
国内唯一,阿里千问斩获NeurIPS 2025最佳论文奖
11月27日,人工智能领域顶级会议NeurIPS 2025公布了论文奖,阿里通义千问团队在注意力机制上的研究成果从全球5524篇论文中脱颖而出,被评为最佳论文,是唯一获得该奖项的中国团队。该论文首次在业内揭秘了注意力门控对大模型性能和训练的影响,据悉,该研究成果已应用于Qwen3-Next模型,并显著提升模型的性能与鲁棒性。

阿里通义千问研究成果被评为NeurIPS 2025最佳论文
门控是大模型应用最广泛的技术之一,它可以作为模型的“智能降噪耳机”,帮助模型过滤无效信息从而提升模型性能。近年来,AlphaFold2、Forgetting Transformer等学术界和工业界模型开始探索将门控和注意力机制结合,但都对门控在注意力机制中有效的原因缺乏探索,也没有大规模实践的经验。
此次,通义千问团队通过在1.7B稠密模型(Dense)与15B混合专家模型(MoE)上训练超过 3.5 万亿 token,并对比 30 余组控制实验,首次清晰揭秘了其背后的原理,并展现了在注意力中使用门控形式最有效的方式及扩展成功实践。
注意力头是注意力机制中的基本计算单元。实验结果显示,对各注意力头的输出进行门控,是提升模型性能最有效的方式。使用该方式,在引入额外1%参数、计算开销增加低于2%的情况下,可以实现0.2以上的困惑度下降、MMLU基准评测2个点的提升。研究还发现,该技术还能在更大规模的模型训练上实现更好的性能。
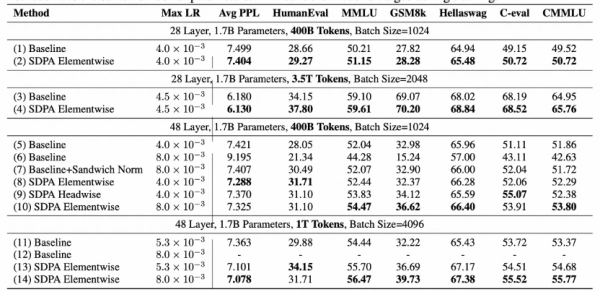
使用论文方法,在引入额外1%参数、计算开销增加低于2%的情况下,可以实现0.2以上的困惑度下降、MMLU基准评测2个点的提升
更深入的分析发现,注意力门控还解决了大模型长期存在的两大问题:注意力池(Attention Sink),即少量特殊token计算中产生很大的输出值、占据很高的注意力分数;巨量激活(Massive Activation),即模型激活中出现大于中位数数千倍的离群值。上述两个现象都容易在BF16等低精度训练中引发数值误差,影响训练稳定与低精度部署。该研究显示,门控注意力将首token的注意力占比从 46.7%降至4.8%,同时将最大激活值从1053降至94。
目前,该技术方案、实验模型及产品级模型均已开源。NeurIPS评审委员会表示:“我们认为该方法将被广泛采用,这项工作将极大推动社区对大语言模型中注意力机制的理解。”
通义千问团队表示:“对门控机制、模型机制等的深入理解,不仅为大语言模型架构设计提供了新思路,也为构建更稳定、更高效、更可控的大模型奠定了基础。”
据悉,目前阿里千问已开源300多款模型,涵盖全模态、全尺寸,全球下载量突破7亿次,衍生模型超过18万个,位居全球第一。
好文章,需要你的鼓励


Converge Bio融资550万美元,打造生物科技大语言模型“全能平台“
Converge Bio完成550万美元种子轮融资,由TLV Partners领投。该公司专为生物科技和制药行业打造LLM应用平台,提供数据增强、模型微调及可解释性分析等功能,帮助企业将通用生物基础模型转化为可实际落地的研发工具。以抗体研究为例,平台可将抗体LLM精调至氨基酸级别的结合亲和力预测,并生成优化序列。公司计划用于扩充团队、拓展客户,并发布抗体设计科研论文。

AI竟然能“感知“自己在扮演谁?香港大学揭开大模型社会角色的隐藏维度
香港大学与哈尔滨工业大学联合发布的这项研究(arXiv:2605.06196)发现,大语言模型在扮演不同社会层级角色时,内部神经网络存在一条清晰的"粒度轴",从普通个人视角延伸至全球机构视角。这条轴是AI角色空间的主导几何方向,可被测量、被跨模型复现,并通过激活引导技术加以操控,为AI社会模拟的可信度评估和角色视角的主动调控提供了新工具。

ChatGPT语音创造者创业,致力打造现实版“Her“中的AI语音技术
ChatGPT高级语音模式的创造者Alexis Conneau离开OpenAI后,创办了音频AI初创公司WaveForms AI,并获得由a16z领投的4000万美元种子轮融资。该公司专注于训练自有音频大语言模型,计划于2025年推出与OpenAI、谷歌竞争的AI音频产品。Conneau深受电影《Her》启发,致力于开发具备情感感知能力的语音AI,同时警惕AI伴侣化带来的社会问题,强调技术应服务于人而非取代人际关系。

废话也能帮AI变聪明?华盛顿大学研究发现“乱码前缀“让AI推理能力大幅提升
华盛顿大学研究团队发现,在AI数学推理训练中,将随机拼凑的拉丁文占位词(Lorem Ipsum)添加到题目前,能帮助AI突破"全部答错、训练停滞"的困境,在多个模型上平均提升推理得分2.8至6.2分。研究揭示了有效扰动的两个关键特征:使用拉丁语词汇避免语义干扰,以及保持较低困惑度确保AI能正确理解题目内容。
2025
11/27
11:28
分享
点赞

Thinking Machines Lab发布能边说边听的AI交互模型
Opera浏览器支持本地下载运行大语言模型,超150款可选
Unify:帮助开发者找到最适合任务的大语言模型
Human Native AI:打造AI训练数据授权交易市场平台
Converge Bio融资550万美元,打造生物科技大语言模型"全能平台"
ChatGPT语音创造者创业,致力打造现实版"Her"中的AI语音技术
高带宽内存左移测试策略助力AI芯片良率提升
AI加速器测试依赖可测性设计创新
算法将驱动一切:边缘AI智能体如何重塑智能系统
人工智能、物联网与机器人技术在现代制造业中的融合
迪士尼+计划转型为集购票、购物、游戏于一体的"超级应用"
tvOS 26为Apple TV 4K新增五大自定义功能
