输出更精确的答案。

这种方法不仅对工程人员编写提示词的要求很高,也要求大模型拥有足够强的长文本输入和解析能力,这也是为什么大模型厂商都在增强自家大模型的长文本能力的原因之一。
第二种方法是微调,也就是我们常说的Fine Tuning,是在已经预训练好的大模型上,使用特定的数据集进行二次训练,使模型适应特定任务或领域。
这种方法目前也存在诸如对计算资源要求高、偏差容易被放大、易遭受对抗性攻击,甚至会导致“灾难性遗忘”等问题。
第三种方法就是RAG,是在原有大模型应用流程中,加入本地知识库,通过本地知识库的引入,补充大模型专业能力上的不足。
LlamaIndex就是通过第三种方法来让大模型具备进入企业实际应用场景中的落地能力。
为大模型加载AI知识库
在LlamaIndex框架下,该团队一共构建了三个关键组件,分别是:数据连接器、数据索引、查询接口。
这三个关键组件也是LlamaIndex将个人或企业的本地知识库“加载”到大模型中的三个主要步骤。
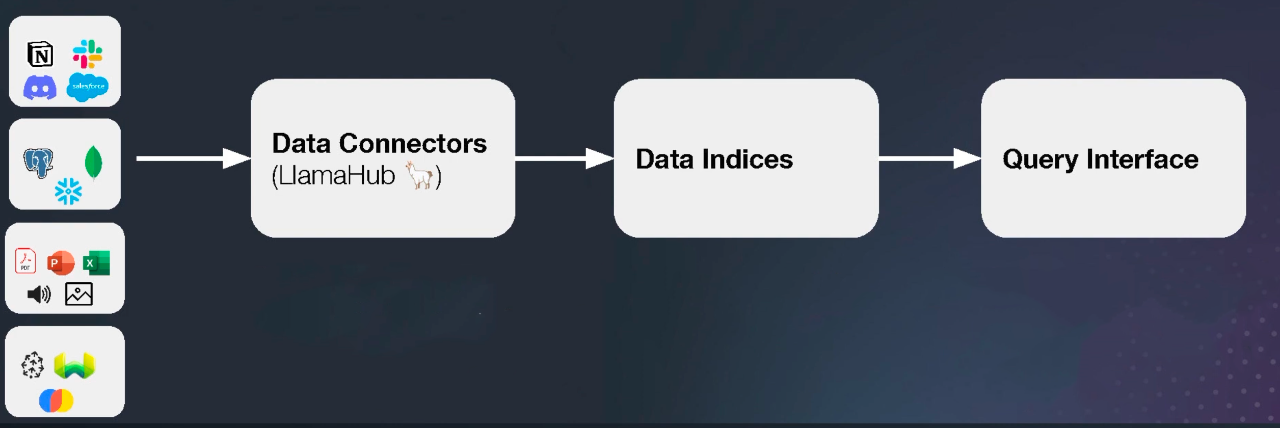
首先,第一步是通过数据连接器(LlamaHub)解决以往机器学习中数据清洗和数据治理的问题。
目前LlamaHub支持160多种数据格式,通过LlamaHub将这些数据形成一个Document对象列表,或是一个Node列表,并将这个列表与大模型关联起来。
第二步是通过数据索引来解决的是为不同应用场景调整数据结构的问题。
通过LlamaHub形成Document对象列表后,通过数据索引组件,构建一个用于补充查询策略、可供大模型查询的索引,例如构建成现在较为常见的向量索引。
值得一提的是,LlamaIndex现在可以将不同类型的数据统一加工成结构化数据,供大模型后续进行调用、训练和学习。
第三步是通过查询接口输入prompt和接收经过知识库后生成的结果。
通过这三个关键组件,LlamaIndex为大模型和本地知识库搭建了一条连通桥梁,为行业大模型或私有大模型提供了一条简单构建路径。
好文章,需要你的鼓励



泰国SCBX公司首次攻克:让AI聊天机器人秒懂泰语对话结束时机
泰国SCBX公司研究团队首次针对泰语开发了语义对话结束检测技术,通过分析文字内容而非声音停顿来判断对话是否结束。研究比较了多种AI模型方案,发现微调的小型变压器模型能在110毫秒内做出准确判断,显著优于传统静音检测方法。该技术能识别泰语特有的句尾助词等语言特征,为银行客服、智能家居、教育等场景的语音交互系统提供了更自然流畅的解决方案。

Sora 2应用向美国等地用户全面开放,无需邀请码
OpenAI推出全新Sora应用,打造完全由AI生成视频的社交媒体平台。美国、加拿大、日本和韩国用户现可直接下载使用,无需邀请码,但该开放政策仅限时提供。其他地区用户仍需等待更广泛的开放或通过Discord等渠道获取邀请码。用户可使用ChatGPT账户登录,立即开始观看、分享和创建AI视频内容。

浙江大学提出全新AI代理评测框架:让机器人自己出题考自己,开启智能评估新时代
浙江大学研究团队提出Graph2Eval框架,这是首个基于知识图谱的AI代理自动化评测系统。该框架通过知识图谱持续生成新测试任务,解决传统固定数据集评估的局限性。框架支持文档理解和网页交互两类任务,构建了包含1319个任务的测试集。实验验证显示该方法能有效区分不同AI系统能力,为AI代理评估开辟新路径。
2024
05/28
19:29
分享
点赞

Sora 2应用向美国等地用户全面开放,无需邀请码
Perplexity与Getty Images签署多年许可协议,应对版权争议
AWS业绩超华尔街预期,云基础设施需求持续旺盛
德州核电数据中心合作项目启动,计划2031年投产
高通骁龙X Elite和X Plus笔记本芯片详解
众智有为 致敬同路人|四川赛狄:从“碰撞”到“同路”,一位华为同路人的蜕变之旅
亚马逊股价大涨,AWS云业务增长加速
Microsoft 365 商业客户无处躲避 Copilot 功能扩张
Google Chrome推出AI操作按钮对抗AI浏览器
下一代云服务器将在1.7万英里高空轨道运行的原因
美国能源部联手Nvidia、AMD与Oracle打造四台强大AI超级计算机
面向未来的AI芯片技术发展之路
DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮
QwQ-32B模型成本地部署福音,通义App可第一时间体验
入局智驾的印奇,看到了怎样的未来?
成本打到6万以下,手把手教你用4路锐炫显卡+至强W跑DeepSeek
千里科技亮相吉利AI智能科技发布会,共启“AI+车”新纪元
天翼云CPU实例部署DeepSeek-R1模型最佳实践
京东云与宝德计算战略签约,共绘分布式存储与智算新未来
全球AI顶会AAAI 2025 在美开幕,产学研联手的“中国队”表现亮眼
蚂蚁数科提出创新跨域微调框架ScaleOT入选全球AI顶会AAAI 2025
国产软件再破记录!阿里云PolarDB数据库登顶TPC-C双榜第一
