
人工智能领域再添中国力量,阶跃星辰联合吉利贡献开源大模型
2025年2月18日,阶跃星辰和吉利汽车集团联合宣布,将双方合作的阶跃两款Step系列多模态大模型向全球开发者开源。其中,包含目前全球范围内参数量最大、性能最好的开源视频生成模型阶跃Step-Video-T2V,以及行业内首款产品级开源语音交互大模型阶跃Step-Audio。即日起可在跃问APP内体验。
阶跃星辰是吉利汽车集团的科技生态战略合作伙伴。在两款大模型的研发过程中,双方展开了深度合作,在算力算法、场景训练等领域优势互补,显著增强了多模态大模型的性能表现。此次联合开源的行动,旨在促进大模型技术的共享与创新,推动人工智能的普惠发展。这一举措也将为开源世界贡献最强的多模态大模型能力,形成大模型开源世界的又一股中国力量。
吉利汽车集团CEO淦家阅表示:“吉利致力成为智能汽车AI科技的引领者和普及者,早在2021年,吉利就围绕芯片、软件操作系统、数据和卫星网搭建了端到端的自研体系和生态联盟,构建了完善的‘智能吉利科技生态网’,驱动用户在智能驾驶、智能座舱上的体验不断进化。目前,吉利全栈自研的星睿AI大模型已经与阶跃Step-Video-T2V、Step-Audio等大模型完成了深度融合,将为用户带来更智能、更高阶的座舱交互与智驾出行体验,推动AI科技在智能汽车领域的普及。”
据了解,这也是阶跃星辰首次开源其 Step 系列基座模型。阶跃星辰创始人、CEO 姜大昕博士表示:“阶跃星辰一直以实现 AGI 为目标坚持研发基座大模型。我们深知 AGI 的实现离不开全球开发者的共同努力,开源的初心,一方面是希望跟大家分享最新技术成果,为开源社区贡献一份力量;另一方面,我们相信多模态模型是实现 AGI 的必经之路,但目前尚处于早期阶段,期待与社区开发者集思广益,共同拓展模型技术边界,并推动产业落地。”
阶跃Step-Video-T2V:性能领跑全球开源视频生成大模型
阶跃Step-Video-T2V 是目前全球范围内参数量最大、性能最好的开源视频生成大模型。阶跃Step-Video-T2V 模型的参数量达到 300 亿,可以直接生成 204 帧、540P 分辨率的高质量视频,这意味着能确保生成的视频内容具有极高的信息密度和强大的一致性。
从生成效果来看,阶跃Step-Video-T2V 在复杂运动、美感人物、视觉想象力、基础文字生成、原生中英双语输入和镜头语言等方面具备强大的生成能力,且语义理解和指令遵循能力突出,能够高效助力视频创作者实现精准创意呈现。用户可以在跃问网页端(https://yuewen.cn/videos)和跃问 App 上体验阶跃Step-Video-T2V 的视频生成能力 。
为了对开源视频生成模型的性能进行全面评测,阶跃星辰还发布并开源了针对文生视频质量评测的新基准数据集 Step-Video-T2V-Eval。该测试集包含 128 条源于真实用户的中文评测问题,旨在评估生成视频在运动、风景、动物、组合概念、超现实、人物、3D 动画、电影摄影等 11 个内容类别上质量。
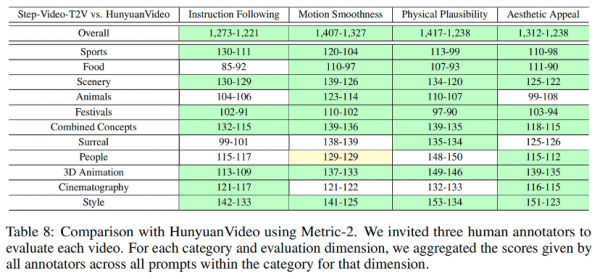
Step-Video-T2V-Eval评测结果
评测结果显示,阶跃Step-Video-T2V 的模型性能在指令遵循、运动平滑性、物理合理性、美感度等方面的表现,均显著超过市面上既有的效果最佳的开源视频模型。
据了解,目前在跃问网页端(https://yuewen.cn/videos)和跃问 App 上,都可以体验 阶跃Step-Video-T2V 的视频生成能力 。
阶跃Step-Audio:业内首款产品级开源语音交互模型
阶跃Step-Audio 是行业内首个产品级的开源语音交互模型,能够根据不同的场景需求生成情绪、方言、语种、歌声和个性化风格的表达,能和用户自然地高质量对话。模型生成的语音具有超自然、高情商等特征,同时也能实现高质量的音色复刻并进行角色扮演,满足影视娱乐、社交、游戏等行业场景下应用需求。
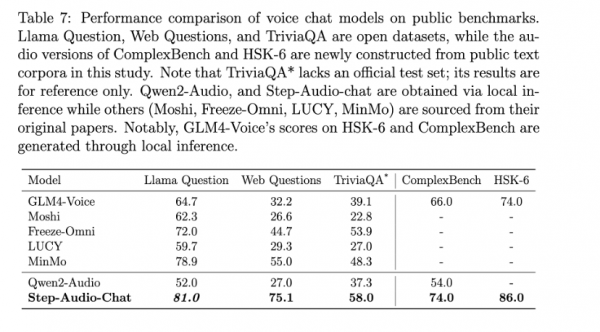
在 LlaMA Question、Web Questions 等 5 大主流公开测试集中,阶跃Step-Audio 模型性能均超过了行业内同类型开源模型,位列第一。阶跃Step-Audio 在 HSK-6(汉语水平考试六级)评测中的表现尤为突出,是最懂中国话的开源语音交互大模型。
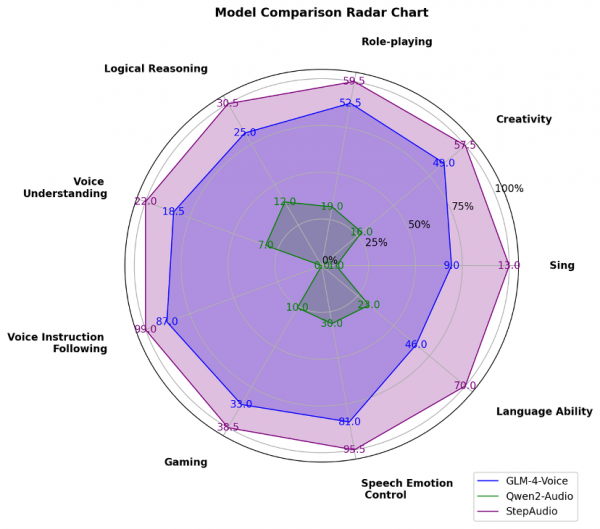
StepEval-Audio-360基准测试
此外,由于目前行业内语音对话测试集相对缺失,阶跃星辰自建并开源了多维度评估体系 StepEval-Audio-360 基准测试,从角色扮演、逻辑推理、生成控制、文字游戏、创作能力、指令控制等 9 项基础能力的维度对开源语音模型进行全面测评。通过人工横评后的结果显示,阶跃Step-Audio的模型能力十分均衡,且在各个维度上均超过了此前市面上效果最佳的开源语音模型。
好文章,需要你的鼓励


