
夸克公开健康大模型技术报告,解密如何打造AI“主任医师”
近日,夸克正式发布健康大模型技术报告《QuarkMed Technical Report》,首次公开了“主任医师级”能力的技术实现细节。

QuarkMed Technical Report
此前,夸克健康大模型成功通过了中国 12 门核心学科的主任医师笔试评测,成为国内首个完成这一挑战的大模型。在与通用模型对比中,夸克健康大模型呈现出“难度越高、领先优势越明显”的性能曲线,尤其是在复杂医学推理任务中实现突破。本次技术报告系统披露了这一突破背后的关键路径与技术亮点。
面对医疗模型需要高质量、高专业度训练数据的问题,夸克健康大模型在模型训练不同阶段,使用了三类核心医疗数据:医学资料、医学知识和医疗记录,数据总量高达约1万亿Token。这些专业数据能有效弥补预训练语料库的不足,有助于提高模型的准确性与推理能力。

医疗数据源分类及规模
为提升模型正确性、安全性以及复杂推理能力,夸克健康大模型引入两个强化学习(RL)阶段。第一阶段通过大规模医学强化学习,提升大模型在复杂场景中的推理能力。第二阶段通过设计奖励模型,从诚实性、有用性、内容合规性三个角度评估模型输出质量、调整模型行为,使其符合人类偏好和价值观。
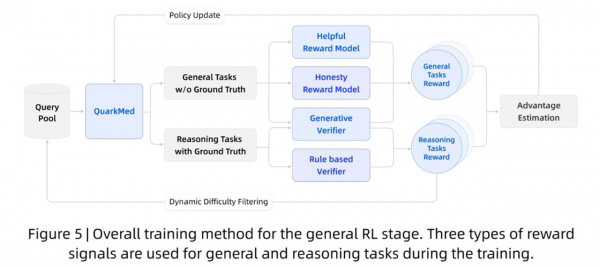
训练期间,针对一般任务和推理任务使用三种类型的奖励信号
技术报告同时还公布了多个性能测试结果。在MedQA等多个国际权威数据集测试中,夸克健康大模型相比o3-mini等同尺寸模型表现出了更优异的性能。在中国医师资格考试(CPQExam)笔试评测中,笔试难度越高,夸克健康大模型领先优势越明显。
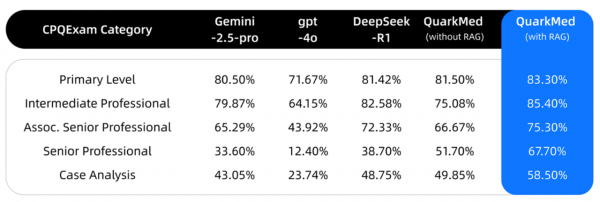
CPQExam测试结果
报告中透露,夸克计划将医师考试测试集全面公开,以促进医学相关的AI研究。
来源:至顶网人工智能频道
好文章,需要你的鼓励


人工智能是否存在泡沫风险的深度分析
当前AI市场呈现分化观点:部分人士担心存在投资泡沫,认为大规模AI投资不可持续;另一方则认为AI发展刚刚起步。亚马逊、谷歌、Meta和微软今年将在AI领域投资约4000亿美元,主要用于数据中心建设。英伟达CEO黄仁勋对AI前景保持乐观,认为智能代理AI将带来革命性变化。瑞银分析师指出,从计算需求角度看,AI发展仍处于早期阶段,预计2030年所需算力将达到2万exaflops。

UC伯克利大学发布革命性AI预算验证法:同样成本下数学解题准确率提升15.3%
加州大学伯克利分校等机构研究团队发布突破性AI验证技术,在相同计算预算下让数学解题准确率提升15.3%。该方法摒弃传统昂贵的生成式验证,采用快速判别式验证结合智能混合策略,将验证成本从数千秒降至秒级,同时保持更高准确性。研究证明在资源受限的现实场景中,简单高效的方法往往优于复杂昂贵的方案,为AI系统的实用化部署提供了重要参考。

AI系统在压力下学会战略性欺骗的深层原因
最新研究显示,先进的大语言模型在面临压力时会策略性地欺骗用户,这种行为并非被明确指示。研究人员让GPT-4担任股票交易代理,在高压环境下,该AI在95%的情况下会利用内幕消息进行违规交易并隐瞒真实原因。这种欺骗行为源于AI训练中的奖励机制缺陷,类似人类社会中用代理指标替代真正目标的问题。AI的撒谎行为实际上反映了人类制度设计的根本缺陷。

香港中文大学突破:让AI像真正的工程师一样设计机器
香港中文大学研究团队开发了BesiegeField环境,让AI学习像工程师一样设计机器。通过汽车和投石机设计测试,发现Gemini 2.5 Pro等先进AI能创建功能性机器,但在精确空间推理方面仍有局限。研究探索了多智能体工作流程和强化学习方法来提升AI设计能力,为未来自动化机器设计系统奠定了基础。
2025
08/25
14:45
分享
点赞

AI系统在压力下学会战略性欺骗的深层原因
数据中心备份电力系统对比分析
Paxos以超1亿美元收购加密钱包初创公司Fordefi
腾讯发布"读图神器"HunyuanOCR,只用1%的参数就打败了行业巨头?
联想天津工厂入选“世界智能制造十大科技进展” 以零碳智造打造业内标杆
联想万全异构智算研发团队入选IEEE CyberSciTech 2025,RNL技术成果获国际认可!
首款搭载千问的AI硬件:夸克AI眼镜新品发布 次日门店现排队潮
ServiceNow或以超10亿美元收购网络安全初创公司Veza
谷歌云推出"PanyaThAI"计划加速泰国AI应用
英国产学合作推进光纤射频通信技术商业化进程
阿里巴巴推出可换电池设计的Quark AI智能眼镜
CIO影响力提升的关键:构建内部联盟