Glean年收入突破3亿美元,削减AI成本成核心卖点
企业AI搜索公司Glean宣布年度经常性收入(ARR)达3亿美元,较15个月前的1亿美元增长三倍。尽管谷歌、微软、OpenAI等科技巨头纷纷入局企业AI搜索市场,Glean凭借"上下文图谱"技术深度理解企业业务需求,并帮助客户显著降低AI计算成本。该公司提供按用量计费和混合定价两种模式,客户涵盖Databricks、Reddit、Pinterest及三星等企业。Glean上轮融资后估值达72亿美元。

香港中文大学与MiniMax联手破解AI图像描述的“说多错多、说少漏多“困局
香港中文大学与MiniMax提出ClaimDiff-RL框架,将图像描述的AI训练从整体打分升级为逐条核查,有效解决了传统方式导致AI"少说保平安"的问题,同时在多项基准测试上超越Gemini-3-Pro-Preview。

蓝色起源“新格伦“火箭在佛罗里达测试中发生爆炸
杰夫·贝索斯旗下的蓝色起源公司在佛罗里达卡纳维拉尔角进行静态点火测试时,新格伦重型火箭发生爆炸。这是美国历史上最大规模的火箭爆炸之一,也是蓝色起源公司遭遇的最严重失败。所有人员安全,但该事故可能导致新格伦火箭项目长期暂停。此前该火箭已成功完成三次发射,并实现了助推器回收和重复使用。

NTU、HKU等多所顶校联手,让AI同时“多角度看片“——视频理解的并行探针革命
ParaVT是一个由南洋理工等多校联合提出的并行视频工具调用框架,通过让AI同时分析多段视频并引入PARA-GRPO算法解决训练中的格式崩溃与工具跳过问题,在六项长视频理解测试中平均提升约7.9%。
2025
02/18
10:40
分享
点赞

Glean年收入突破3亿美元,削减AI成本成核心卖点
蓝色起源"新格伦"火箭在佛罗里达测试中发生爆炸
智能体AI正在重塑企业架构与Token经济学
堪培拉理工学院如何借助技术革新重塑课堂教学体验
Gemma 4携手Arm:优化端侧AI,加速移动应用体验
制药公司与初创企业如何携手推动AI落地
《星球大战》导演盛赞生成式AI:电影制作的革命性工具
Salesforce借助Informatica布局企业级无头数据管理架构
几乎所有M5 MacBook Air配置现在都降价近200美元
企业用好Agent,关键不在“买一个智能体”|原点Talk 分享会
大模型评测风向变了,Testin云测如何构建企业级AI质量标尺?
因民事养老金管理失误,英国政府拒绝向Capita授予5.63亿英镑合同
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
